この動画は現在のAI業界における過度な期待と現実のギャップを詳細に分析している。AI分野を一次市場(AI モデル開発企業)と二次市場(AI アプリケーション企業)に分けて考察し、技術革新の側面では訓練データの枯渇や新しい訓練手法の可能性を検討する一方、資本配分の面では数千億ドル規模の投資や人材獲得競争による評価額のインフレーションを指摘している。特にOpenAIが自社評価額と同額の3000億ドルをOracle との契約に投じる状況など、具体的な事例を挙げながらAI バブルの実態を浮き彫りにしている。

AIハイプの現状と市場分析
最近、AIハイプは非常に現実的なものとなっています。一部の人々は、すべての仕事がAIに取って代わられるのは時間の問題だと言っています。一方で懐疑派は、AIは水ぶくれしており、市場の調整が必要だと言っています。
その間、一部のAI専門家は、現在の大規模言語モデルがその限界に近づいている可能性があることを示唆しています。例えば、イリヤ・サツケヴァーは、LLMスケーリングは頭打ちになり、データはAIの化石燃料だと述べました。本質的に、LLMがどのようにスケールするかという現在の軌道が限界に向かっていることを示唆しています。
では、どちらの説が正しいのでしょうか?人々は実質的な何かに楽観主義を根ざすことなく、AIについて過度に楽観的になっているだけなのでしょうか?それとも、AI専門家はAIがどこに向かうかについての予測において保守的すぎるのでしょうか?
これをさらに分析するために、AI業界を2つに分割してみましょう。
一次市場と二次市場の区分
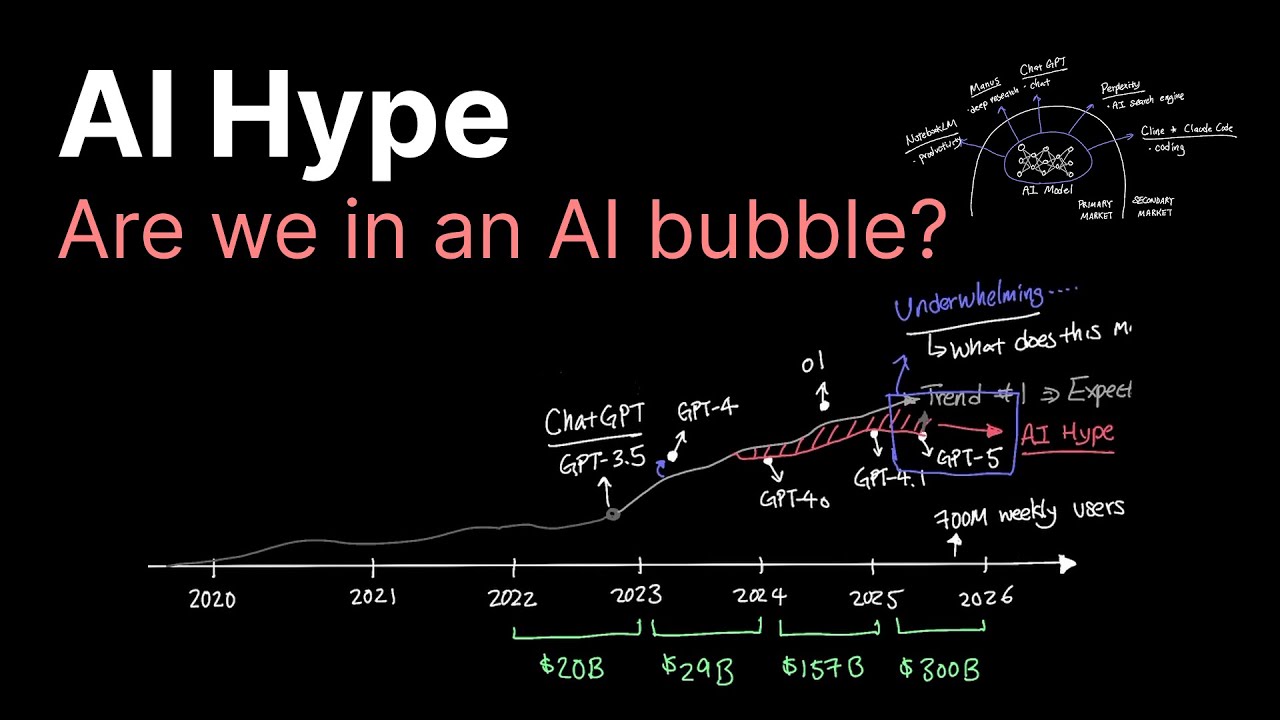
一次市場と二次市場です。一次市場には、実際にAIモデルを革新するAIの最前線にいる企業が含まれます。OpenAI、Anthropic、Gemini、xAI、Mistral、Qwen、Kimiなどの企業です。これらはすべて、最先端のAIモデルを作成、訓練、展開する一次市場の企業の例です。
二次市場は、これらのAIモデルを取り上げて、それらを活用してPerplexity、Cursor、Manis、Notionなどの下流アプリケーションを作成します。ここで本質的に、ウェブ検索、コーディング、深い研究、生産性などのドメインにモデルを適用します。
それでは、一次市場を分析することから始めて、本当にAIバブルが起こっているかどうかを見てみましょう。
