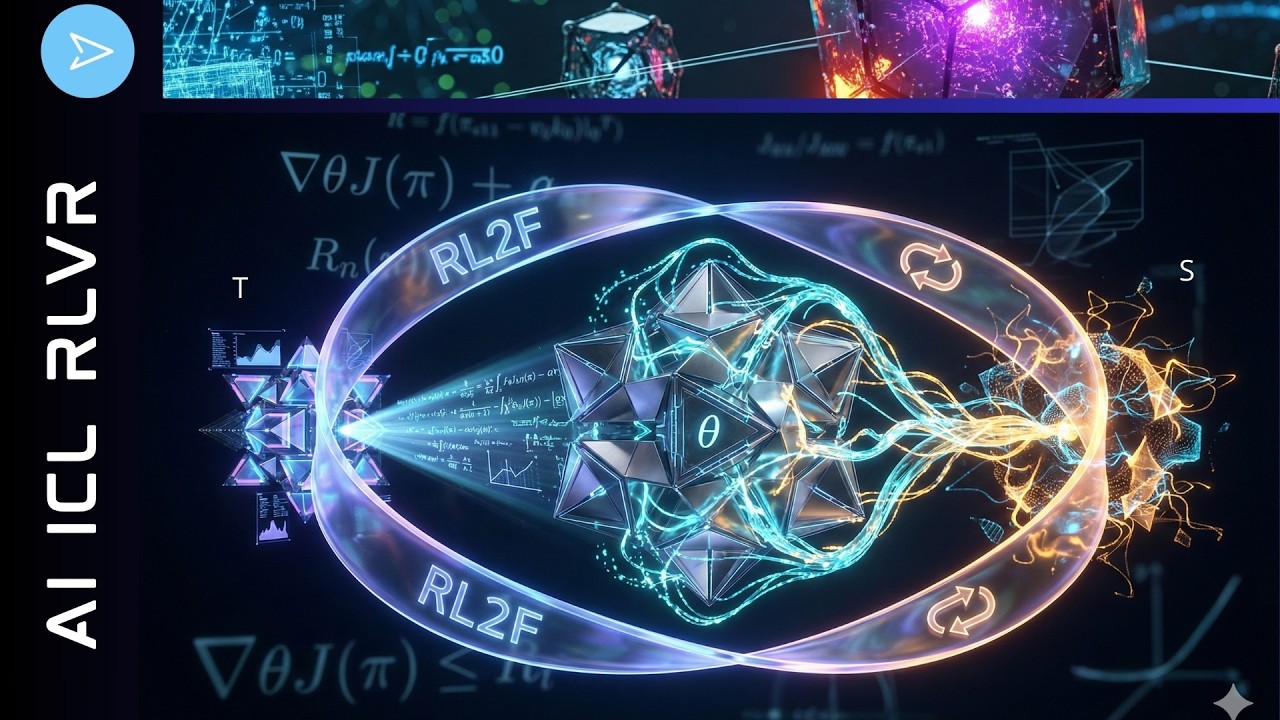
GoogleDeepMindが提案するRL2F(Reinforcement Learning with Language Feedback)は、文脈内学習と強化学習を融合した全く新しいAI訓練手法である。従来のLLMが静的知識の処理には長けていながらも、リアルタイムのフィードバックを文脈内で効果的に統合できないという根本的な限界を明らかにし、その解決策として教師モデルと学生モデルの対話的なマルチターン訓練を通じ、モデルが自己批判・自己修正能力を内面化する仕組みを構築した。特に注目すべきは、外部教師なしで学習モデル自身が教師役と学生役を交互に担う「自己教授的自己改善」の実現であり、数学ベンチマークにおいてGemini 2.5 Flashが同Proに迫る性能を達成したことは、AIの継続的自己学習という長年の課題に対する有望な突破口を示している。
AIとは何か──5分でわかる全体像
こんにちは、コミュニティの皆さん。また戻ってきてくれて本当に嬉しいです。今日は文脈内学習(In-Context Learning)と、検証可能なフィードバックによる強化学習を組み合わせた、全く新しい論文を紹介します。
ちなみに、サムネイルをどうやって作っているかよく聞かれるのですが、あれは単純にテキストを入力しているだけです。気になる方は、ぜひチェックしてみてください。
今日の内容を整理すると、教師モデルと学生AIの構造があって、さらに複数のAI訓練手法を組み合わせた全く新しい方法論を見ていきます。その前にまず、人工知能を5分で説明してほしいという要望があったので、サクッとやってみましょう。そのあと、この新しい手法について詳しく解説します。
まず文脈内学習(ICL)について。これはいわば機械の短期反射と言えるものです。プロンプトを受け取り、ニューラルネットワークの根底にあるテンソル重みの構造を変えることなく、あくまで活性化だけで即座に刺激に適応します。
次に重要なのが、教師ありファインチューニングと強化学習を組み合わせた、検証可能な報酬を使った学習です。これは答えが確実に正しいかどうか分かる場面でのみ使えます。数学やコードがその典型で、実行してみれば動くか動かないかがすぐわかりますよね。いわば機械にとっての「正規教育」です。モデルは閉じた決定論的なシステムに置かれ、コンパイルが通るか失敗するか──それだけです。そうして論理を学習していくわけです。
一方、複雑でオープンエンドな問題に対しては、強化学習が使われます。たとえば「歴代アメリカ大統領で最もハンサムなのは誰か」と聞いても、答えは人それぞれですよね。つまり正解が一つに定まらない場合です。この場合、報酬は主観的で遅延があり、複数の目的を持ちます。人間の好みや複雑な戦略ゲームなど、そういった問題が対象になります。ニューラルネットワークは、報酬が曖昧で多目的な、開かれた複雑な環境をナビゲートするわけです。
シンプルなLLMからAIエージェントへ
そしてシンプルなLLMから、いよいよAIエージェントへと話が移ります。エージェントの核心にはもちろんLLMがありますが、最も重要なのは外部環境と接触している点です。エージェントには2つの要素があります。絶対に覚えておいてほしいのですが、メモリとツール呼び出しです。
メモリには最適化パス、ツール呼び出しには通信プロトコルやエージェント間通信プロトコル、商業プロトコルなど様々なものが含まれます。神経学的なアナロジーを使うなら、エージェントは実行機能を持つ前頭前皮質のようなものです。左脳の推論能力を受け取り、物理的あるいはデジタルな道具──つまりツール呼び出し──を通じて実体化します。そして記憶の最適化は海馬に相当します。
