拡散モデルは画像・動画・音声生成において最先端の性能を誇るが、理論的には訓練データを記憶化すべき状況でも実際には汎化する不思議な性質を持つ。École Normale SupérieureのGiulio Biroli教授らの研究は、この謎に理論と実験の両面から迫る。拡散モデルの生成過程は、ノイズから構造を作り出す逆向きの確率過程として理解できるが、完璧に最適化すれば訓練データを丸暗記するはずである。しかし実際には、訓練データ数を増やすと記憶化から汎化へと遷移する。ランダム特徴モデルの解析により、この現象の鍵は訓練ダイナミクスにあることが判明した。パラメータ空間での勾配降下は、まず汎化スコアを学習し、記憶化スコアへの収束には訓練データ数に比例する極めて長い時間を要する。この暗黙的な正則化効果こそが、拡散モデルが次元の呪いを逃れ、実用的なデータ量で汎化できる理由である。
拡散モデルと記憶化問題の導入
それでは始めましょうか。簡単に紹介させていただきます。数学と機械学習に関するワンワールドセミナーへようこそ。お集まりいただきありがとうございます。本日はÉcole Normale SupérieureのGiulio Biroli教授をお迎えできて大変光栄です。特に理論物理学研究所の教授であり、私の理解では機械学習のEllisプログラムのフェローでもあります。
本日は拡散モデルと記憶化のトピックについてお話しいただきます。それではGiulio、どうぞよろしくお願いします。
ありがとうございます。拡散モデルにおける記憶化に関する私たちの研究についてお話しできて嬉しく思います。共同研究者を紹介しますと、Tony Boniereは以前ENSのポスドクで、現在はパリ南部のCNRS研究員です。Rafael RanはENSの博士課程学生、Mark Mazarはボストン大学の教授です。
では、簡単なイントロダクションから始めましょう。多くの方が拡散モデルについてご存知だと思いますが、同じ認識を共有しましょう。拡散モデル、より一般的にはスコアベースモデルは、現在、画像、動画、音声、3Dシーンの生成において最先端の技術となっています。
こちらは拡散モデルによって作成された、実在しない人物の画像の例です。曲を作ることもでき、最近では動画も作成できます。拡散モデルへの関心は、民間企業の観点からも大きなものがあります。テキストから画像への変換など多くの応用があります。こちらは例ですが、今ではもう古い図かもしれませんが、私が「怒った鳥」というプロンプトを書いただけで、このような結果が得られます。
確かに鳥のように見えますし、幸せそうには見えません。つまり、要求した条件付き画像を正確に生成することに成功しています。これは民間企業による応用の一例です。特に私のような物理学者にとって非常に興味深いのは、科学分野での応用がますます増えていることです。
天気予報においては、従来の最良の予測アルゴリズムに匹敵するようになってきています。複雑系の構成を生成するのにも非常に興味深いものです。実在しない人の顔に対応する構成を作成できるのと同じように、物理学では例えば乱流において、極めて複雑で長距離相互作用やマルチスケール特性を持つ構成が存在することが知られています。この論文で示されているように、生成モデルは訓練後、これらの複雑な物理現象に見られる複雑な特徴をすべて再現できることが示されています。
