中国の研究チームがASI Archという自己改善AIシステムを発表し、人間の介入なしにAIが独自のアーキテクチャを設計・改良できると主張している。このシステムは約2000の自律実験を実施し、106の最先端線形注意アーキテクチャを発見したとされる。しかし一部の専門家からは研究手法に疑問の声も上がっており、再現性の検証が待たれる状況である。
人間がAI研究の障害になっている
中国から新しい論文が発表されて、なかなか大きな主張をしとるんや。もうはっきりと言うとるで。AI研究における最大の問題は人間やと。我々がすべてを遅らせとる張本人やっちゅうことや。
この論文は「モデルアーキテクチャ発見のためのAlphaGoモーメント」っちゅうタイトルなんやけど、もしこれが本当で、他のAI研究所でも再現可能やったら、これは本当に大きな大きな出来事になるで。
AIによるAI研究の進歩
どんどんAIの進歩、AI研究がAIによって行われるようになってきとる。例えばGoogle DeepMindのAlphaGoみたいなもんは、自分が走っとるハードウェアを改良しとるし、自分の訓練プロセスも改良しとる。Sakana AIのDarwin Goalマシンなんかは、自分のコーディング能力を向上させとる。自己改善AIの例がどんどん増えてきとるんや。
今回のやつはちょっと違うで。AIが自分のアーキテクチャを改良させようとしとるんや。つまり、自分をゼロから構築するためのより良い方法を見つけようとしとるっちゅうことや。
AlphaGoとAlphaZeroの教訓
AlphaGoとAlphaZeroの瞬間、Google DeepMindが世界に教えてくれた教訓っちゅうのは、AIは人間が教えるよりも自分で何かを学ぶ方が上手やっちゅうことやった。
自己対戦に取り組んで、自分独自の戦略を発見して、合成データを使うことが多いんやけど、これが人間のエンジニアが取り組んで自分たちで革新しようとするよりもはるかに良い結果を生み出すみたいなんや。
ASI Archの登場
これらの研究者が発表しとるのがASI Archや。彼らが言うには、AI研究のための人工超知能の最初の実証やと。
これはニューラルアーキテクチャ発見っちゅう重要な領域で、AIが独自のアーキテクチャ革新を行うことを可能にする完全自律システムで、この根本的な制約を打ち砕くもんやと言うとる。ここで言うとるのは、自動最適化から自動革新へのパラダイムシフトを導入しとるっちゅうことや。
ASI Archは、アーキテクチャ発見っちゅう困難な領域でエンドツーエンドの科学研究を実施できるんや。これらのモデルのアーキテクチャを改良するための独自のアプローチを思いついて、実験とコードを作成して、それが機能するかどうかをテストしとる。つまり、科学的プロセス全体がこのAIモデルに具現化されて、自分自身を改良しようとしとるっちゅうことや。
驚異的な実験結果
