自己回帰モデルであるGemini、GPT、Claudeは、トークンを順次生成する仕組み上、本質的な遅延が避けられない。拡散モデルはシーケンス全体を並列生成することでこの課題を解決し、最大10倍高速な推論を実現する。Inception Labsが発表したMercury 2は、商用として初めて推論機能を備えた拡散型大規模言語モデルであり、ハードウェアではなくアルゴリズムによる高速化を達成している。本動画では、拡散モデルの仕組み、実際のデモ、ベンチマーク、そしてカスタマーサポートやRAGエージェントといった実用例を通じて、定型タスクにおける拡散LLMの可能性を検証する。
拡散モデルがもたらす推論速度革命
GeminiやGPT、Claudeといった自己回帰モデルは、シーケンシャルなデコーディングという仕組み上、どうしても遅延が生じてしまうんです。でも拡散モデルなら、シーケンス全体を並列に生成できるので、推論速度が最大10倍も速くなるんですよ。
その例として、昨年私が動画で取り上げたGemini Diffusionがあります。このモデルには早期アクセスする機会をいただきました。もう一つの例がByteDanceのSiD Diffusionで、こちらは拡散技術を使った大規模言語モデルなんです。どちらのモデルも、拡散ベースの大規模言語モデルが自己回帰モデルよりも優れた推論速度を示していますが、両方ともリサーチプレビューの段階でした。
拡散型大規模言語モデルの商用提供としては、昨年Inception Labsという会社が最初期の事例を示してくれました。彼らは自己回帰モデルと比べてより高速なレスポンスが得られることを実証したんです。昨年、彼らはMercuryとMercury Coderをリリースしました。そして今回、第2世代となるMercury 2をリリースするんですが、今回は思考モデル、つまり推論モデルなんです。
このモデルへの早期アクセスをいただいたんですが、特に生成速度という点で、この技術は本当に印象的でした。素晴らしいのは、これがハードウェアの最適化によるものではないという点なんです。これは完全にアルゴリズムから直接生まれた成果なんですよ。
この動画はInceptionのスポンサーですが、意見はすべて私自身のものです。
なぜテキスト生成に拡散モデルが有効なのか
拡散は画像や動画生成で広く使われています。でもテキストに関しても、実は拡散を使うのは理にかなっているんです。これを理解するには、自己回帰モデルの性質とその最大の制約を見る必要があります。
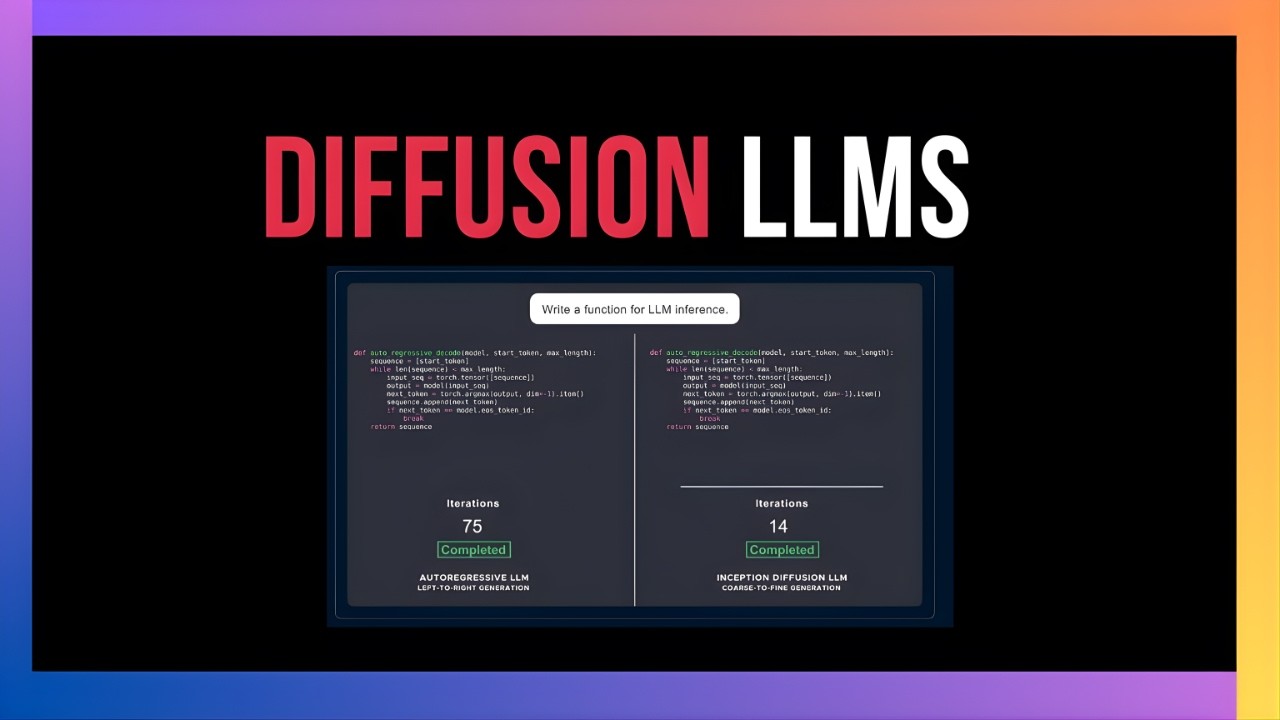
次のトークンを生成するたびに、利用可能なすべてのトークンの確率を見て、最も確率の高いものを選ぶ必要があるんです。これは逐次的なプロセスで、本質的に遅いんですよね。でももっと大きな問題があります。もしトークンの一つを間違えたら、戻って修正することができないんです。まるでタイプライターで作業しているようなもので、すべてのミスが永続的なんです。
一方、拡散はノイズから始まって、反復ごとにシーケンス全体を生成していきます。だから途中で間違いを犯しても、その特定のトークンを修正する能力があるんです。そしてその過程で、はるかに高速な推論が得られるわけです。これはテキストエディタのようなもので、時間を遡って間違いを修正できるんです。
Mercury 2の実演デモ
いくつか簡単なデモをお見せしてから、実世界で高速な推論速度が実際に役立つと感じた実用的なアプリケーションをいくつかご紹介しますね。
これが使用するインターフェースです。2つの異なる推論モードがあります。一つはインスタントモードで、これは思考を無効にします。もう一つはハイモードで、思考モードを使用します。