ChatGPTの急速な普及と期待値の上昇
OpenAIが2022年11月にChatGPTを一般公開した後、ChatGPTのアクティブユーザーは わずか2か月で1億ユーザーに成長しました。比較すると、Netflixは18年、Facebookは4年半、Instagramは2年半かかりました。ご覧のとおり、一般からの採用速度は非常に速く主流になりました。
ChatGPTは現在、週間アクティブユーザー数が7億人を大きく超えて成長しており、OpenAIは2022年の200億ドルの評価から2023年に290億ドル、2024年に1570億ドル、そして最終的に2025年に3000億ドルに至りました。
年々、人々のAIへの期待も高まり、2つの異なるトレンドが見られるようになりました。AIがどこに向かうかについての人々の期待に従った1つのトレンド、そしてOpenAIによる各モデルリリース後にAIが実際にどこにいたかというもう1つのトレンドです。
モデル性能と期待値のギャップ
例えば、GPT-4モデルはChatGPTからわずか4か月後にリリースされ、一般の期待を上回る大成功でした。そしてその後リリースされたすべてのモデルは、2023年のGPT-4、o1、2024年のGPT-4o、2025年のGPT-4.1、そしてGPT-5などのモデルに対する一般の期待の背景を上回って跳躍しました。
したがって、AI革新の文脈でAIハイプについて話すとき、実際には人々の陶酔的な期待対AI能力の現実の間のこの負のギャップを指しています。AIハイプで最も注目すべき分岐は、OpenAIがGPT-5をリリースした2025年8月に起こり、それはかなり期待外れでした。
GPT-5は私の個人的な経験から時間の経過とともに品質が確実に向上しましたが、GPT-5の期待外れのリリースは、私たちが本当にLLM革新の天井に向かっているのかもしれないという印象を人々の心に確実に残しました。
LLM革新における成功要因の分析
では、ここで尋ねる自然な質問は、LLM革新に関してバブルの中にいるのかということです。ハイプサイクルのどこにいるかを測定するために、OpenAIの過去のモデルでの成功につながった要因を見ることができます。
言い換えれば、過去にAI革新で成功するのに何がつながったのでしょうか?そして、それらの要因は今日もまだ動いているのでしょうか?