今本当に面白いと思っているのが、継続的な機械学習です。これまでのAIは事前学習があって、そのあとポスト学習があるという流れでした。でもAIに継続的な学習をさせたいとしたら?メモリ最適化があるじゃないか、と思うかもしれませんが、それだけでは不十分なんです。もう少し賢くやる必要があります。目指すべき理想は、ニューラルネットワークに神経可塑性を持つAIマシン、つまり過去の知識を忘れずに継続的に学習できる能力です。
エージェントが一つあれば、次のステップはマルチエージェント学習アルゴリズムです。これはまったく別物で、非常に複雑になります。マルチエージェント構成のトポロジーや通信プロトコルを考慮しなければならず、スウォームインテリジェンスやオーケストレーターAIなど様々な形態があります。
そしてエージェント間通信では、深刻なカスケードエラーが問題になります。エージェントAがほんの些細な情報をエージェントBに対して幻覚(ハルシネーション)した場合、そのエラーはマルチターンのやり取りを通じて指数関数的に増幅されます。最終的に何が起きるか、想像してみてください。
テキスト、視覚、ロボティクスの違い
これはテキストだけを扱う場合の最初のレベルの複雑さに過ぎません。視覚を加えるとどうなるか──実はまったく異なるメカニズムやアルゴリズムが必要になります。テキスト推論だけに依存するか、視覚的推論能力も発達させるかによって、すべてが変わります。
そしてロボティクスはどうでしょう。これはマルチモーダルなアクションが環境にフィードバックされるケースで、また全く別のアルゴリズムが必要になります。美しいですよね。
まだ触れていないのが自己教師あり事前学習です。一つの細胞を海に放り込んで、その細胞が次の100時間、1000時間を海の中で生き延びられるだけの知性を与えられるかを試すようなイメージです。マルチモーダルなスケーリング、時間、相互作用、生存プロセス──そういったことへの対処が必要で、これはまだずっと先の話です。アライメント、安全性、合成データ生成はどれもオープンエンドな問題です。以上が最初の5分で探ったAIの現状です。
最新研究:検証可能な報酬とGROアルゴリズムの問題
それでは本題に入りましょう。現在のAI研究でホットなトピックはどれも重要ですが、今日は特に検証可能な報酬に注目します。
2026年2月19日、つまり昨日公開された新しい研究で、復旦大学と交通大学が、LLMの効率的な推論のための勾配利用、確率質量、シグナル信頼性の統合という論文を発表しました。彼らはGROアルゴリズムを精査した結果、このアルゴリズムが硬直した均一で対称的な信頼領域メカニズムに依存しており、LLMの複雑な最適化ダイナミクスと根本的にズレていると指摘しています。問題点を特定し、解決策として「MASSO(Mass Adaptive Soft Policy Optimization)」という統合フレームワークを提案しています。
同じく昨日、MITとNVIDIAがLLM向けのオフポリシー強化学習を研究しており、速度が不十分という問題に直面し、「分散制御ポリシー最適化」を提案しています。OpenAIのGPOから出発し、GPOスタイルアルゴリズムの汎用安定化手法として、最小分散のクローズドフォーム解と補助的価値モデルを回避する方法を示しています。面白い研究ですが、今日話したいのはこれではありません。
RL2F:新しいAI訓練の全体像
今日見せたいのは、AIシステムを訓練する全く新しい方法です。教師モデル、学生モデル、クラスターアルゴリズムがあり、強化学習と文脈内学習を完全に融合させます。オープンソースでないモデルの場合、文脈内学習にしか頼れないことがありますが、そのICLのメカニズムを理解するために、全てを分析できるオープンソースモデルを使います。
ただ一つ注意があります。以前の動画でGoogleが示したように、文脈内学習は完全ではなく、不応答な側面があります。LLMの文脈内学習には固有の問題と非応答性があります。