このシステムは約2000の自律実験を実施して、106の革新的な最先端線形注意アーキテクチャを発見したんや。つまり、ニューラルアーキテクチャ、AIの脳における特定のプロセスを改良する方法として1773のアイデアを思いついて、何が機能して何が機能せんかを確かめるためにそれらの実験を実行して、最終的に106の最先端、つまりその時点で最高の新しいアプローチを思いついたっちゅうことや。この場合は線形注意アーキテクチャやけどな。
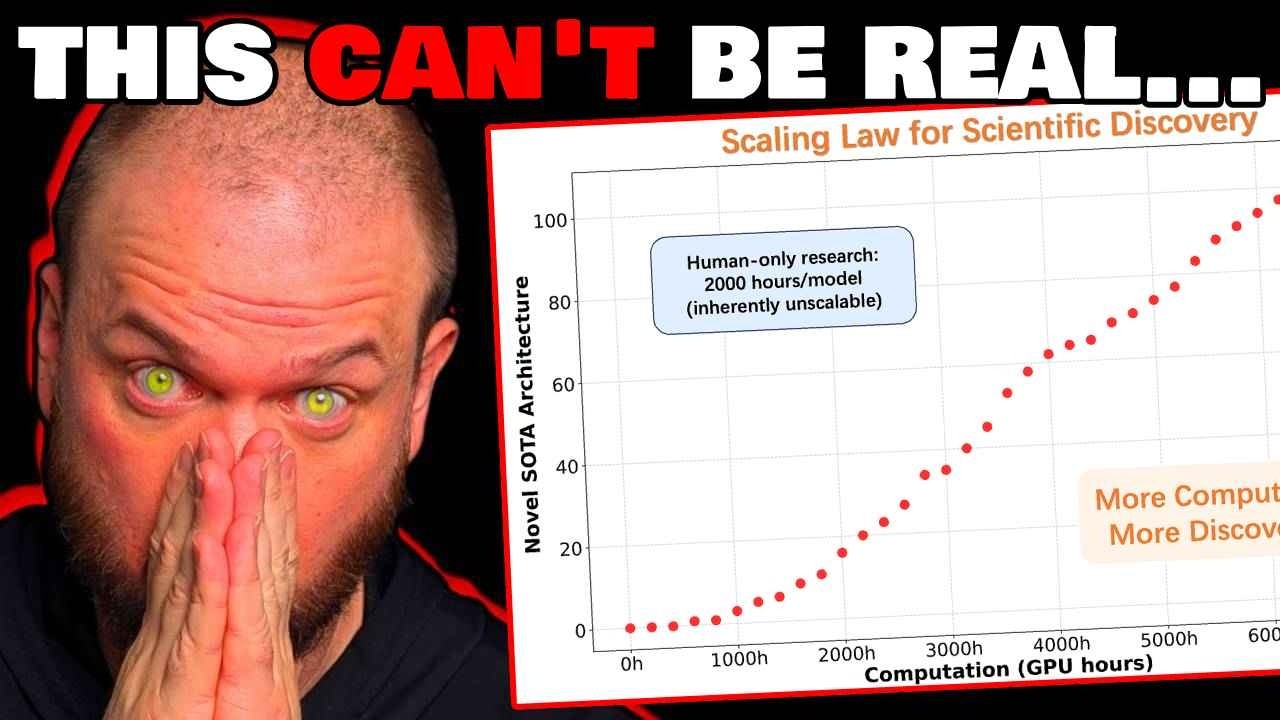
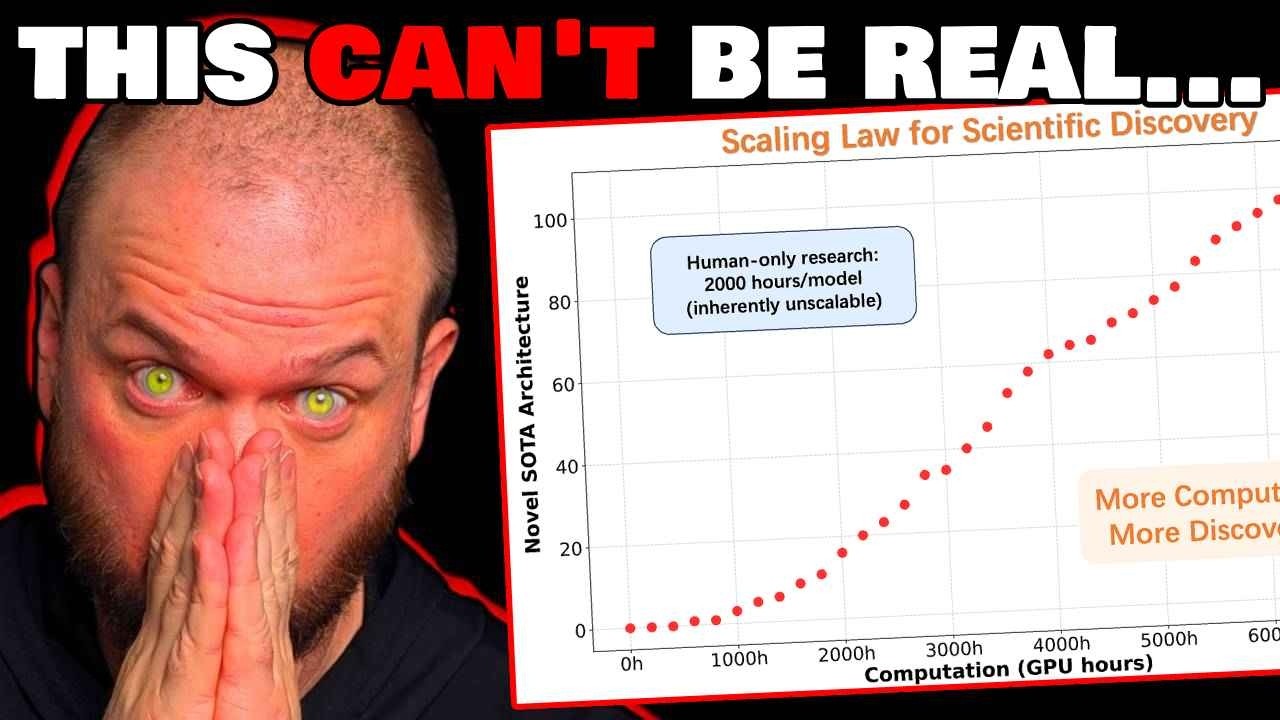
科学的発見のスケーリング法則
また、これらのAIが人間の設計ベースラインを上回っとるのを見とる。これが重要なポイントや。彼らは科学的発見自体に対する最初の経験的スケーリング法則を確立したんや。つまり、過去にこれらのコンピュータを構築するためのスケーリング法則があったのと同じように、より多くの計算資源、より多くのハードウェアを投入すればするほど、これらのモデルは賢くなったんや。
つまり、これらのモデルの改良は単にスケーリングの問題やった。より多くの計算資源、より多くの計算時間、より多くの電力を作り出して、単に物事を大きくすることで改良されたんや。彼らがここで言うとることは、もしこれが本当で、確実に他の研究所がこの研究を再現しようと試みるうちに、これが機能するかそうでないかの確認がすぐに得られるやろうけど、彼らは科学的発見のためのスケーリング法則を持っとるっちゅうことや。
より多くの計算、より多くのGPU時間をこの問題に投入すればするほど、アーキテクチャが良くなるんや。
技術改良の新しいパラダイム
我々が改良したいあらゆる人間の技術について考えてみよう。これは薬の効果性、車が一回の給油や電力でどれだけ遠くまで行けるか、衝突時の車の安全性、太陽光パネルが太陽光線を捉えてエネルギーに変換する効率性などが含まれる。
通常、これらは非常に困難で高価で時間のかかるプロセスで、多くの非常に賢いエンジニアが大量の研究と努力を投入して、少しずつこれらのものを改良し、最適化しようとしとるんや。
これが示しとるのは、もし本当やったら、これまでのやり方、パラダイムが完全に変わってしまうっちゅうことや。なぜなら、その改良、技術的進歩が単により多くのGPU時間、より多くの計算の関数になるからや。
これらのAIシステムにより多くの力、より多くのNvidiaチップを与えてブーンと動かせば、イノベーションを生み出すんや。科学的発見を生み出すんや。もう一度言うけど、これらのスケーリング法則が成り立つかどうかを確認せなあかんけど、多くの異なる企業から同様の結果を見とるんや。
Google DeepMindは多くのalpha evolveや他のalphaシリーズでこれに似たものを示しとるし、OpenAI、xAI、Anthropic、これらの創設者たちも皆、こういったものについて話しとる。我々が知る限り、これはフィクションやない。これが物事の展開の仕方なんや。
ASI Archの4つのモジュール
