ニューラルネットワークの根本的な課題は時間概念の欠如である。従来のフィードフォワードネットワークは各入力を独立して処理し、文脈や記憶を持たない。この問題を解決するために登場したのがリカレントニューラルネットワークであり、その進化の過程で様々なアーキテクチャが生まれた。初期のバニラRNNは過去の状態を伝播させる仕組みを持ったが、長期依存関係の学習に失敗した。ブレークスルーとなったのは、選択的に情報を保持・破棄できるゲート機構の導入であり、これによりGRUやLSTMといった実用的なアーキテクチャが実現された。
ニューラルネットワークの根本的な欠陥
驚異的な力を持つ人工ニューラルネットワークですが、ほとんどのものには根本的な欠陥があります。それは時間の概念を持たないということです。
ここにあるネットワークを見てください。これはAlexNetです。2012年に発表されたとき、AI史のターニングポイントとなりました。AlexNetは一つのことだけのために構築された深層ニューラルネットワークです。それは見ることです。画像を入力すると、1000個の確率のリストを吐き出し、画像に何が写っているかを教えてくれます。
例えば、この画像を見せると出力ニューロンが発火します。ほとんどは無音で、ゼロに近い値ですが、リストの29番目のニューロンが1に近い値で光ります。クラス29を調べてみると、確かにアホロートルを表しています。見事です。
しかし、映画を分析したい場合はどうでしょうか。単純なアプローチは、一度に1フレームずつ入力して予測を見ることです。
しかし、この方法には深刻な欠陥があります。各分析は他のものと完全に独立しています。ネットワークには記憶も文脈もありません。実際、映画のフレームを完全にランダムな順序にシャッフルしても、ネットワークは気づきもしません。それは逆行性健忘症の極端なケースを持つ専門家のようなものです。画像に何があるかを教えてくれますが、その画像が消えた瞬間、その存在を忘れてしまいます。
これは大きな問題です。なぜなら、私たちの脳はそのように働いていないからです。映画を見るとき、現在のフレームに対する私たちの知覚は、直前に見たフレームによって深く形作られています。私たちは文脈を構築し、次に何が来るかを予測し、時間の矢を理解します。
では、同じことをするニューラルネットワークをどのように構築すればよいのでしょうか。機械に記憶をどのように与えればよいのでしょうか。それがリカレントニューラルネットワークの背後にある動機です。シーケンスの概念をその構造そのものに焼き込んだ機械です。
ニューラルネットワークの基本構造
しかし、時間を機械に組み込む方法を理解するには、まずネットワーク自体の明確な全体像を把握する必要があります。では、古典的なニューラルネットワークについて非常に簡単におさらいしましょう。
ニューラルネットワークの基本構成要素はニューロンです。それを小さな証拠蓄積マシンと考えることができます。入力信号を受け取り、それぞれに対応する重みを掛け、すべてを合計して内部状態を構築します。細胞膜を横切って電圧が蓄積されるようなものと考えてください。ここに計算が存在します。
しかし、ニューロンは電圧の数値を隣接するニューロンに直接伝達するわけではありません。代わりに、その内部状態をスパイク列、つまり他のニューロンに送られる明確な電気パルスのシーケンスに変換します。
