本動画では、自己学習型AIにおける新しい強化学習アルゴリズムを紹介する。従来の自己精錬トレーニング(SRT)は、AIモデルが自ら質問を生成し、回答し、自己評価するという理想的なアプローチだが、ポリシー崩壊とエントロピー崩壊という2つの致命的な不安定性に悩まされてきた。この問題に対し、MGRPO(モメンタムアンカー付きグループ相対ポリシー最適化)という新手法が提案された。これは、急速に変化する「生徒AI」と、その指数移動平均である安定した「教師AI」を並行して維持し、両者の出力を多数決で組み合わせることで擬似的な真実を確立する。さらに、四分位範囲(IQR)を用いた軌跡フィルタリングにより、低エントロピーの過信的な推論パスを排除し、多様性の高い探索を促進する。実験結果では、QwQ 40億パラメータモデルにおいて、従来のSRTが訓練中に崩壊するのに対し、MGRPOは安定的に精度を向上させ、数学、推論、コーディングベンチマークで最先端の性能を達成した。この手法により、人間のラベルなしでAIモデルの自己改善が持続可能になり、長期的な訓練における安定性が実現される。
自己学習AIの新時代
コミュニティの皆さん、お帰りなさい。人工知能のための新しい強化学習アルゴリズムが登場しました。美しいと思いませんか?きっと気に入っていただけるはずです。私のチャンネル「ディスカバリー」へようこそ。最新のAI研究論文をご紹介していきます。
さて、現在のAI推論研究には秘密があります。誰でもAIモデルを数ステップ改善することはできますが、真の根拠データ多様体なしで、長期間の訓練でこの獣を安定させることは信じられないほど難しいのです。
ご存知のように、古典的な強化学習は検証可能な報酬を伴う強化学習です。そしてもちろん、聖杯は自己教師あり強化学習です。人間を一切介在させず、モデルが自分自身で質問を生成し、自分自身でその質問に答え、自分自身で採点し、自己教師あり学習体験を得るのです。
しかし今までこのアプローチは根本的に不安定でした。そして今日、今日私たちは、ついにこの自己改善ループを安定させる新しい手法を見ていきます。
「ああ、これは数学的に難しそうだ」と思われるかもしれません。いいえ、全くそんなことはありません。とても簡単で、笑ってしまうほどです。
SRTの危険な前提
SRT、つまり自己精錬トレーニングは、ちょっと危険な前提の上に成り立っています。そうです、モデルが生徒と自分自身の教師の両方として機能するのです。つまり、巨大な独自のGPT-6システムのようなものが教師として存在し、小さなローカルな生徒がいるわけではありません。いいえ、それは同じモデルなのです。
私たちは興味深い現象に直面しています。そうです、これらのモデルにはポリシー崩壊があります。「はい、もちろんそうでしょう」と言われるかもしれません。生徒と教師を同時にやろうとしているのですから、何を期待しますか?
SRT、自己精錬トレーニングをもう少し詳しく見てみると、学習プロセスのステップが増えるほど、精度報酬が大幅に低下し、検証精度がゼロにまで下がることがあります。
異なるモデルから見ることができます。ここにはQwQ 40億パラメータのベースモデルがあります。なぜこれが起こるのでしょうか?なぜなら、このAIモデルは自身の報酬ポリシーをゲーム化することを学ぶからです。高い確信度のゴミを生成するのです。
検証精度、つまりシステムの実際のパフォーマンスは、訓練報酬から完全に切り離されてしまいます。モデルが良いと思っているものと実際のパフォーマンスが乖離してしまうのです。
MGRPO:新しい安定化手法
では、このポリシー崩壊をどう扱うのでしょうか?今日のまったく新しい研究へようこそ。MGRPO、モメンタムアンカーポリシー最適化による大規模言語モデルのための自己教師あり強化学習の安定化、さらに追加のフィルタリング付きです。そうでないと少し退屈になってしまいますからね。
「モメンタムで何か知っている、GPO最適化で何かあった」と思われるかもしれません。はい、でも今度は次のステップがあります。なぜなら、お話ししたようにフィルタリングに関して何かがあるからです。
著者は上海イノベーション研究所、復旦大学の未来情報技術研究所、上海AI研究所、香港中文大学の方々です。素晴らしいですね。2024年12月15日に公開されました。