過去5年間のLLM革新は、主に4つの明確な要因によって推進されました。モデルのサイズ、訓練データ、計算量、そして訓練技術です。例えば、2022年後半のGPT-3.5モデルと現在のGPT-5のようなOpenAIのフラッグシップモデルを比較すると、モデルのサイズ、訓練データ、計算量の巨大な成長が見られました。
そしてこれは主に、2020年にOpenAIによって提出されたスケーリング則と呼ばれる研究によって推進されました。それは、モデルサイズ、訓練データ、計算量をスケールすれば、予測的にパフォーマンスの改善を求めることができると提案しました。そしてLLMでの多くの初期の成功は、単純にモデルをより大きくし、より多くの質の高い訓練データを集め、計算量を増やすことに起因することができます。
効率的なスケーリングへの転換
しかし、2023年のGPT-4以降、業界はより効率的にスケールすることにより焦点を当て始めるという、わずかに異なるアプローチを見てきました。そしてこの考えは、ほとんどのLLMがそのサイズに対して訓練不足であり、訓練データはモデルのサイズに比例してスケールする必要があると異議を唱えた、2022年のChinchillaのスケーリング則にさかのぼることができます。
したがって、GPT-4のリリース後、訓練データへのより高い焦点が見られました。そしてOpenAIの数十億ドルの評価からの巨大な資金があったため、ボトルネックは計算量やモデルサイズにはありませんでした。彼らはより多く使う余裕があったからです。しかし、LLM革新での真のボトルネックは訓練データに向かって指し始めました。
訓練データの枯渇問題
2024年12月、AIで最も著名な人物の一人であるイリヤ・サツケヴァーは、インターネットデータはAIの化石燃料だと有名に言いました。私たちがモデルを訓練するために使用できる新しいデータが本質的に枯渇していることを暗示しています。
そしてAIモデルを訓練するためのデータが不足しているだけでなく、実際にデータを手に入れることは、人々がデータの所有権で訴訟を起こし、権利とガバナンスに関する訴訟のためにますます困難になりました。
そしてScale AIのような企業から合成データを作成する努力がなされており、AIモデルを訓練するために使用できる高品質のデータを収集しラベル付けするのに大きな役割を果たしました。
合成データの限界と訓練技術の重要性
しかし、AIには多くの分野があります。LLMは言語タスクに使用されます。しかし、私たちはビジョンモデル、ロボティクス、音声、オーディオ、ビデオなどもあります。
そして合成データは、画像生成と分類のためのビジョンモデルなど、一部のドメインでの訓練において確実に有用です。しかし、合成データだけでは大規模言語モデルに巨大な価値を追加しません。それらはより効果的であるために高品質な人間のテキストでの基盤に依存するためです。
したがって、おそらくLLMは本当にその限界に近づいており、人々の期待と現実の間のギャップは真にAIハイプを反映するでしょう。
しかし、訓練データ問題への密接な解毒剤は訓練技術です。言い換えれば、高品質の訓練データを取得することを最大化したとしても、おそらく固定された訓練データでもより効率的な学習を可能にするより良い訓練技術やより良いアーキテクチャさえ思いつくことができるかもしれません。
この感情のための簡単なアナロジーはこれです。2人の異なる人間が聖書を読んで、それに対する2つの異なるレベルの理解に到達することができます。したがって、訓練データが固定されていても、モデルが訓練データからどれほど効果的に学習するかによって、それらの理解は異なります。
訓練技術のブレイクスルー
そして、訓練技術のブレイクスルーがAI革新での巨大な飛躍をもたらしたこれを支持する2つの主要な事例を見てきました。
最初の例は、OpenAIがベースモデルでのファインチューニングを導入し、モデルを単純な事前訓練されたモデルを超えて押し上げる訓練方法として強化学習を使用した時です。
もう一つの例は、本質的にモデルが思考を模倣することを可能にする推論時計算量とペアになった思考連鎖プロンプティングで推論モデルが導入された時です。
ご覧のとおり、訓練技術の進歩はNLPタスクでのAI革新での顕著な飛躍に貢献しています。
資本配分におけるAIバブル
したがって、ここでの重要な質問は、データが不足することが結局のところAIハイプでパニックを引き起こすべきかどうかです。しかし、AIハイプがAI革新側に真に存在するかどうかに関係なく、AIの資本配分側には確実に兆候があるようです。