ASI Archに組み込まれた4つのモジュールの概要を見てみよう。左側には認知ベースがある。これは既存の知識、我々が持っとる既存のデータ、過去に試して成功したか失敗したかのものみたいなもんや。
ここで見えるように、アーカイブペーパーズウィズコード、ハギングフェイス、そして機械学習を改良したり、ニューラルネットを改良したりするために実行された様々な実験について語るこういった論文をホストしとる他のすべての場所を検索しとるみたいや。
ここには抽出器がある。これは大規模言語モデルやと思うけど、それらすべてのものを読んで、次のステップに必要なすべての重要なポイントと詳細を抽出しようとして、それが研究者に渡されるんや。
研究者は新しい潜在的革新、仮説を提案して、その仮説が真かどうかを検証するために必要な実験を実行するためのコード、実験コードを作成するんや。そして、それが新規性と有効性についてチェックされる。つまり、これは以前に行われたことがあるかどうか、既存の研究を複製しとるのか、それとも新規なのか、全く新しい発見領域なのかっちゅうことや。そして有効性、つまり意味があるかどうかや。これは実行中のループになっとる。
その出力がエンジニアAIに渡される。エンジニアがコードを実行して、それに対して2つの異なることが行われるみたいや。一つは実際にLLM判定者に渡されるんや。LLM判定者のシステムプロンプトは多分「あなたは以下の項目についてこのコードを評価することになっとる判定者です」みたいな感じやろう。
ここでは効率性、新規性、複雑性について話しとるみたいや。それでコードを通して評価して、何らかのランキングシステムを与えて、何らかのスコアを返すんや。同時に、同じコードが実際の訓練環境でも実行されるみたいや。これらのものの組み合わせが適応度スコアや。
この表現の一部はちょっと奇妙に感じるけど、これがそのプロジェクト、その仮説に与えられる最終スコアなんや。これは非常にうまく機能したように見える10点満点中10点の実験なのか、それとも単に機能しないか、新しくないか、あまり効率的でないか、何も改良しないから10点中1点なのかっちゅうことや。
そのスコアが最終モジュールに渡される。これはアナリストモジュールで、今度は全体の要約を作成して、何が機能して何が機能せんかを示して、それを研究者にフィードバックするんや。
進化的探索と学習プロセス
これがalpha evolveやDarwin goalマシンの進化的探索に似とるなら、どういうものが機能するかのパターンを見つけようとするやろう。特定のアプローチがうまく機能する傾向があるなら、そのアプローチをもっとやろうとするんや。
別の考え方をすれば、これはウェブ上で利用可能な既存の知識、他の人が行った作業から学習しとるっちゅうことや。これはもう少し自己再帰的なもんや。
これは自分自身が発見したものから学習しとるんや。このシステムが実行されて学習しとる間、これらが発見事項で、それが研究者にサイクルバックされるんや。
パレート原理の発見
ここで本当に興味深い発見は何や?興味深いことに、パレートの原理または80-20の法則を聞いたことがあるかもしれん。80%の結果、アウトプットが20%のインプットからしか来んっちゅうやつや。