彼らはこれを見て、まさにこの崩壊があることを再現できます。これが主要なクラッシュグラフで、すべてが崩壊していくのが分かります。このSRTは単なる大惨事です。自己学習していません。
GPO部分だけを見ると、これは典型的なトリックです。つまり、得られるアドバイスは単にサンプルサイズを増やすことです。「よし、これをやってみよう」となります。より多くのロールアウトを生成すれば、より良い勾配推定が得られるはずです。誰もが「はい、もちろん、それがやり方です」と言います。
ケースマンの自己訓練パラダイム
ちょっとフラッシュバックをしましょう。これを覚えていますか?これはケースマンからの主要論文で、推論モデルの自己訓練ができるというものでした。2024年10月8日バージョンの最新版です。
彼らはまさにここで自己訓練、つまりパラダイムを扱っています。そのアイデアはとてもシンプルです。通常、検証可能な報酬を伴う強化学習では、プロンプトがあり、小さなLLMがあります。それが応答を出し、根拠証明で検証するだけです。そして正解か不正解かに応じて、特定の報酬を与えます。
自己報酬訓練は言います。「分かりました。私の小さなLLMは純粋なカオスマシンです。確率エンジンです。機械です。だから、統計を扱っているなら、同一のLLMから3つの答え、50の答え、500の答え、複数の応答を生成しましょう。
そして統計的な機械を使って500の異なる答えがあるので、その答えを生成したのと同じ機械による多数決を行います。この瞬間、「うーん、ここに何か間違いがある。これは本当に明確な数学的プロセスには聞こえない」と思うかもしれません。でも、これがSRTです。
そして推定された真実との検証があり、それから報酬を与えます。SRTとRLVR(検証可能な報酬を伴う強化学習)を比較すると、これが違いです。これがロールアウトで、ここには3つのロールアウトがあります。10ロールアウトでも128ロールアウトでも持てます。これを見てみましょう。
ロールアウトのスケーリングテスト
今日の論文の著者たちは、16から128までのロールアウトのスケーリングをテストしました。結果は、より高いロールアウトがピークスコアをわずかに増加させますが、モデルの完全なクラッシュを防ぐことはできず、部分的に遅らせるだけでした。
私たちの結論は、SRTにおける自己学習AIにおいて、単なる高分散ではなく、構造的な不安定性に直面しているということです。
何が必要でしょうか?そうです、ご存知のとおり、同じことの計算量を増やすだけでなく、より良いアルゴリズム的アプローチが必要です。新しいアイデアが必要なのです。
データをお見せしましょう。MATHベンチマークと推論ベンチマークがあります。お好きなものを選んでください。最初から始めましょう。
元々、QwQ 40億ベースモデルで行くと、精度は61.5%です。元のモデルでMATH 500が61.5%です。そして、SRTで16ロールアウトで行くと、わあ、75%にジャンプします。
ここで異なる温度、Tは温度ですが、で行くと、いくらかのバリエーションがあります。では32ロールアウトに行きましょう。75%から74%に下がります。興味深いですね。64ロールアウトを見てください。温度1.1で79.2%のピークに達します。興味深いですね。
これを見ると、かなりカオス的なシステムですが、QwQ 40億モデルにとって64がピークのようです。そこで手動でシステムを64ロールアウトの後に停止させます。経験的データがあり、これがシステムのピークパフォーマンスだという感覚があるので、これで行きましょうと。
異なるベンチマークでは、これは正しくないことが分かります。なぜなら、ここの16では、異なるタスクのベンチマークでずっと良いパフォーマンスがあるからです。純粋なカオスであることが分かります。チェリーピックです。手作業で選んでいます。システムのピークパフォーマンスを見つけるために何時間も費やしています。
これが証明するのは、より多くの計算を投げ込むだけ、スケールアップして「さあ、どんどん高くしよう」と言っても、安定性の問題を全く解決しないということです。スケーリングは機能しません。
エントロピー崩壊という第二の問題
でも、私のチャンネルを見ている方はご存知ですが、自己学習には第二の障害モードがあります。もちろん、エントロピー崩壊があります。