昨日2026年2月19日にも、カリフォルニア大学バークレー校が線形対二次注意モデルにおける文脈内学習の理解に関する研究を、UCリバーサイドが行動神経科学の発見に文脈内学習を応用した研究を発表しており、この分野がいかにホットかがわかります。でも今日の本題はこれらでもありません。
GoogleDeepMindのRL2F論文
今日取り上げるのは、GoogleDeepMindによる、自然言語フィードバックだけを使ってLLMの対話的な文脈内学習を改善するという研究です。一昨日公開されたものですが、非常に魅力的な内容です。
著者たちは自己改善するAIモデルに関心を持っています。海に細胞を放り込んで、その細胞が増殖し、別のアルゴリズムや別の存在形態に変容できるような知性を与えるという実験です。彼らはAIシステムの自己改善実験でこれを試みています。
具体的には、モデルが教師の批評を予測するよう訓練することで、外部シグナルをLLMの内部能力に変換し、教師がいなくてもAIモデルが自己修正できるようにします。
ステップを追って説明しましょう。
AI自己学習の仕組み
まずAIの自己学習、つまり人間の介入なしに学習するということです。人間が正しい・間違いと言ったり、LLMと会話したりする必要はありません。人間のフィードバックと完全に独立して動作するAIを目指します。
現在のLLMは膨大な静的知識の処理には優れていますが、リアルタイムのインタラクションからの学習は苦手です。静的知識には優れたアルゴリズムがあるのに、リアルタイムインタラクションでは全く機能しません。複雑なプロンプトエンジニアリングでAIモデルを望む結果に誘導しようとしても、ボトルネックがあってうまくいきません。
ユーザーがLLMを教える価値を持つためには、モデルが会話の文脈の中でフィードバックを適切に解釈・推論し、動的に行動を調整しなければなりません。人間との会話でも、別のAIエージェントとの会話でも同様です。
通常の強化学習なら最後にスカラー報酬があって最適化のための明確な勾配があるのですが、言語フィードバックはそのような直接的な最適化になじみません。だからこそGoogleDeepMindは新しいアルゴリズムを発明する必要がありました。
文脈内学習は訓練時ではなく推論時の現象であることを覚えておいてください。これはトランスフォーマー層の隠れ状態、つまりキー・バリューキャッシュ、いわゆる高速重みの中で完全に起こります。ニューラルネットワーク層のテンソル重みそのものには触れていません。
この新研究では、現在のモデル──Gemini 2.5 ProとGPT-5──が文脈内学習中に深刻なニューラル可塑性の喪失を示すことが明らかになっています。複雑な推論課題に直面したとき、ユーザーが数学的な誤りを指摘しても、GPT-5はしばしば丁寧に感謝を述べながら、直前に犯したまったく同じ数学的な誤りをそのまま繰り返します。修正を受け取っても、それを推論パスに統合すべき修正として理解せず、単なる情報として扱ってしまうわけです。
Googleの言い方を借りれば、GPT-5は批評を「代謝」して推論の軌跡を変える認知的柔軟性に欠けているということです。
RL2Fの解決策:テンソル重みの最適化
では、どうすれば解決できるのか。文脈内学習の高速重みの欠陥を修正するには、実際のネットワークのテンソル重みを永続的に変更する必要があります。
ここで著者たちは文脈内学習と強化学習を特別な方法で融合させます。強化学習をメタオプティマイザーとして使い、文脈内学習を最適に行うような特定の方法でネットワークを訓練するのです。テンソル重みの構造を文脈内学習のために修正しているわけです。
強化学習を使うためには報酬が必要です。マルチターンのフィードバックを成功裏に統合して検証可能な正解に到達したときだけ報酬を与えることで、強化学習は低速重みに、アルゴリズムの前向きパス内で高度に反応的で可塑的なICLアルゴリズムを刻み込むよう強制します。