ブレークスルーの大部分は特定のアプローチから来とる。これらはランダムやない。ランダムに分布されとるわけやない。非常にうまく機能する傾向がある特定のものと、あまりうまく機能せん可能性がある他の特定のものがあるんや。
ここで青い線が見える。これらは1667の提案された新しいアーキテクチャのうちテストされたもので、赤は改良されることが発見されたもの、機能するものや。
一般的に、このすべてのものは失敗して、左側のゲーティングシステム、温度制御、畳み込みアーキテクチャ、適応フロア初期化戦略みたいな特定のアプローチがより機能する可能性が高かった。これらは貴重な結果をもたらす可能性がはるかに高かったんや。
ここで言うとるように、データはゲーティングメカニズムや畳み込みみたいな確立されたコンポーネントに対する明確なシステム全体の好みを明かしとる。最高クラスの結果をもたらさなかったノンステートモデルは、より深刻なロングテール問題を示しとる。つまり、新しいコンポーネントのより広範な探索はあまり効果的やないっちゅうことや。
パレートの原理、80-20の法則がまた当てはまるんや。これは自動AI研究においてもそうやし、自然界で有機的に見つかる他のほとんどの分布と同様やで。
パレート原理の普遍性
これに馴染みがないなら、これは人生やビジネスの様々な側面で真実な観察なんや。ビジネスにとって、収益の大部分は顧客の比較的小さな割合から来とる。マーケティングにとって、あなたが行うマーケティング全体の小さな部分が、リードの大部分、あなたのリードと売上の不釣り合いな量を生成する。
もしビジネスのカスタマーサービスで働いたことがあったり、カスタマーサービスをせなあかんかったことがあるなら、これが真実やっちゅうことを知っとるはずや。顧客の20%が苦情やサポート要請の80%を占めとる可能性がある。あなたは多分今、彼らのことを考えて、頭の中で視覚化しとるやろう。あなたの問題の半分を生み出すあの一人と、あなたの日常活動の20%があなたの成果の80%を占めとるかもしれん。
これは完全に理解したら一種のトリップや。あなたが追求しようとしとる目標に対して、あなたがすることの大部分は効果的やない。あなたの総努力のほんの小さな部分が結果の大部分を生み出すんや。それが何かを分析して理解できれば、多分もっと少なく働いてもっと多くを達成できるやろう。
ここでも同じように真実や。上位4つの結果を計算すると、発見されたすべての新しい発見、最先端の新しい成果のうち、44%がそれらの上位4つのアプローチに含まれとる。44%や。
コンポーネントの起源分析
ここで私にとって本当に大きく飛び出してくるもう一つのことはこれや。これらのもの、これらのアプローチはコンポーネントと呼ばれとる。
マーケティングキャンペーンをやっとるとしたら、機能するかどうかをテストする可能性がある特定のアプローチやコンポーネントがあるよな?テレビ広告を出すこと、既存の顧客に友人を紹介してもらおうとすることは、多分非常にうまく機能する例や。