私のチャンネルを初めてご覧になる方のために、もちろん、いつも最も重要な論文をお見せします。これです。2024年5月末の、推論大規模言語モデルのための強化学習のエントロピーメカニズムです。素晴らしいです。すべてGitHubなどすべてあります。上海AI研究所、清華大学、北京大学、南京大学です。素晴らしいですね。
これについて話したとき、私たちは言いました。LLMのための強化学習は、単にエントロピーをパフォーマンスと交換しているだけなのでしょうか?これを見たときのことを覚えていますか。興味深いと言いました。
エントロピー低下の利得の95%以上が、強化学習の非常に初期段階で起こり、その後プラトーになります。
これが私たちが対処しなければならない第二の問題です。サンプルについて話したことを覚えていますか。美しいですね。そして最適化については、数学的表記に馴染みがない場合は、特定のビデオがあります。そこでトークンエントロピーもお見せしました。異なるもののための高エントロピートークンを見ました。DPO強化学習メカニズムもお見せしました。
自己学習AIのパフォーマンスクラッシュに伴い、ポリシーエントロピーの崩壊にも対処しなければなりません。
ポリシーエントロピー崩壊とは
このポリシーエントロピー崩壊とは何でしょうか?どうやってその感覚をつかめるでしょうか?それは単純に、AIシステムが傲慢になるということです。単一の推論モードに急速に収束し、そこに留まります。他の解決策を探索することを事実上やめてしまいます。
一つの解決策を見つけて、「これで終わりだ。今日はこれ以上見回さない」と言うのです。そのため、モデルは準最適な解決策の多様体に過信するようになります。
エントロピーが底を打つと、ほぼ5%まで下がったのが分かりますが、モデルは自己修正、自己探索の能力を失います。なぜなら、学習するためのより多様な候補を生成することをやめてしまうからです。
これが、自己学習人工知能システムにおけるポリシーエントロピーの崩壊と呼ばれるものです。異なる40億パラメータのベースモデルで、異なる温度でこれを見たい場合は、ここにあります。でも今は明確だと思います。すべてがただ落ちていきます。美しいですね。
目標は何でしょうか?さて、何が機能していないかを理解しました。解決策を考え出さなければなりません。
私たちの小さなAIに、モチベーションを与える新しい方法が必要です。完璧な精度のために最適化しながらも、好奇心を持ち続け、高エントロピーを維持するように、強制する、いや、モチベーションを与える必要があります。
笑ってしまうとお話ししましたが、これが彼らがこの新しいGRPO最適化で構築したすべてです。「何だって、新しいモメンタムポリシーモデルを組み合わせただけ、これだけ?」と思われるでしょう。はい、これだけです。
時には単純なアイデアだけで済むのです。さらに詳しく見ると、もっと簡単になります。
モメンタムアンカーGRPOの仕組み
私たちはこれをモメンタムアンカー付きグループ相対ポリシー最適化と呼んでいます。古典的なGRPOに加えて、2つの安定化力があります。
追加のモメンタムモデルがあります。戦略πとθkがあります。現在の、つまり不安定なAIモデルのみに基づいて真実、本当の真実を計算する代わりに、並行して教師モデルを維持します。
この教師AIは単純に生徒AIの指数移動平均です。ゆっくりと変化します。これは生徒の10ステップ後ろを歩く老祖父のAIです。生徒はあらゆるものを探索して走り回っています。
その生徒の10ステップ後ろに、すべての入力と生徒が学ぶすべてを平均化しているだけの良き老教師AIシステムがあり、本当にゆっくりとしか変化しません。
利点は何でしょうか?生徒が一つのアイデアで狂ったり、一つのアイデアを幻覚したりした場合、教師がアンカーとなって「これは私たちのパラメータ内にありません。解決策を探していません。古い解決策に留まりましょう」と言います。
ハイブリッドルールプールは自明です。現在のポリシーから、早くて、狂っていて、不安定な小さな仲間からm個の答えを生成します。次に、モメンタムポリシー、つまりゆっくりで安定した祖父からn個の答えを生成します。
そして、もちろん祖父も投票権を持つ多数決があり、これらを組み合わせて自己学習AIの擬似真実を決定します。
「これは完璧に聞こえる。自己学習AIの擬似真実がある。何が悪くなり得るのか?」と思うかもしれません。まず、なぜこれが機能するのでしょうか?