具体例で説明しましょう。学生モデルが誤った数学の解答を生成し、教師AIが批評を与えます。解答ではなく、ヒントだけです。「1を繰り上げ忘れたよ」という感じで。この批評はキー・バリューキャッシュ、つまり活性化の中に完璧に埋め込まれ保存されます。
しかし学生が次のトークンを生成するとき、知性とは何かを考えてみてください。クエリQを計算します。もし低速重み、つまり実際の重み行列WQが修正フィードバックを重視し反応するよう明示的に訓練されていなければ、Q×K(批評の転置)の内積は低い注意スコアをもたらします。つまりモデルは文字通り「高速重みの中の教師フィードバックに注意を払わない。そう訓練されていないから」と言うわけです。これはパターンマッチングマシンです。そのパターンがなければ、批評を完全に無視して自分の生成した誤った履歴に大きく注意を向け、同じエラーを繰り返してしまいます。これが著者たちの言う「AIにおけるニューラル可塑性の喪失」です。
RL2Fの解決策と仕組み
その解決策として彼らが提唱するのが「言語フィードバックによる強化学習(RL2F)」です。低速重みを積極的に更新して、モデルが内部で情報をルーティングする方法を変えます。勾配でネットワークを罰し、教師の指示を無視しないようにします。これにより、強化学習ファインチューニングの後、モデルがクエリを計算する際、活性化の中の批評トークンに大きな注意スコアを割り当てることが数学的に奨励されます。
要するに、この馬鹿なAIマシンに言語フィードバックへの反応の仕方を教えなければならないのですが、それは文脈内学習だけではできません。活性化だけではアーキテクチャ上不十分なのです。だから強化学習ファインチューニングを適用し、テンソル重みを特定の方法で変更して、教師から来る批評トークンに大きな注意スコアを割り当てられるようにする必要があります。
一言で言えば、静的なテンソルフィールドを最適化することで、一時的な活性化が文脈内学習をずっとうまく実行できるようにするということです。
二つの絡み合った目標の最適化と言えます。文脈内学習の活性化が不十分であることを認識し、ブラックボックスの奥深くに入り込み、テンソル重みを最適化アルゴリズムで修正します。その最適化の目的は、文脈内学習を美しく機能させることです。シンプルなアイデアです。
教師と学生のマルチターン対話
Googleはこう説明しています。学生と教師AIの間の相互作用をシミュレートし、学生が教師の指導を統合しながら繰り返し解答を改善しなければなりません。数学やコードのような検証可能なドメインで高品質なフィードバックを生成するのに、優れた教師モデルは必要ありません。学生と同じモデルが教師役を担えます。ただし、情報の非対称性を与える必要があります。つまり、学生がアクセスできない正解情報(ユニットテストの出力や数学の証明など)を教師に与えるだけでいいのです。
これを彼らは「対話的相互作用(Didactic Interactions)」と呼んでいます。学生がいて、回答があり、教師がいます。教師は問題を見て、単体テストの出力や数学の解答という特権的情報にアクセスできます。学生の答えが正しいか間違いかを把握し、間違いなら解答ではなく自然言語のフィードバック、ヒントだけを渡します。これを繰り返す最適化ループです。
学生モデルと教師AIはほぼ同一ですが、教師だけが特権情報にアクセスできます。これが情報の非対称性です。単発問題をマルチターンの対話的相互作用に変換します。
1ターン目で教師がヒントを出し、2ターン目でまた別のヒント、そして3ターン目でついに学生が正解に到達する──というイメージです。10回でも50回でもハードコードすればいい、シンプルな方法論です。ただし重要なのは、これが訓練時の強化学習ファインチューニングであるということです。強化学習を使って学生モデルが言語フィードバックを効果的に取り込めるよう訓練しています。
正解なら報酬が与えられ相互作用が終了します。不正解なら教師がフィードバックします。最大ターン数に達したら報酬はゼロです。従来からある手法の、別の組み合わせ・別の順序でのアライメントチューニングとICLです。