拡散モデルの基本原理
科学応用としてもう一つ非常に興味深いトピックは、科学における大きな革命の一つが物理系をシミュレートできることであり、特に物理系の平衡構成をサンプリングできることです。
サンプリングを行う方法は、例えばモンテカルロ・マルコフ連鎖や分子動力学を使うことです。しかしこれらは物理的な動力学の一種であり、実際には生成モデルから来る技術を使ってサンプリングする別の方法があるかもしれません。
これは本当に新しくて非常に刺激的な研究方向であり、近年多くの研究がなされています。さて、これが拡散モデルやスコアベースモデルを使ってできることです。では、この技術と拡散モデルのイントロダクションから始めたいと思います。
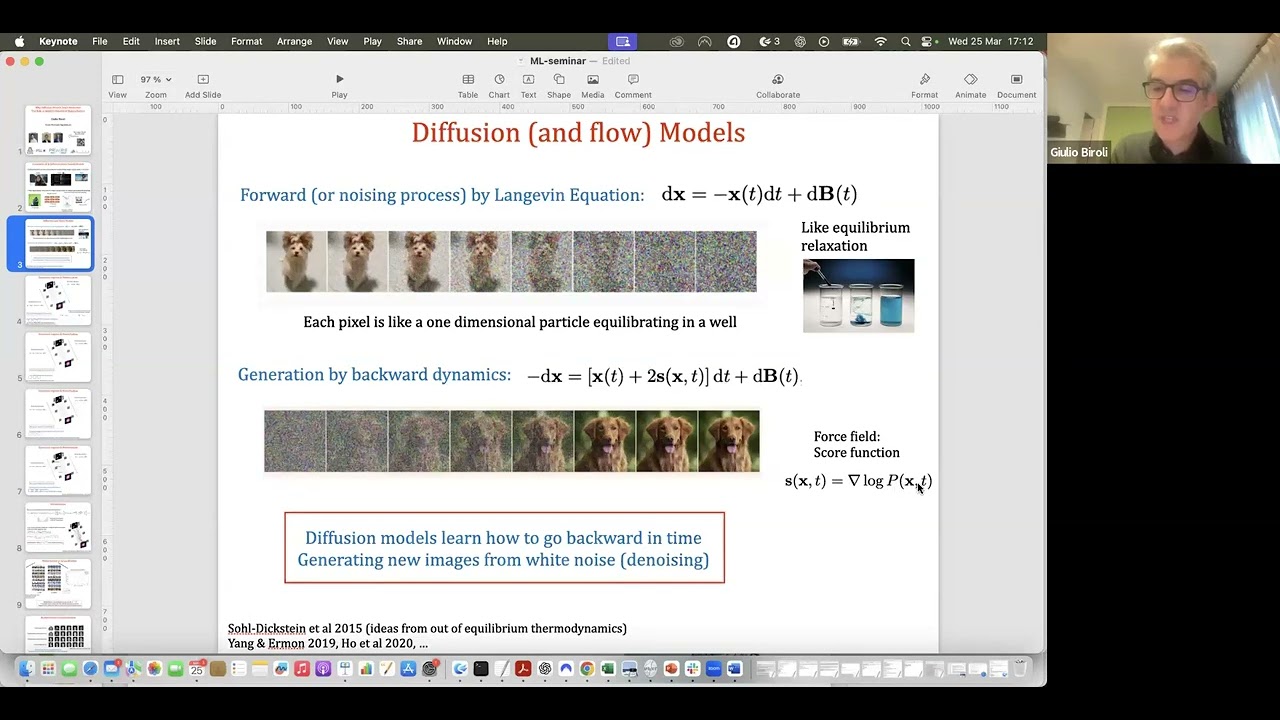
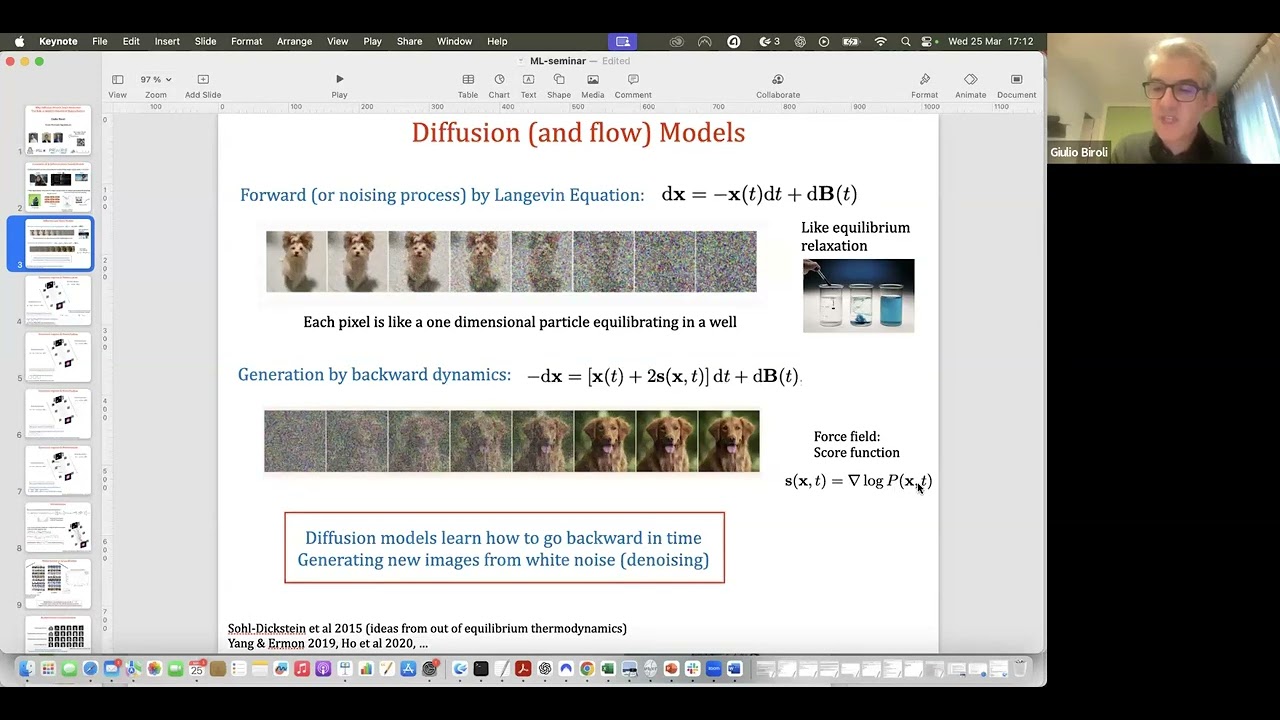
拡散モデルは2つのプロセスに基づいています。順方向プロセスと逆方向プロセスです。順方向プロセスは様々な見方ができます。ノイズ付加として見ることもできますし、特に私のような物理学者にとっては、ランジュバン方程式として見るのが非常に良い方法です。
画像の各ピクセルについて、ここで定義された確率微分方程式を実行します。これはランジュバン方程式またはオルンシュタイン-ウーレンベック過程と呼ばれるものです。時間の経過とともに、各ピクセルがこの動力学方程式を使って進化していきます。長時間、実際にはそれほど長くなく時間が10程度のオーダーで、この確率動力学微分方程式によって誘導される定常過程に到達します。定常過程は単にガウス分布です。
つまり、この方程式を実行する各ピクセルがガウス変数に変換されるということは、この順方向プロセスが例えば犬の素敵な写真をホワイトノイズに変換しているということです。これは物理学者として非常に似ています。これが実際に私がこれを始めた理由の一つなのですが、このランジュバン方程式の考え方や実行は、平衡状態に緩和することが知られており、物理学における古典的な例がこれです。インクを水の入ったグラスに入れると、長時間待つとインクがどこにでも拡散します。これは全く同じ物理過程であり、自然界で平衡への緩和を説明するために使わなければならない物理方程式の種類なのです。
逆向きダイナミクスによる生成
さて、非常に注目に値すると言えるのは、拡散モデルや一般的にスコアベースモデル、フローマッチングなどができることです。彼らはこの動力学を逆転させることができるのです。
つまり、初期構成から平衡状態への物理的動力学があり、彼らはそれを時間反転させるのです。この過程を時間反転させることができれば、ガウスホワイトノイズの新しい構成を取り、もし過程を動力学的に反転できれば、ホワイトノイズから元の分布の新しいサンプルに行くことができます。元の分布は実際には知らず、そこからのデータだけを知っているのですが。
では、どうやって戻るのか。実際、戻るにはまた別の確率微分方程式、別のランジュバン方程式を使うことができます。見ていただくと変わるのは、この力、力場のこの部分が反転されることです。ここではプラス記号になっており、ここではマイナス記号でした。そして最も重要なことは、スコアと呼ばれる新しい力場があることです。これが動力学を時間的に逆方向に駆動することができるのです。