このモメンタム、この祖父AIがアンカーとして機能します。これはゆっくりと沈む祖父が「さあ、走り回りなさい。私は安定した道を前に進んでいます」と言っているようなものです。
生徒が崖から飛び降りようとしても、過去100ステップでモデルがどのように振る舞ったかを覚えている教師が、真実を証明された多様体上の中心に引き戻します。
急速に変化する現在のポリシーモデル、つまり小さな生徒モデルから純粋に生成されたラベルのノイズと不安定性を軽減するために、安定したモメンタムモデルのロールアウトを投票プールに含めることが重要です。
擬似真実が確立されたら、擬似真実に基づいて現在のポリシーモデルのMロールアウトの報酬スコアを計算できます。報酬は二値です。馴染みのある正規化されたアドバンテージ関数があります。
最適化する最終学習目的を見たい場合は、これです。数学的命名法に馴染みがない場合は、52分で簡単にAI数学を説明する特定のビデオがあります。必要なことすべてを説明しています。これらのシンボルが何を意味するかについて。素晴らしいですね。
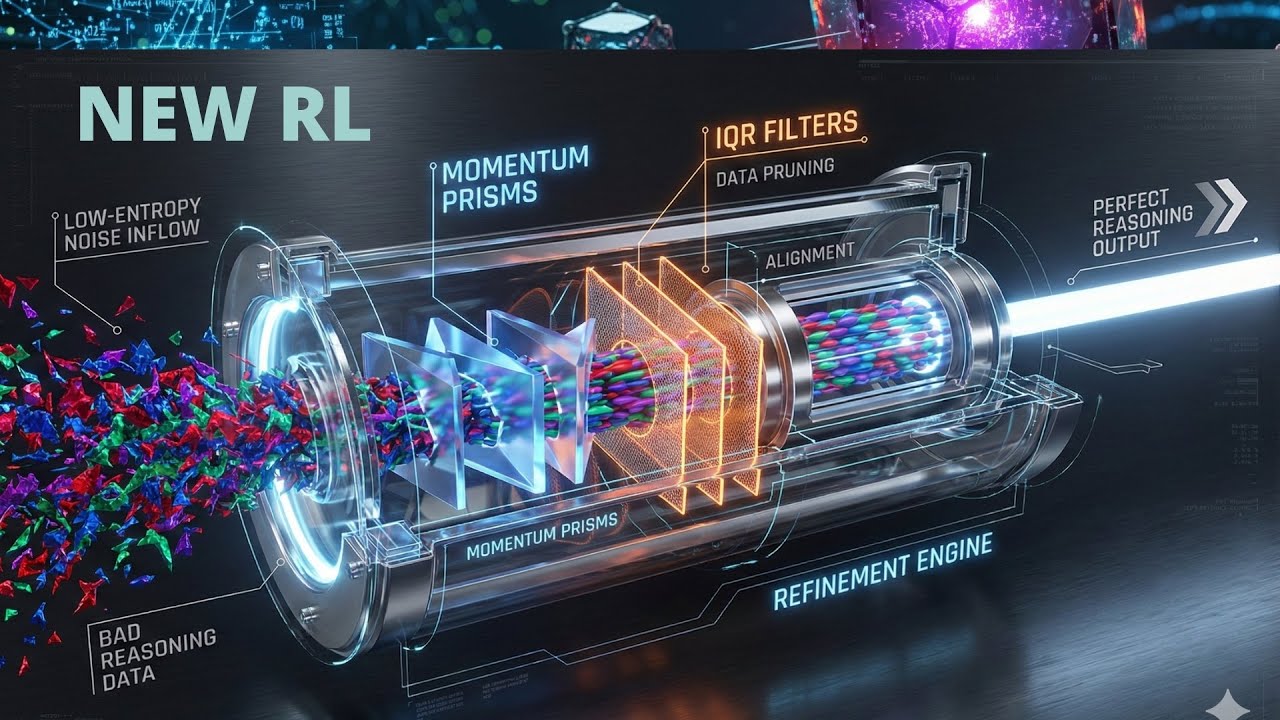
実際の論文に戻ります。低い推論、悪い推論、データが流入してきます。美しいですね。モメンタムプリズムがあります。ガラス構造があり、流れを最適化し、直接ここに導きます。
MGRPOにはさらなるアイデアがあるとお話ししました。これはフィルタリングシステムです。「なぜこれが必要なのか?」と思われるかもしれません。
エントロピー崩壊にまだ対処しなければならないことを思い出してください。フィルタリングが、エンジンから出てくる完璧なレーザービーム、完璧な推論を得るのに役立ちます。
IQR軌跡フィルタリング
どのようにフィルタリングするのでしょうか?気に入っていただけるでしょう。とても簡単です。IQR軌跡プルーニング方法論があります。IQR、四分位範囲です。エントロピー崩壊を解決するための最もシンプルな統計的アイデアです。
昔は静的なしきい値を適用していました。どこかの指示を読むと、ラインがあって、下位10%を捨てていました。
「これは人工知能のための革新的なアプローチだ」と思っていました。下位のすべてを捨てるだけです。素晴らしいですね。
この新しい方法論では、はるかに科学的です。バッチ内のすべての軌跡のエントロピーを計算します。四分位範囲のQ1とQ3の統計的広がりを計算し、それらを捨てます。
ほら、今ははるかに専門的です。統計的に低エントロピー外れ値関数である軌跡を破棄します。多かれ少なかれ、下位10%を捨てています。素晴らしいですね。
影響は何でしょうか?影響は、自己学習AI構造におけるレーザーのような過信した低エントロピー推論パスを取り除くことを期待していることです。
自己参照などがなくなります。AIモデルに、モード崩壊を引き起こすデータを飢えさせると言えます。より多様な、より高エントロピーの種類を学習するように強制します。
高エントロピーの種類だけを新しい訓練データセットに入れたいという事前選択を行います。
パフォーマンス結果と興味深い発見
パフォーマンスはどうでしょうか?今、絶対に魅力的になります。機能するのでしょうか、そして予期しない問題に遭遇するのでしょうか?絶対に予期しない問題です。
さあ、行きましょう。2024年12月15日の結果表があります。美しいですね。数学、推論、コードのベンチマークがあります。素晴らしいです。