自己教授的自己改善の実現
私が気になるのは、このシステムとアルゴリズムで、ワールドモデリングを通じた本当の自己改善AIが実現できるかどうかです。本当に自律的な自己教授的自己改善が可能なのか?もしそうなら、このアルゴリズムを自分自身にも適用できるかもしれません。
論文を丁寧に読むと、ほぼ末尾に非常に重要なステップが書かれています。言語フィードバックからの学習(ドメイン内)があり、次に汎用マルチターンタスク(ドメイン外)があります。数学からコーディングへの移行など、ドメイン外でも機能します。そしてメインパートとして、文脈内自己改善への跳躍があります。
ここが違います。推論時の評価です。3つの設定でAIモデルを評価します。第一に、外部の言語フィードバックソースとのインタラクション。これについてGemini 2.5 ProやGPT-5のパフォーマンスグラフを後ほど見ます──正直、がっかりする結果です。第二に、ドメイン外のタスクや論理パズルなどの汎用マルチターンタスク。第三、そして最も重要なのが、モデルが学生と教師の両方の役割を担って自己修正する文脈内自己改善です。
さらに魅力的なのが、学生AIが報酬を最大化するだけでなく、教師の次の批評を予測するという追加の目的関数です。フィードバックを1000件見たとき、共通のパターンはあるか、構造はどうか、どんな要素があるか、数学的操作を指しているのか、オブジェクトの定義か、論理的な流れか──そのパターンを学生AIは学べます。
1万件、10万件のリアルな教師批評で訓練された後、学生は自分のエラーの文脈だけから教師の分布、つまりポリシーπ教師を内面化します。そしてテスト時には外部教師AIが取り除かれます。なぜなら、それはもともと特権情報(RAGなど)にアクセスしていた同じモデルだったからです。
こうして学生は自律的な自己教授的AIシステムとなり、解答を生成し、(教師パターンから学んだ)自己批評を行い、それを洗練させるという作業を交互に担います。これが標準的な単発強化学習サイクルを大きく超えるパフォーマンス向上をもたらす可能性があります。
パフォーマンスの検証
本当にそうなのか?これが今日、私がAIとその複雑さを──文脈内学習、RLVR、オープンエンドRLという観点で──このように構成して説明した理由です。継続的な機械学習とAI自己学習にも触れています。まさにこの新しいアルゴリズムとGoogleDeepMindの新論文が、LLMに関連するすべての要素を扱っているのです。
もはやLLMに数学の問題の答えを記憶させているわけではありません。低速重みを、活性化を、つまりキー・バリューキャッシュ自体の中に仮想的な前頭前皮質を構築するよう訓練しています。読み取り、仮説を立て、批評を受け取り、批評を理解し、アルゴリズム的な疑念を経験し、自己修正する──そういった能力です。
これが文脈内学習の真のエッセンスです。ただし単独ではなく、強化学習を通じて実現された文脈内学習です。ICLの活性化と強化学習によるテンソル重みの最適化の間の濃密な相互作用。ICLのために強化学習のテンソル構造を最適化する。エレガントですが、最初にこのアイデアを思いつかなければいけないのですから、すごいことです。
グラフで見るパフォーマンス向上
著者たちは標準的な単発強化学習と比較して大きなパフォーマンス向上があると言っていました。データを見てみましょう。
ベースラインはGemini 2.5 Proで、X軸がターン数(1〜10)、Y軸が精度(40%〜70%)です。
ベースラインのGemini 2.5 Proでのパフォーマンスがあります。対話的相互作用で外部教師モデルを使った場合、達成できる最高パフォーマンスは65%程度(点線)です。そしてGoogleDeepMindが今日紹介した自己改善手法を適用した場合、緑色の線が示すように6ターン後にその線を超え、本当に自己学習・自己改善するAIシステムを実現しています。数学という非常に狭いドメインに限定されていますが、確かに起こっています。可能なのです。