この力場には何があるのでしょうか。確率過程の理論では、それが何であるかがわかっています。時刻tにおけるp(x,t)の対数の勾配です。p(x,t)は順方向プロセス中の時刻tにおけるxの確率分布です。
少し説明させてください。逆方向プロセス中にここにいるとき、時間的に逆方向に進むために使わなければならない力場は、方程式の右辺にxを置き、スコアを得るためには、順方向プロセスに沿って時刻tに到達したxの確率が何であったかを見て、対数を取り、勾配を取る必要があります。これが時間的に逆方向に進むために使わなければならない力場の鍵となる要素であるスコア関数を与えてくれます。
これは動力学の観点からの説明ですが、単にノイズ付加とノイズ除去として見ることもできます。これは単にこのプロセスにノイズを付加しているだけで、ノイズ除去の方法を学び、ホワイトノイズをノイズ除去する方法を学べば、これはノイズ除去プロセスなのです。
拡散モデルの研究の歴史
さて、この拡散モデル生成モデルに到達した研究の流れは多くあります。物理学から来たものがあります。2015年のSohl-DicksteinらがいますKalは実際、物理学で非平衡熱力学または確率的熱力学と呼ばれるものについて考えており、それを使って新しい機械学習生成モデルを作る方法を考えていて、このアイデアに至りました。そして理論計算機科学から来た並行する流れがあり、2010年頃から本当にこのモデルが使われ始め、真に最先端になりました。
さて、これが拡散モデルのクラッシュコースです。記憶化に入る前に、まず生成プロセス自体について、そして私たちが行った以前の論文についてお話ししたいと思います。
最初に理解したかったのは、この逆向き動力学中に何が起こるかです。特に、ホワイトノイズから多くの構造を持つ画像、曲、動画に行きます。どのように構造を作るのか、ホワイトノイズから構造がどのように現れるのかを理解したかったのです。
そこで行ったのは、数値実験と簡単な分析的研究の組み合わせで、特にガウス混合を研究しました。
生成過程の異なる段階
理解したことは、逆向きプロセス、逆向き動力学中に動力学の異なる段階があるということです。ここに小さな動画があります。うまく動くといいのですが。1つのガウス分布から始まり、逆向きプロセス中に2つのガウス分布に行きます。
これは生成モデルでターゲットにしたい確率分布です。3つの点から始まり、時間を逆行する3つの軌道があります。ガウス混合を使って理解した最初のことは、そして実際のデータでテストしたのですが、もちろん動力学の最初はガウスホワイトノイズだけですが、ある点で実際にデータの最も重要な特徴が形成される最初の段階があります。
想像してください、ここに例があります。熊と海岸の画像でモデルを訓練したと想像してください。何が起こるかというと、軌道が最終的に海岸を生成するのか、それとも熊を生成するのかを選択する最初の段階があります。
つまり、これは本当に主要な特徴であり、一種の動力学的相転移または相転移があり、軌道が塊を形成し、一部の塊は一方向に行き、他の塊は他の方向に行きます。これは実際、ガウス混合の場合、ガウスを分離する方向を見ると理解できます。そこには、この動力学を粒子動力学として考えると、粒子がこのようなポテンシャルの中で動いている最初の段階があり、これは単にガウス粒子に対応しますが、時間の経過とともにこのポテンシャルが変化し、二重井戸になります。この二重井戸が本当に軌道を分離するものなのです。