何らかのシャーマン的な儀式、雨乞いダンスみたいなことは多分あまりうまく機能せんやろう。
それらの新しいブレークスルー、その新規の改良はどこから来たんや?そのコンポーネントはどこから来たんや?なぜなら、このASI Archフレームワーク全体の概要を心に留めておくと、ここで我々は既存の知識をインターネットでマイニングしとるみたいなもんやから。アーカイブや論文みたいなものをチェックして、オッケー、他の人が既にしたことは何かを見とるんや。
中央では、それをテストするためのプロセスがある。しかし右側では、我々が既に発見した情報をマイニングしとる。我々が行ったすべての実験、我々が収集したすべてのデータを洞察のためにマイニングして、それらの洞察をここに供給しとるんや。認知は既知のもの、誰かが別の科学論文で既に理解したもんで、これは我々の新しい知識、このプロセスが作成した我々の新しいデータをマイニングしとるんや。
モデルギャラリー、これらは新しく改良された最先端のアプローチやコンポーネントについて、認知が48.6%を占めとった。既存の論文をマイニングすることが、新しく改良された結果、勝利の48.6%を占めとったっちゅうことや。既存のデータを梳いて実験を設定すること自体が、かなり大きな飛躍や。
6%だけが真にオリジナルやった。つまり、経験からの以前の実験から来たわけでも、他の人の研究からの認知から来たわけでもない。オリジナルやった。それでも非常に印象的やろ?しかしより小さな割合や。
しかし、私が思うにさらに印象的なのは、44.8が経験から来たっちゅう事実や。
実験を実行して分析して、何がうまくいって何がうまくいかなかったかを理解して、どのアプローチがより頻繁により良く機能する傾向があるかを理解して、それからそれらをもっとやろうとしたり、我々がこれらの実験を実行することから得た何らかの洞察からの何らかのデータを引き出すこと。その経験を引き出すことがブレークスルーの46%を占めとったんや。
これは大きなことみたいや。なぜなら、このループが信じられないほどうまく機能しとるみたいやから。これは単に我々が以前に持っとった人間の知識を取ってそれを洗練しとるだけやない。自分の実験、自分の研究に基づいて独自のものを開発しとるんや。
自己改善AIの未来
これは次世代の自己改善AI研究、自動AI研究のアプローチに対する明確なロードマップを提供して、他の研究所が自分たちでこういうシステムを作り上げるための再利用可能なレシピを提供するんや。
このチャンネルで何度も何度も参照してきたこの画像を、もう一度確認のために見てみよう。これはLeopold Aschenbrandによるもので、ある時点で2027年2028年に、ここで見たようなAIシステムが全体的に人間の研究者よりも優秀になる自動AI研究というこの変曲点にぶつかると信じてると言うとった。