マルチターンの対話的相互作用からの学習のためにモデルを訓練することで、推論時の自己改善能力が大幅に向上しています。ターンを重ねるごとに性能が上がっていく、それ自体が驚きです。
Gemini 2.5 FlashがProに迫る
次にGemini 2.5 FlashとGemini 2.5 Proの比較を見てみましょう。小さいモデルが大きなモデルの性能に追いつけるでしょうか。
濃紺の線が単発強化学習、つまり従来の学習経験で、成功率50%以下と非常に限定的です。しかし新しい手法を見てください。Gemini 2.5 Proの性能にほぼ追いついています。本当に自己学習システムです。自分の知識に知性を加えることができるのか?絶対に魅力的です。
RL(強化学習)とマルチターンの対話的相互作用を通じた訓練により、Flashは困難な数学ベンチマーク「MATH 2」データセットでProに迫る性能を達成しています。もちろん非常に特定のベンチマークで、他のベンチマークでは結果が異なるかもしれません。しかし理論的には、確かに機能するケースが一つ存在し、それだけで十分なこともあります。
教師ありファインチューニングと強化学習の比較
個人的に興味があるのが、教師ありファインチューニング対強化学習の比較です。数学的な表現理論の観点から、特定の表現を選べば教師ありファインチューニングと強化学習はほぼ同じだという動画を複数作ってきましたが、今回はその比較が含まれています。
単発強化学習と単発教師ありファインチューニングを比べると、ベースラインのGemini 2.5 Proが赤線、単発教師ありファインチューニングが青線、単発強化学習が薄いグレーの線──そしてこの二本がほぼ並行しています。つまりこの数学タスクにおいては、教師ありファインチューニングと強化学習の学習効果はほぼ同じということです。これは非常に興味深い結果です。
現行モデルの文脈内学習能力の検証
さらにクロスチェックとして、重みの更新を行わない場合、つまり強化学習ファインチューニングをせずに、現在のLLMがすでにこのフィードバックを文脈内で効率的に取り込めるかどうかを確認します。
GPT-5とGemini 2.5 Proで1〜3ターンの結果を見ると、グラフはほぼフラット、ほぼ水平です。成長がほとんど起きていません。現在のモデルは新しい手法なしでもわずかにフィードバックを文脈内で統合できていますが、RL2Fほど効率的ではありません。
グラフでは薄い緑点線がGemini 2.5 Pro、濃い青実線がGPT-5で、GPT-5の方が文脈内での学習可能性は少し高いですが、新しい手法と比べると全然話になりません。AGIタスクに移ると、さらに早く平坦化します。
たった3ターンしかないのに、現在のモデルでこのフィードバックを使った文脈内学習はほとんど起きていません。しかしもしGoogleがこの自己改善の新手法を実装したら──次のGoogleのモデルが楽しみです。
まとめと次の動画へ
以上が今日お伝えしたかったことです。AI研究の現状を今日のようにまとめた理由が、これでわかってもらえたと思います。継続的な機械学習と自己改善について話しました。AIエージェントについては全然話さなかったな、と気づいた方もいるでしょう。そうです、次の動画まで待ってください。
Googleはまだ継続的機械学習アルゴリズムの研究段階にあります。単一エージェントの最適化、まして多エージェントの最適化の話ではありません。本当に自己学習するAIマシンを構築したいとなったとき、一体何が起きるのかを理解しようと、研究はまだそのレベルにとどまっているのです。
楽しんでもらえたでしょうか。何か新しい情報がお役に立てれば幸いです。いいねやチャンネル登録、メンバーになっていただけると嬉しいです。次の動画でお会いしましょう。


コメント