時間を逆行するほど、実際にこの2つの井戸が深くなり、離れていき、軌道を一方のクラスまたは他方のクラスに向けて本当に駆動します。
これが逆向き動力学中の最初の段階です。次に、軌道は一緒にあり、この辺りで分離し始め、こちらに行くものとこちらに行くものが見えます。分離したら、画像の高周波部分すべてを生成し始めます。
例えばここで見ることができます。海岸を与えることに決めたら、よりよく定義された海岸が得られ、ここではよりよく定義された熊が得られます。そして、私たちが行ったこの分析はすべて、経験的スコアまたは完全なスコアと呼ぶものを使っていました。つまり、無限に強力で、経験的損失を本当に最適化していた場合にシステムが使うスコアです。
記憶化現象の発見
これを使うと、最後の最後に記憶化が得られます。これはどういう意味かというと、軌道を見ると、最初の段階で塊に分離し、高周波を作り、そして最後の最後に、実際に力場、このスコア、この経験的スコアが、軌道をモデルの訓練に使ったデータに向かって非常に強く押す力に対応します。
これは拡散モデルの場合に行ったことですが、他の人々も研究しており、特にRiccardoも動力学的視点から、特にODEについて研究しました。明らかなことは、そしてこれがこの問題を興味深くするパズルの一つだと思いますが、すべきことをすべて行えば、つまり可能な限り完璧に最小化し、可能な限り最も強力なモデルを使って経験的スコアを最小化すれば、システムは記憶化します。
新しいデータを与える代わりに、訓練に使ったデータを返すのです。ある意味では、拡散モデルが機能するのは、本来あるべきように機能しないからです。実際には記憶化せず汎化するのです。これは私が述べた3つの異なる段階のまとめです。
最初にクラスの形成、次に高周波、そして最後の最後に経験的スコアを本当に使えば記憶化です。では、記憶化についてもっと詳しく入り、経験的スコアと記憶化の背後にあるパズルについて詳しく説明したいと思います。
経験的スコアとは何かに戻りましょう。スコア関数を学習しなければならないとき、原則として始めるのはこのように定義される損失です。ここにスコア関数のモデルがあります。これは多くのパラメータの関数を意味し、一般的にはディープニューラルネットワークで表現され、UNetやTransformerである可能性があります。そして、パラメータを見つけるために最小化したいのは、モデルとp_t(x)のlogの勾配との間の平均二乗損失です。
これは持っていないものです。データしか持っていないからです。しかし、部分積分を行い、ここにあるこの平均を経験的平均で置き換えれば、実際に変換できます。ここにある経験的スコアマッチング損失を得ることができます。
ここではすべてのデータの総和があり、データμについて時刻tの位置マイナス実際には時刻0の位置かけるe^{-t}割る1 – e^{-2t}があります。実際には、これをノイズで書き直すこともできます。ノイズ割る1 – e^{-2t}の平方根という等価な表現があります。これは与えられた時刻tで行われ、すべての時間で積分でき、時間を再スケジュールできますが、大まかにはこれが実際にスコア関数に対応するパラメータを得る方法です。この経験的損失を最小化するだけです。
経験的スコアと記憶化のパズル
