 AI競争
AI競争 Gemini 3とChatGPT 5.1の真の違い─コンテキスト対タスク
本動画は、ChatGPT 5.1とGemini 3という2つの最新大規模言語モデルの本質的な違いを、プロンプティング手法の観点から詳細に解説したものである。多くの人々がモデル自体の性能について語る一方で、モデルに与える「入力の混乱度」につい...
AI競争  AI画像
AI画像  AI画像
AI画像  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet 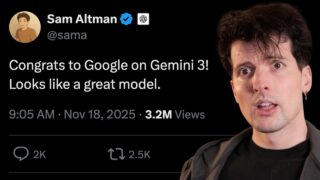 Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  未来予測
未来予測  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  世界モデル・マルチモーダル
世界モデル・マルチモーダル  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  AI競争
AI競争  OpenAI・サムアルトマン
OpenAI・サムアルトマン  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  AI画像
AI画像  AI活用・導入
AI活用・導入  AI画像
AI画像  AIコーディング・Vibe-Coding
AIコーディング・Vibe-Coding  OpenAI・サムアルトマン
OpenAI・サムアルトマン  WWW、Webブラウザ
WWW、Webブラウザ  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  Google・DeepMind・Alphabet
Google・DeepMind・Alphabet  AGI・ASI
AGI・ASI  AIニュース
AIニュース  AI研究
AI研究  AI入門
AI入門  中国
中国  中国
中国  AI活用・導入
AI活用・導入  GPT-5
GPT-5  世界モデル・マルチモーダル
世界モデル・マルチモーダル  AIニュース
AIニュース