API側では、3つの異なるレベルの思考または推論努力を設定できます。ロー、ミディアム、ハイに設定できるんです。また、これは明確に定義されたタスクを持つエージェント的な用途に最適です。ウェブ検索を有効にすれば、ツールとしてウェブ検索を使用できます。その例もいくつかお見せしますね。
いくつかテストを実行しますが、その前に他のモデルとの速度比較をお見せしたいと思います。GPT-4o miniインスタントを選択します。これは同クラスのモデルなので。Mercury 2ではハイ推論努力を有効にします。
試したいプロンプトは、ピースが下ではなく上に進むテトリスゲームです。そして単一のHTMLファイルにしてほしいんです。まずGPT-4o miniインスタントを起動してから、Mercury 2に送信します。
拡散モデルの場合、最初のトークンまでの時間が比較的遅くなることがあります。しかし、もう完全なゲームを生成しています。GPT-4o miniインスタントはまだコードを書いている最中です。
特定のエージェント的な用途では、この生成速度が極めて重要になります。特にリアルタイムシステムを構築したい場合にはね。両側で実装が完了しました。これを見てみましょう。こちらは問題なく動作しているようで、聞かずに開始しました。これも起動できますね。
ブロックの動きをコントロールできます。両方とも全く同じことをしているようですね。でもコード生成の速度には大きな違いがあって、これがリアルタイムアプリケーションで重要な役割を果たすんです。ただし、これはフロンティアモデルではないことを覚えておいてください。これは私が言うところのワークホースモデルなんです。明確に定義されたタスクに使いたいモデルですね。
指示追従能力のテスト
次に、モデルの指示追従能力をテストします。このケースでは、次の文が前の文よりも正確に1語長くなる短編小説を書くよう求めています。2語の文から始めて、20語の文になるまで続け、その後2語に戻していくんです。
これは興味深いタスクになりますね。拡散エフェクトを有効にして、テキストがどのように生成されるか実際に見られるようにします。まずはインスタントモードでテストしたいと思います。インスタントモードは非常に素早い結果をくれます。
3語で始まって、次は4語、5語、そして…うーん、筋を見失ったみたいですね。でもこういうのには、ハイ推論努力が必要なんです。ハイに設定します。もう一度これを送信しますね。
ハイ推論努力では、最初のトークンまでの時間はインスタントモードほど速くありませんが、レスポンスの生成を始めると、かなり速いんです。このケースでは、2語で始まり、3語、4語、5語となっていますね。そして実際にかなり一貫性があります。
これが20語の文で、そこから19語に減っていきます。指示に従えるだけでなく、ストーリーを一貫性のあるものに保ち、最後には2語になる。これは本当に印象的ですね。
別のテストがあります。最初の25匹のポケモンを含むHTMLファイルを作成するよう求めています。これをインスタントに設定すると、結果は即座に得られますが、画像が欠けています。
同じプロンプトでハイ推論努力を使うとどうなるか。これですべて正しく取得できています。このかなり洗練されたアニメーションも追加されていて、とても素敵ですね。コーディング関連のタスクには、インスタントではなくハイ推論努力を使いますね。
ウェブ検索ツールの活用
ウェブ検索ツールを使う能力もあります。何か聞いてみましょう。なぜOpenAIはPeter Steinbergを雇ったのか?