もちろん、QwQ 40億ベースモデルで行きます。美しいですね。このベースモデルの元のパフォーマンスは、ご覧のとおり61.5%です。AIME 2025は5%、推論34%、コードは約10%です。素晴らしいですね。
では、何があるでしょうか?古典的なSRTがあり、2つあります。ベストとファイナルです。
ベストとは何でしょうか?お話ししたように、これはハイスコアです。これはSRTモデルからチェリーピックした、またはチェリーピックしていた絶対的なピーク値です。
これは200ステップから400ステップ、または800ステップの間のどこかで起こる絶対的な最高パフォーマンスで、すべてをテストしなければならず、「ああ、ステップ612だ。これがSRTベストの最良の方法だ」と言いました。
SRTファイナルでは、これはローススコアではありません。これはトレーニング実行の最後のモデルではありません。ポリシー崩壊が見られます。
元のモデルは61%でしたが、SRTファイナルはMATH 500の特定のケースで47%です。AIME 2025の他のケースを見ると、5%から8%になりますが、この500ステップへの道のどこかで11.67%のピークがあります。
これがチェリーピックだったことが分かります。モデルがどこに着地するか全く分かりませんでした。これは本当に高価でした。
残念ながら、タイプミスがあります。ここに間違いがあります。なぜなら、2つ目のSRTファイナルがあるからです。これは不可能です。値を見てください。
でも、これらの値がこの値に非常に近いので、私には考えがあります。ここのSRTファイナルは、単純に新しいMGRPOファイナルであるべきだと思います。なぜなら、その次がMGRPOプラスフィルタリングファイナルだからです。
フィルターなしとフィルターありを示すのは理にかなっています。でも、SRTファイナルにはなり得ません。なぜなら、異なる値を持つ同じ見出しの2つの異なる行を持つことはできないからです。
残念ながら、これはここで公開されているものとして正しくありません。これがプレプリントであり、ピアレビューされた論文ではない理由です。でも、大丈夫です。
この3行目はSRTファイナルではなく、フィルターなしのMGRPOファイナルであるという私の仮定で続けます。これがパフォーマンスのわずかなジャンプがあることを説明するでしょう。素晴らしいですね。
このタイプミスの私の仮定の検証を論文の他の場所で見つけることができるでしょうか?はい、見てください。
このMGRPO方法論の魔法は、チェリーピックする必要がないことです。なぜなら、これを見てください。精度報酬が上がり、検証精度は500でクラッシュせず、上がってきれいにプラトーになります。
これははるかに安定したモデルであることが分かります。MGRPOで行います。訓練を安定化させて、最終モデルが最良のモデルでもあるか、少なくともプラトーするモデルになるようにします。
500ステップや600ステップで即座にクラッシュするという恐れなしに、支払える限り、好きなだけ実行させることができます。本当に素晴らしいですね。
したがって、これは単なるタイプミスだと思います。私の仮定で行きます。でも、数学論文のたった1つのタイプミスで、また推測に戻ってしまいます。
解決されたこと
一歩下がって。何を解決したのでしょうか?問題がありました。自己教師あり推論からの問題がありました。不安定なターゲットによるポリシー崩壊と、お見せしたエントロピー損失に苦しんでいました。