パズルは、言っていたように、関数空間で見ると、この損失には最小値があり、最小値は経験的確率分布のlogの勾配です。これは順方向プロセス中に時刻tで到達する確率分布であり、これは単にガウス分布の総和です。
なぜでしょうか。少し考えてみれば、n個のデータから始めるので、時刻0の初期分布は単にデルタピークの総和であり、これらのデルタピークのそれぞれが順方向プロセス中にノイズが加わります。だから単にある幅を持つガウス分布になり、これがデルタピークの総和である初期確率分布に対応する正確な確率分布です。
ある意味では、モデルが持っているのがn個のデータだけであることしか知らない場合、真の確率分布がデルタピークの総和ではないことを知らないので、うまく機能すれば、つまり最適化が可能な限りうまく行われ、モデルが可能な限り強力であれば、原則として、この勾配log p経験的である経験的スコアを見つけるでしょう。
この経験的スコアを力場として逆方向に使えば、最後には初期データだけを生成することになります。私たちが研究した興味深いことは、この確率分布はある幅を持つガウス分布の総和です。ガウス分布が重なり始めれば、実際にこの確率分布は滑らかになり、少なくとも典型的なデータでは、無限数のデータで得られる真の基礎となる確率分布と等価になります。
しかし問題は、実際にこのガウス分布の幅が時刻0に近づくほど小さくなるため、この重なりを持つため、つまりこの確率分布が元の確率分布の良い表現であるためには、次元の指数関数的にスケールするデータ数が必要です。これは次元の呪いが現れる別の方法です。
つまり、すべての時間または生成時間でこの記憶化問題を避けたい場合、次元の指数関数的なデータ数を使うべきですが、これは明らかに実際には行われていません。これすべての要約は、最初のことは、すべてを可能な限り最も強力なモデルと最良の最適化で行った場合、使用するデータ数が次元の指数関数的でない限り、常に記憶化すべきです。
これは実際には見られないので、大きな問題は、なぜ何が起こっているのか、なぜ実際に記憶化が見られないのかということです。私が見られないと言うとき、部分的には場合によっては見られますが、問題は私が言っていたほど深刻ではありません。
実際の記憶化と汎化の遷移
実際に記憶化対汎化の観点で何が見られるかお話ししましょう。こちらは私たち自身で行った例ですが、実際にこの記憶化と汎化の間の遷移を研究した人は他にも多くいます。
例えばここで、DDPMという最先端のモデルを訓練しました。会議室と教会の画像だったと思います。200枚の画像のデータセットで訓練しました。この列には生成された画像、つまり新しいはずの画像があります。この列には、生成された画像に最も近い画像があります。
訓練セットで、生成された画像に最も近い画像を探します。最も近いとはL2距離での意味です。それらを見ると、生成されたこの画像は本質的に同じ、つまり生成されたこれに最も近い、データセットで見つける同じ画像であることがわかります。
ここでも同じ、ここでも同じ、ここでも同じです。他のすべては2番目に近い、3番目に近いなどです。この段階では、システムは機能していません。記憶化しており、汎化していません。新しいデータを生成していません。これが望まない段階です。
興味深いのは、まったく同じモデル、つまり同じパラメータ数を取り、まったく同じ方法で最適化し、同じアルゴリズム、同じエポック数で、訓練セットの画像数を増やすと、200枚の代わりに40,000枚にすると、今度は生成する画像がもはや訓練セットで見つける画像ではなくなります。
