 AIアライメント・安全性
AIアライメント・安全性 AIの「ゴッドファーザー」が警告:「あなたは何が来るのか全く分かっていない」
AIの第一人者であるジェフリー・ヒントンが、AI開発の加速と将来のリスクについて警鐘を鳴らす。国家間・企業間の競争により減速は不可能とし、イリヤ・サツケヴァーの安全研究への転身に言及しながら、AI安全性の課題を論じる。産業革命が筋肉を置き換...
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性 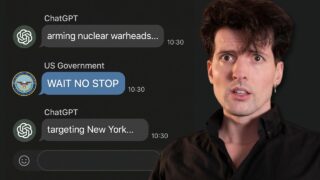 AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性  AIアライメント・安全性
AIアライメント・安全性