ウェブ上のさまざまなリソースを実際に調べて、レスポンスをくれる必要があります。OpenAIはオープンソースAIエージェントOpen Cloudの創設者であるPeter Steinbergを雇い、パーソナルおよびマルチエージェントAIの開発を加速させたと言っています。
ウェブ検索ツールを使えるだけでなく、実際に何が起こったかについて包括的なレスポンスをくれているようですね。
トレーニングデータにこれがあるとは思えないので、ウェブ検索を無効にしてみます。もう一度実行してみましょう。カットオフ日は2025年1月のようです。そして今のレスポンスは、OpenAIがPeter Steinbergを雇用したという公式発表は知らないというものです。
これはいいですよね。ウェブ検索ツールが使えるんです。
実用アプリケーション例:音声アシスタント
Mercury 2を中心に構築したいくつかのアプリケーション例をお見せしましょう。この推論速度とエージェント的機能、推論能力が極めて有用だと感じたものです。
この例では音声アシスタントを見ています。カスタマーサポートエージェントだと考えてください。ここで起こることはすべてリアルタイムで、テキスト生成とオーディオ生成の速度に特に注目してほしいんです。
店舗の営業時間について教えてもらえますか?
これは私が構築しているアプリで、音声をテキストに非常に速く文字起こしできるんです。でも残りのバックボーンはMercury 2によってレスポンス生成が動いていて、そしてCartesiaのNovaモデルがテキスト音声変換に使われています。
Techvaultは月曜から金曜は東部時間午前9時から午後8時まで、土日は東部時間午前10時から午後6時まで営業しています。他に何かお手伝いできることはありますか?
これは完全にリアルタイムでしたよね。ほぼ即座でした。店舗にはどんな製品があるんですか?
ヘッドフォンからPro WirelessやStudio Monitorモデルまで、さまざまな電子機器を取り扱っています。何か気になるものがあれば教えてください。
音声アクティビティ検出と割り込み機能を追加すれば、実際のカスタマーサポートエージェントとして使えることが想像できますよね。
実用アプリケーション例:RAGエージェント
2つ目の例は、文書から情報を抽出する検索拡張生成エージェントです。これは私のオープンソースプロジェクトで、エージェント的なファイル検索と、埋め込みを使った従来の意味ベースの類似性検索を組み合わせたものです。
契約書によると購入価格はいくらですか、というような質問をしてみましょう。このデータには買収契約関連の文書が含まれています。実行してみます。
エージェントが2つの呼び出しを行えることがわかりますね。まず意味的類似性を調べ、次に特定の文書を見つけました。この全体で完了するのに約4秒かかりました。
他のモデルを使うと最大20秒かかることもあるので、これはかなり素晴らしいですね。エージェントが複数のツール呼び出しを順次行わなければならない、かなり複雑なシステムなんです。同じ質問に対して、Gemini 2.0 Flashは合計約17秒かかっています。
Gemini 2.0 Flashは間違いなくはるかに高機能なモデルですが、非常に明確に定義された用途においては、Mercury 2ははるかに高速な推論速度を考えると、同等に有用です。明確に定義されたタスクのためのワークホースモデルとして考えてください。推論を使えるモデルですね。
ベンチマークと性能評価
ベンチマークについて話しましょう。Mercuryの前回のイテレーションからのベンチマークと、Mercury 2について提供されたベンチマークを取得しました。このモデルをClaude 3.5 Haiku、GPT-4o mini、Gemini 2.0 Flashといったモデルと比較しています。
彼らは本当にワークホースカテゴリーのモデルに焦点を当てているんです。これらは明確に定義されたタスクで常に実行したいモデルで、目標は妥当な価格で実行することなんです。
Mercuryの新しいイテレーションは、これらの主要なベンチマークで最先端か、最先端に近い性能を示しています。推論が役立つエージェント的アプリケーションでの使用を想定して設計されているんです。
でも最も重要なのは、Mercury 2を毎秒1,000トークンで実行できるようになったことで、これはMercury Coderモデルの以前のイテレーションと一致していますが、今回は推論モデルなんです。
毎秒1,000トークンに達する自己回帰モデルもありますが、CerebrasやGrokのような特殊なハードウェアが必要になります。でもMercuryの速度は完全に異なるモデリングアプローチから来ているんです。そして生成速度は、特に時間や遅延に敏感なアプリケーションにおいて重要なんです。
価格設定と実用性
ワークホースモデルにとって、価格設定は非常に重要です。これにより、非常に競争力のある価格で推論ベースのエージェント的使用が可能になります。実際、彼らは価格を100万出力トークンあたり1ドルから75セントに引き下げました。
コンテキストウィンドウは128,000トークンです。そしてこれは推論をサポートする初めての拡散型大規模言語モデルなんです。
エージェント的アプリケーションで使いたいワークホースモデルとして、非常に競争力のある選択肢になると思います。とにかく、チェックしてみてください。
拡散LLMは新しい技術ですが、自己回帰モデルに急速に追いついています。これが未来なのか? まだ結論は出ていません。
とにかく、この動画が役に立ったことを願っています。ご視聴ありがとうございました。いつものように、次回またお会いしましょう。


コメント