OpenAIのCEOであるサム・アルトマンは最近、AIはバブルにあり、多くの人が多くのお金を失うと有名に言いました。おそらくAIハイプがAI企業での資本配分方法に真に存在することを示唆しています。
Microsoft、Google、Metaはすべて、AIデータセンターだけに600億から1000億ドルを使うことを約束しました。OpenAIのOracleとSoftBankとの合弁事業は、テキサス州のStargate施設で5000億ドルを使うことが期待されています。
そしてOpenAIは最近、今後5年間の計算能力を購入するためにOracleと3000億ドルの契約に署名しました。そしてOpenAIの最新の評価額が3000億ドルであることを心に留めてください。
したがって、サム・アルトマンは私たちがAIバブルにいると言っているだけでなく、彼らはまたOracle取引で3000億ドル、そして彼らのStargate施設でもっと多くを使っています。
財務的な矛盾
したがって、3000億ドルで評価された企業は、本質的に株式を左右に譲渡することによって法外な率で支出しており、それは株式の希薄化と過度にインフレされた評価につながる可能性があります。
さらに懸念されるのは、OpenAIの年間経常収益が2025年7月時点で120億ドルであることです。彼らはどのお金でこの狂った支出に資金を提供しているのでしょうか?
答えは株主資本ではありません。これは、サム・アルトマンが多くの人が多くのお金を失うと予測していることを考えると皮肉な声明です。しかし、おそらくその声明は彼ら自身の株主にとって自己実現的な予言です。
そしてここに状況をさらに悪くするもう一つのポイントがあります。120億ドルの収益は紙面では素晴らしく聞こえますが、OpenAIはAPIリクエストごとにお金を失っていると噂され、彼らの現金燃焼率もおそらく彼らを巨大な赤字に置いています。
OpenAIと同じ程度ではありませんが、他のAI企業も同様の感情を持っています。Scale AIは年間経常収益15億ドルで290億ドルで評価されています。xAIは毎月10億ドルを失っていると信じられている間、750億ドルで評価されています。Anthropicは年間経常収益50億ドルで610億ドルで評価されています。
MetaとGoogleは、主にAI企業ではなく、一次市場で競争するために毎年数百億ドルを投資する1兆ドル企業の一部であるため、推定するのは少し困難です。
AI人材争奪戦
しかし、ここで物事はさらに複雑になり始めます。AI企業はまた、AIで最高の人材にお金を払うために巨大なプレミアムを使っています。そしてこれは、企業にサインボーナスとして提供される数億ドルの費用をもたらす巨大なAI人材戦争につながりました。
最も注目すべきは、MatとAlexanderがいます。両者ともMetaから彼らの会社に参加するための1億ドルの契約を提供されました。
そして適切な人材を雇うことは確実に多くの時間と手間を引き起こす可能性があります。これが、このビデオをスポンサーしているWovenの30秒の説明をしたい理由です。
私は以前の会社でソフトウェア開発者を雇おうとしていました。そして私がいつも見つけたことは、候補者は常に異なるスキルセットを持っているということでした。そしてコードレビューが本当に得意な人もいれば、システムデバッグが得意な他の人もいました。そして今、AIとエージェンシックプログラミングがあります。
したがって、各役割のためのコーディング評価を思いつくことは、シナリオを構築しフィードバックを与えるために多くの時間と努力を要しました。それは単にプロセスに関わるすべての人にとって楽しいものではありませんでした。
Wovenは、雇用を合理化する人力による技術評価ツールです。したがって、エンジニアを雇おうとしているなら、Wovenは最初の雇用から20%オフで14日間の無料トライアルを提供しています。説明のリンクをチェックしてください。
買収市場での評価インフレーション
したがって、一次市場で企業の数十億ドルの評価での完全なインフレーションが見られるだけでなく、彼らは成長をサポートするためのインフラを構築するために数十億ドルを使っています。また、トップAI人材の雇用に数億ドルを使っています。
確実にこれは私たちがAIバブルにいることを確認しますよね?