これを数学的に抽象化したものが活性化関数σです。内部状態を受け取り、実際に下流に送られる信号にマッピングします。典型的には、閾値ゲートのように見えるかもしれません。正の数だけを通過させ、負の値をゼロに押しつぶします。
しかし、ニューロン単体では実際にはあまり役に立ちません。有用な計算を可能にするために、これらのニューロンの何千もが層に組織化されます。特定の層のすべてのニューロンは、前の層から入ってくるまったく同じ信号を見ますが、ただ重み付けが異なります。
すべてのニューロンについて数式を書き出すと、インデックスの悪夢になります。ここで線形代数の美しい省略記法が登場します。これにより、個々のニューロンについて考えることをやめ、層全体の状態について考え始めることができます。
隣接する任意の層のペア、層L-1と層Lを考えてみましょう。まず、層内のすべてのニューロンの内部状態を一つのオブジェクト、ベクトルにまとめます。その層のすべてのニューロンの内部圧力を表す数値の列と考えてください。
問題は、層L-1の状態が与えられたとき、H_Lをどのように決定するかです。さて、層Lは前の層の生の内部状態を直接見るわけではありません。それらの状態によって生成された信号を見ます。したがって、まず前の層が発火する必要があります。
前の状態に活性化関数を適用します。次に、信号が接続に沿って次の層に伝わります。層L-1のすべてのニューロンが層Lのすべてのニューロンに接続されているため、これらの重みは膨大な数値のグリッド、重み行列W_Lを形成します。
この行列は層のペアの配線図を表しています。この行列を入力信号に掛けると、新しい層のすべてのニューロンの重み付き和を同時に計算していることになります。これにより新しい内部電圧が得られます。
したがって、相互作用のウェブ全体が一つのエレガントな方程式に圧縮されます。古い内部状態を取り、σを通して信号に変換し、重み行列で配線を通して実行すると、新しい内部状態が確立されます。
これがフィードフォワードニューラルネットワークの基本公式です。これは情報の静的な一方向変換です。これらの層を多数重ねることで、画像のピクセルを手書き数字のラベルにマッピングするような驚くべきことができる機械を構築できます。
時間の導入
フィードフォワードネットワークのロジック全体を一つのエレガントな方程式で捉えました。発火して投影、発火して投影、層から層へ。しかし、それについて重要なことに気づいてください。新しい状態は、その前の層から入ってくる信号にのみ依存します。5分前に何が起こったかについての知識はありません。
そして、これがまさにこれから変えようとしていることです。方程式に時間を導入しましょう。
コンデンサやドラムの振動膜のような実際の物理システムについて考えてみてください。それらは瞬時にゼロにリセットされるのではありません。過去の状態のエコーを運びます。
では、時刻Tにおける層Lの状態の基本方程式を書き直しましょう。これは、フィードフォワードケースと同様に、前の層が今送っている信号に影響されます。
しかし、過去の自分自身のエコーも感知します。ここでMを、状態が時間の中でどのように伝播するかを記述する一般的な記憶関数としています。そして、Mの選択によって、異なる種類のニューラルネットワークが得られます。
最も自然な選択は何かを考えてみましょう。物事を明確に見るために、レイアウトを変更しましょう。ここでの横軸は、以前と同様にネットワークの層を横切る進行を示しています。
