 AIベンチマーク
AIベンチマーク AI Models about to BREAK the markets(市場を破壊寸前のAIモデル)
この動画は、AI安全性の専門家ダン・ヘンドリックスが紹介したProfit Arenaベンチマークについて解説している。同ベンチマークは、AIモデルの予測能力を実世界のイベント予測で測定し、GPT-5やo3といったOpenAIモデルが予測市場...
AIベンチマーク  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  RAG
RAG  RAG
RAG  OpenAI・サムアルトマン
OpenAI・サムアルトマン  GPT-5、5.1、5.2
GPT-5、5.1、5.2 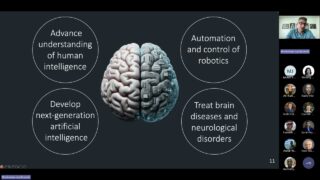 脳科学・意識・知性
脳科学・意識・知性  RAG
RAG  AIエージェント
AIエージェント  数学
数学  AI研究
AI研究  Anthropic・Claude・ダリオアモデイ
Anthropic・Claude・ダリオアモデイ  AGI・ASI
AGI・ASI  AI研究
AI研究  LLM・言語モデル
LLM・言語モデル  AIエージェント
AIエージェント  AIベンチマーク
AIベンチマーク  AIエージェント
AIエージェント  AI研究
AI研究  AI研究
AI研究  AGI・ASI
AGI・ASI  LLM・言語モデル
LLM・言語モデル  SakanaAI
SakanaAI  LLM・言語モデル
LLM・言語モデル  LLM・言語モデル
LLM・言語モデル  LLM・言語モデル
LLM・言語モデル