状況は、合併と買収、そして他のAI企業を取得するためにどれだけ使っているかを考慮すると、さらに悪く見えます。OpenAIの直接競合であるAnthropicからケーススタディをしてみましょう。
彼らの年間経常収益は最近、10億ドルから50億ドルに急増しました。では、Anthropicは正確にどのようにして収益でこれほど速く成長することができたのでしょうか?
答えは二次市場にあります。そしてAnthropicにとって、それはClaude Codeでした。つまり、一次市場が収益性と収益に関して確実に厳しい状況にある間、収益を解除する真の潜在能力は二次市場にあります。
二次市場への垂直統合戦略
二次市場は、AIモデルが特定の用途に適用される場所です。通常のチャット用のChatGPT、AI検索エンジン用のPerplexity、コーディングエージェント用のCursorとClaude Code、深い研究用のManis、生産性用のNotebook LMなどのアプリケーションを考えてください。リストは続きます。
そして本質的にここでのトリックは、一次市場で上流の基礎モデルを使用して、モデルを二次市場で下流のエージェントにカプセル化し、二次市場に存在するより広いユーザーベースに到達することです。
これは確実に一次市場でAIバブルを回避する最も速い方法の一つである可能性があります。まさにこの理由で、一次市場の多くの企業は現在、人々が直接使用できるプラットフォームを提供することによって垂直統合されるために二次市場に到達しようとしています。
そして二次市場に到達する最も速い方法の一つは、二次市場で競争している企業を買収することです。
二次市場の評価インフレーション
しかし、問題はここで正確には解決されていません。なぜなら二次市場にもハイプがあるからです。そしてこれは、AI企業を買収する際の評価でも大きなプレミアムにつながります。
Cursorは100億ドル近くの評価を持っています。Windsurferは30億ドルで評価され、Notionは100億ドルで評価されています。ご覧のとおり、二次市場に到達することは支払うべき巨大なプレミアムを持っており、これは資本側の問題を悪化させます。
楽観論と懐疑論のバランス
そしてすべてのものと同様に、音楽が止まった時、バランスシートは意味を成す必要があります。しかし今のところ、AIでの楽観論は、特にLLM以外のドメインを考慮すると、まだ優勢な力です。
画像生成用のビジョンモデル、Sora V3用のビデオ生成、ワールドモデルとGenieを見ると、AIの将来が何を保持するかについての一般の興奮を燃料とする発見されている新しい革新があります。
しかし、AIの背後にある評価と資本は、もう一方の側で多くの懐疑論を引き起こしています。そしてAIでの楽観論と懐疑論の間のこの種の綱引きは、AI業界では新しいものではありません。
過去のAI冬との比較
例えば、1973年に戻ると、Lighthill報告と呼ばれる評価がAI業界についてイギリス政府に提出されました。そしてその報告は、AIは人々が期待し約束されたものほど良くないため価値がないことを示唆しました。そしてAIでの革新は遅すぎて、分野全体の妥当性を疑問視すべきです。
そして途中での他の懐疑論は、AI業界を過去に2回AI冬と呼ばれるものに導きました。そして2回のAI冬を生き抜いた後でも、それは様々なレベルで懐疑論に直面しています。
しかし、今日私たちが経験するAIハイプは、過去に経験したものとは大きく異なります。AI革新に関してまた別のAI冬に到達していると信頼できる形で主張できるかもしれませんが、AI企業の過度にインフレされた評価に関しては、確実に未知の領域にいます。
効率的な資本配分の重要性
AI革新に数十億ドルを使うことが本質的に悪いと言っているのではありませんが、真の質問は資本配分です。私たちは資本を効率的に配分しているのでしょうか?
つまり、株主が最終的にAIでの投資を価値のあるものにするために投資収益率を得るのにどのくらいかかるでしょうか?

コメント