この新しい論文の修正は2つでした。モメンタムアンカーが教師を安定化させます。そして、探索、つまり欲しい高エントロピー推論値を単純に保存するフィルタリングメカニズムです。
結果として、人間のラベルなしでベンチマークで最先端を達成し、訓練の不安定性を排除しました。これは素晴らしいことです。
最終的な要点は何でしょうか?私たちは、AIモデルが自己改善する世界に向かっていますが、もちろん、自身の限界内でです。
バカから天才になるとは思わないでください。このMGRPOは、より長い訓練期間にわたって自己改善を安全で持続可能にするために必要なブレーキとステアリングを提供します。美しいですね。
別の視点から見る
ビデオの最後に、まだご覧になっている方は、時々ちょっと楽しんでいることをご存知ですね。「これを別の視点から見ることはできるだろうか?」と言います。
生徒について考えてみてください。これが私たちの現在のAIのポリシーです。生徒は少し野性的です。探検家です。ちょっとカオス的です。
でも生徒は完全に間違ったパターンを幻覚することもあります。この間違ったパターンに興奮します。生徒、つまりAIは、「この悪い数学は実際には良い数学だ」と思うかもしれないカオス次元に走り去るかもしれません。
一人にしておくと、狂ってしまいます。結果は、私たちが自己学習SRTにおけるポリシー崩壊として知っているものです。
主なアイデアは何だったでしょうか?主なアイデアは単純に、遅いメモリを付けて、遅いメモリが付いた投票システムを持つということです。
平均教師AIシステムがあります。これが堅実なモメンタムです。これが安定装置です。これがアンカーです。
このモメンタムAIの振る舞いは、単純に全く探索しないことです。過去10,000ステップにわたる生徒の脳の平均に過ぎません。
生徒と教師AIが一緒に生き延びたものは何でも、素晴らしい、うまくいきました。崖から落ちていません。まだ生きています。
でも、ここでの教師の仕事は、非常に非常にゆっくりと進化することです。教師だったら、生徒が幻覚を見ていると分かります。「そうですね、幻覚を見ているだけですが、幻覚データを推論ストリーム、推論トレースに統合しません」と言います。
とてもシンプルなアイデアであることが分かります。フィルタリングによって、まだAI自体の限界内にある、より高い探索率、より高いエントロピー推論パスが残ります。
単なる狂った高エントロピーではありません。より低いエントロピーより少し上にあるだけで、完全なシステムを安定化させるのに十分です。
ここで平均教師AI、またはこのモメンタムAIを、次のステップに投票することが許されている一種の制度的記憶として見ています。
このAIは、1時間前、1000ステップ前に何が真実だったかを覚えていて、新しい狂ったアイデアについて非常に懐疑的であると言えます。
したがって、著者は本当に狂った幻覚を取り除こうとしています。欠点は、赤ちゃんの一歩で前進することです。小さな、小さなステップです。小さな、小さなステップです。
確率分布があれば、クールバックラベル用語のようなものです。人工知能では、ほとんどの場合、アイデアは常に同じシンプルなアイデアです。
今日は以上です。少し楽しんでいただけたことを願っています。新しい洞察を得られたことを願っています。
とにかく、いいねを残して、チャンネル登録して、メンバーになってみてはいかがでしょうか。とにかく、次回お会いできることを願っています。


コメント