考えてみると、それは我々が自動化できる最大のものや。我々のメールに返信したり、コードを書いたりするのを自動化するのは素晴らしいことやろうけど、最大のドミノは何や?もし我々がそれを自動化すれば本当に世界を変えるであろう一つのことは、AI研究やろう。そうすれば再帰的自己改善AIを持つことになって、それがLeopoldや他の人たちが呼んでいるようにこの知能爆発につながるからや。AIが賢くなればなるほど、自分自身をより賢くすることが上手になって、それがまだわからんけど複合プロセスの一種につながるんや。でも、きっと我々はみんな見つけることを非常に楽しみにしとるし、あなたの世界観によっては楽しみやったり恐れやったりするやろう。
専門家からの疑問の声
今、この論文が真実かどうかはまだわからんっちゅうことを理解することが重要や。かなり大きな主張をしとるからな。これはMetaのLucas Bayerや。以前はOpenAI、DeepMind、Google Brainなどにおった。
重要なのは、Lucasは魚が嫌いやっちゅうことや。そして彼がこの論文について言うたことはこれや。魚臭いと。実際、技術的には彼はそう言うてない。彼は「もし魚臭いなら、それは多分魚や。私は魚が嫌いや」と言うて、これが真実やない理由のヒントとしてこれを投稿しとる。
赤でハイライトされとるのは「さらに、ベースラインより10%以上低い損失を持つアーキテクチャは非公式リークがあると見なされ、即座に破棄される」や。
そのハイライトされた部分は何を意味するんや?基本的に、何らかのテストを成功させたい場合、データが仮説を支持してほしい場合で、大体はそうなるけど、単に合わん悪いポイントがいくつかあるような場合、それを機能させる素晴らしい方法は、仮説に合わんポイントを投げ出すことや。
ここで彼らが言うとるのは、ベースラインより10%以上低い損失を持つ特定の結果は、単に投げ出されるっちゅうことや。なぜその数字を選んだんや?これは実験の大胆な主張に適合せんものを投げ出したかっただけやっちゅう事実を指摘しとる可能性がある。わからん。
もっと結果が返ってくるのを待つことになる。これまでのところ、何人かの人がこの論文の問題を指摘しとる。論文の著者の何人かは良い学術的評判を持っとって、他の多くのものを発表した人もおる。Lucasは多分彼らが単に引用を集めとるだけやと言うとる。見逃すことへの恐れや。
この論文が爆発的に広まって、彼らのキャリアにとって非常に良いものになる可能性が5%あるかもしれん。
確実に、あなたたちの何人かは既に心を決めとって、多分あなたたちが正しいかもしれん。しかし重要なことは、これがオープンソースやから人々がそれを再現できるっちゅうことや。人々が自分でそれが機能するかどうかを確認できるんや。確実に、もし真実やったら大きなことみたいや。
そうでなければ、無意味や。しかし、多くの人がこの方向で研究して、結果を得て、成功を収めとることを示唆する似たようなことをこの分野で見てきた。だから、このような正確なアプローチや将来の似たようなものが、その再帰的AI自己改善をもう少し破ることに成功することに驚かんやろう。
それに賭けることはせんやろう。そんなところで、私はWes Rothや。


コメント