しかし今、縦軸があり、シーケンスの要素を横切る時間の進行を示しています。この2Dグリッド上で、各ノードは2つの情報源を受け取ります。左から流れ込む矢印は前の層によって伝達され、上から流れ込む矢印はM関数を介して過去の自分自身から時間を超えて伝達される情報です。
バニラRNNの誕生と限界
さて、あなたがこれを初めて発明している研究者だと想像してください。記憶関数が何であるべきか熟考しています。これが最も自然な選択です。横矢印の伝播ロジックを取り、縦矢印に同じ関数形式を持たせて、グリッドを対称にしましょう。
結局のところ、フィードフォワードネットワークから、活性化関数に続いて重みのセットによる線形投影というこのパターン、この発火と投影がかなりうまく機能することがわかっています。したがって、別の再帰的重みのセットを持ち、状態の時間的伝播が発火と投影変換されたコピーになるようにしましょう。
言い換えれば、Mは一つの層から次の層へのフィードフォワード変換とまったく同じ形式を持ちます。そして、実際の状態は、異なる接続行列のセットを持つ2つの類似した項の合計にすぎません。一つは各層のニューロンが次の層のニューロンにどのように接続するかを示し、もう一つは各ニューロンが同じ層の隣接ニューロンに時間を超えて情報を伝達する方法を示します。
そして、これはまさに80年代に研究者が最初に試したことです。これは通常見られるリカレントニューラルネットワークのバニラ定式化です。
しかし、実際には大きな問題があります。バニラRNNは数時点前に何が起こったかを追跡できますが、その記憶範囲は著しく制限されています。長期依存関係を学習することは根本的に不可能です。その理由は、エコーのために選択した操作そのものに焼き付けられています。
情報が縦軸に沿って移動するときに何が起こるか考えてみてください。すべての時点で、σを通過してからW_recで掛けられます。つまり、処理され、押しつぶされ、回転され、投影されます。10時点後には、元の信号が10回処理されています。100時点後には100回です。
これは伝言ゲームのようなものですが、すべてのステップで、メッセージはささやかれるのではありません。言い換えられ、要約され、再解釈されます。後から考えれば、これは驚くべきことではありません。この記憶関数をフィードフォワード経路からコピーして選択したことを思い出してください。
そして、フィードフォワード経路は情報を捨てるように設計されました。それがその全体の目的です。異なるポーズ、照明、異なる背景の猫のすべての可能な画像を同じ出力にマッピングすることです。言い換えれば、圧縮であり、保存ではありません。
変動を徐々に破棄するために意図的に構築された操作を取り、まったく逆のこと、つまり時間を超えて情報を忠実に保存することを要求しました。したがって、失敗するのも当然です。
残差接続の発見
そして、ここに重要な洞察があります。時間を超えて情報を確実に保存するには、情報が繰り返し処理されることなく流れることができる経路が必要です。選択的で制御された変更のみで、ほぼ無傷のまま前方に運ばれます。
実際、ディープラーニングコミュニティはすでにこのまったく同じ洞察につまずいていましたが、異なる文脈でした。ビジョンネットワークが成長するにつれて、人々は層を超えても一部の情報を変更せずに保存することが有用であることに気づきました。
ブレークスルーは残差接続でした。信号が層の変換を完全にバイパスできる直接ショートカットです。これは非常に深いネットワークを訓練可能にした革命でした。
私たちのバニラRNNには、時間を超えてまさにこれが欠けています。水平方向に少数の処理段階ではなく、垂直方向に数百または数千の時点があります。そして、重要な情報が変更されずに波及する必要があります。記憶のための残差接続のようなメカニズムが必要です。
漏れバケツメカニズム
情報を処理するのではなく保存する最も単純なエコーは何でしょうか。発火と投影操作の代わりに、エコーが単に前の状態の一部αを保持するだけだったらどうでしょうか。このαは記憶を制御する単一のノブです。
それを回すと何が起こるか探ってみましょう。αがゼロに等しいとき、エコーは消えます。各時点は独立しています。最初の健忘症のフィードフォワードネットワークに戻ります。
αが1に等しいとき、状態は完全に保存され、新しい入力は単にその上に追加されます。これは、探していた残差接続とまったく同じように見えます。では、問題解決ですね。
まあ、完全にはそうではありません。残差接続が層を超えて使用される場合、層の数は固定されています。10または50と言いましょう。ネットワークは常に同じ深さです。すべてのトレーニング例は同じ数の加算を通過し、ネットワークはそれに応じて自分自身の出力を調整することを学習します。アーキテクチャは、固定された既知の蓄積量を中心に構築されています。
シーケンスにはこの贅沢はありません。ビデオは少数のフレームかもしれません。または、ロード・オブ・ザ・リングの拡張版、50万フレームかもしれません。
αが1に等しい場合、新しい状態は前の状態プラス新しい入力に等しくなります。これを展開すると、状態は今まで受け取ったすべての入力の累積和です。10,000時点後には、それは積み重ねられた10,000の貢献の山です。
何も破棄されませんが、何も見つけられません。一通の郵便物も捨てないようなものです。技術的には何も失われていませんが、あなたの机は埋もれており、すべての手紙が同じくアクセス不可能です。これは記憶ではありません。これは溜め込みです。
したがって、正しい値はその中間のどこかにあるはずです。αを0と1の間に設定しましょう。そして今、興味深いことが起こります。最近の入力は強いままですが、古い入力は指数関数的に消えていきます。
これは漏れバケツです。情報が注ぎ込まれ、ゆっくりと排出されます。そして、ここに満足のいくひねりがあります。これは自然が最も好む記憶メカニズムであることがわかります。
ニューロンの膜電圧はまさにこの方法で機能します。電荷はシナプス入力から蓄積され、膜のイオンチャネルを通って漏れます。実際、計算神経科学で最も広く使用されているモデルの一つ、漏れ積分発火ニューロンは、まさにこの方程式です。
ゲート機構の誕生
しかし、この漏れバケツには独自の問題があります。今のところ、αはすべてのニューロンで共有され、すべての時点で固定された単一の数値です。
しかし、映画を見ているとしましょう。オープニングシーンで一度言及されたキャラクターの名前は、映画全体を通して持続する必要があります。各ショットの正確なフレーミングは今すぐ有用ですが、一瞬後には無関係になります。
単一のαは両方を行うことはできません。名前を保持するのに十分高いと、古くなった視覚的詳細の増加する山も保持します。詳細をフラッシュするのに十分低いと、名前も消えていきます。
必要なのは、すべてのニューロンが独自の保持率を持つことです。文脈に応じて各時点で変化するものです。修正は、スカラーαをベクトルf(t)に置き換えることです。ニューロンごとに1つのゲート、各時点で再計算されます。
記憶関数mが引数として入力も取ることに注目してください。忘れるべきものは到着するものに依存するからです。しかし、この忘却ゲートはどこから来るのでしょうか。
層が現在保持しているものと入ってくるものの両方を見て、各ニューロンに対して0と1の間の数値を生成する必要があります。これを行う機械はすでにあります。シグモイド活性化を持つ小さなニューラルネットワークです。
ニューロンのゲートが1に近いとき、その状態はほぼ無傷で通過します。ゼロに近いとき、古い値は消去され、新しい情報のためのスペースが作られます。
2Dグリッド上で、縦矢印は適応バルブを運び、それぞれが上からのエコーと左からの入力の両方を読み取り、エコーのどれだけを通過させるかを決定する小さな側回路によって制御されます。
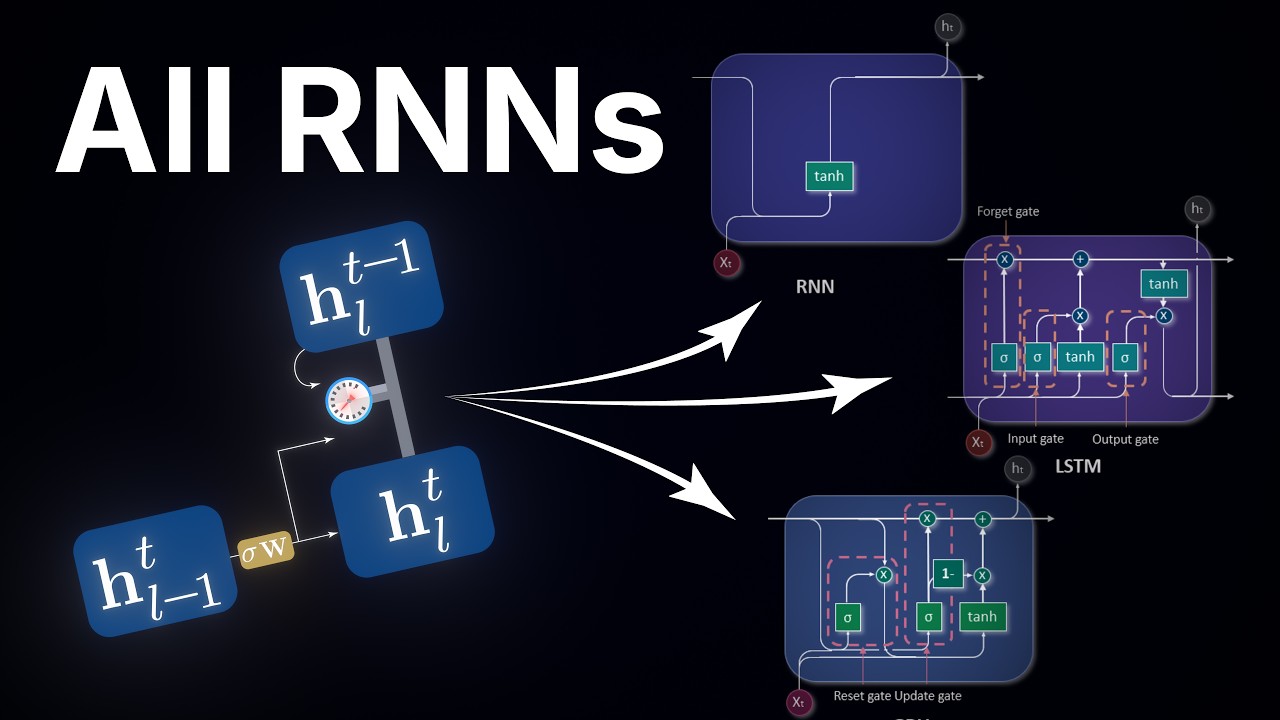
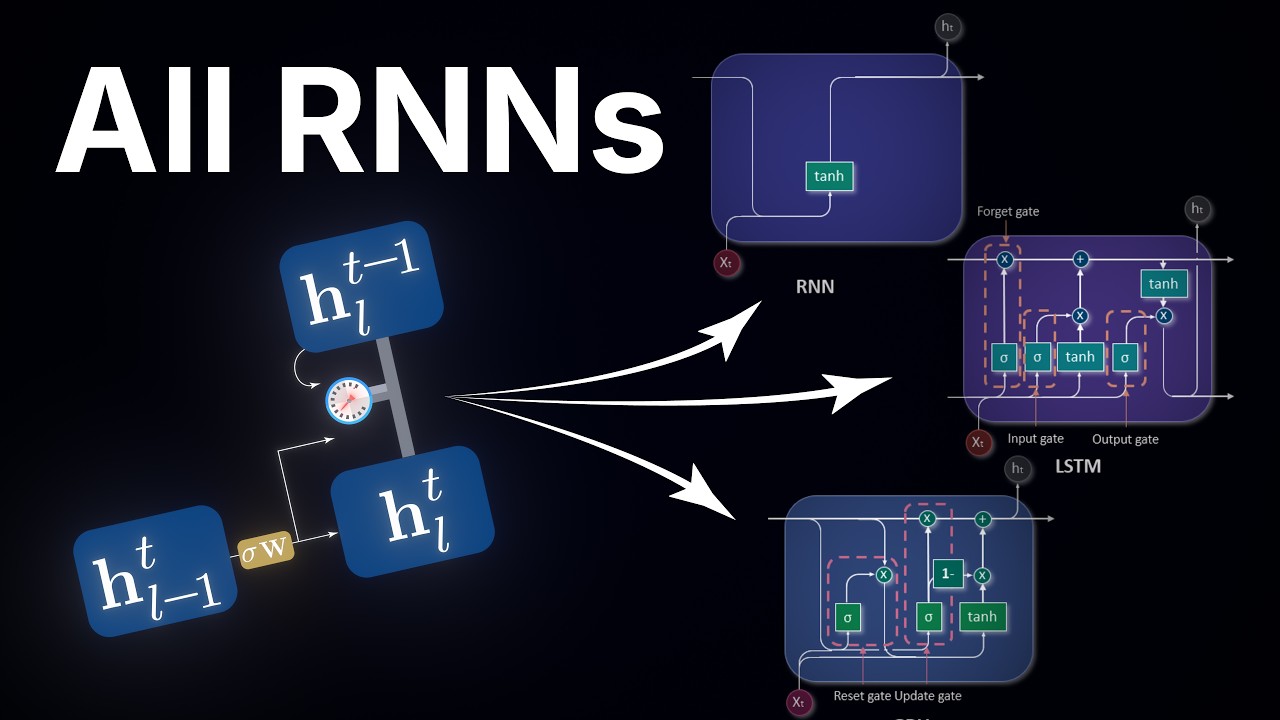
このゲート付き保持は、ゲート付きRNNとして知られるアーキテクチャファミリーの中心にあるコアメカニズムです。
実際には、これらのアーキテクチャにはしばしば追加の改良が含まれます。このファミリーの最も著名な2つのメンバーはGRUとLSTMです。それらは特定の配管が異なります。
GRUは忘却ゲートを補完的な更新ゲートとペアにし、LSTMはニューロンが知っていることと隣接ニューロンに叫んでいることを分離し、1つではなく2つの状態ベクトルを維持します。
しかし、これらはエンジニアリングの選択です。両方のコアメカニズムは、私たちが導き出したもの、つまりエコー上の学習された適応バルブです。そして、その単一のアイデア、選択的な文脈依存の忘却こそが、ついにリカレントネットワークに長期依存関係を学習する能力を与えたものです。
結論
振り返ってみると、私たちが行ったことは次のとおりです。静的で記憶のないネットワークから始めて、どのように時間の感覚を与えるかを問いました。答えは単一の追加項、エコーでした。
そして、リカレントアーキテクチャの動物園全体は、一つの質問に対する異なる答えであることがわかりました。記憶関数は何であるべきか。
フィードフォワードパスの対称的なコピーはバニラRNNを提供します。エレガントですが忘れっぽいです。固定されたスカラー減衰は漏れ積分器を提供します。自然のデフォルトです。
しかし、学習された文脈依存ゲートは、ついに何を覚え、何を忘れるかを選択できるGRUとLSTMネットワークを提供します。
しかし、これは表面をなぞっただけです。これらのネットワークが実際にどのように訓練されるかについては話していません。どのように時間を逆方向に誤差を伝播させるのでしょうか。
リカレントネットワークが脳について何を教えてくれるか、または訓練せずに再帰の複雑さを活用するリザーバーコンピューティングの魅力的な分野についても探求していません。しかし、それらは将来のビデオのための物語です。
ビデオを楽しんでいただけたら、友達と共有し、まだの方はチャンネルを購読して、いいねボタンを押してください。今後の計算神経科学と機械学習のトピックにご期待ください。


コメント