明らかにここでシステムは記憶化する代わりに汎化し始めています。そして、データ数を増やし、他のすべてを固定すると記憶化から汎化に移行するというこの事実は、多くの異なる人々によって見られています。
こちらは私たちの論文以前の例で、CIFAR-10で同じ種類の実験があります。これは記憶化された画像の割合を訓練セット
サイズの関数として示しています。訓練セットが小さいと、与えられたUNetに対して最初は記憶化し、訓練セットのサイズを増やすと実際に汎化し始めることがわかります。
ここでは生成された画像で訓練セットにあるものはゼロです。興味深いのは、より大きなモデル、つまりより強力なモデルを取ると、この遷移がより大きな訓練セットサイズの値で起こることです。モデルがより強力なときは、訓練セットサイズをより大きくする必要があります。
明らかに、ここでは教師あり学習で二重降下の観点から議論されてきたこととはかなり異なる効果が見られます。人々は、非常に大きなモデルを取ると、これは汎化を損なわないと言います。ここでは明らかに、非常に大きなモデルを取ると汎化を損なうことになります。より簡単に記憶化するからです。
次元の呪いからの脱出
ここで強調することが重要な1つのことは、記憶化と汎化の間のこの遷移で、nの値、つまりc×次元の指数関数的よりもはるかに小さい値で起こっているということです。次元はここでは32×32だったかもしれませんが、32の二乗の指数関数的は確かに200から40,000の間の数ではありません。
明らかに、記憶化と汎化の間の遷移があり、nを増やすと起こり、言っているように、ある値のnでクロスオーバーがあり、このnの値はスコアを学習するために使用したモデル、データの種類、訓練手順に依存します。しかし、次元の呪いから考えるよりも確かに小さいです。
つまり、はい、記憶化はありますが、同時に実際のシステムはそれから逃れます。訓練セットサイズの、次元の呪いに基づいて考えるよりもはるかに小さい段階で。システムは次元の呪いから逃れ、繰り返しになりますが、問題はなぜそうするのかです。興味深いのは、組織化に依存しますが、ある正則的な明示的な正則化があれば、記憶化も起こり得ます。
記憶化と汎化の視覚的理解
さて、記憶化対汎化について何かお見せするために、Carlini、Goodman、Millaによるこの研究で行われた数値例が本当に気に入りました。これは私がお見せしたいものです。この汎化を考える最良の方法だと思います。
彼らが行ったことは、ここのnは訓練セットのサイズです。同じモデル、同じ訓練手順でモデルを訓練しましたが、訓練セットS₁でモデルを訓練し、訓練セットS₂で別のモデルを訓練しました。
この場合、訓練セットは1枚の画像だけです。この場合も1枚の画像だけです。そして、訓練セットS₂で訓練したモデルで生成し、訓練セットS₁で訓練したモデルで生成すると、訓練セットが1つのデータだけの場合、ここで同じデータが得られ、ここで同じデータが得られます。
2つのモデルS₁とS₂は新しくないデータを生成しています。記憶化しており、一方はセットS₁で訓練され、一方はセットS₂で訓練されているので、異なる画像を記憶化しています。n=10やn=100でも同じです。何が見えますか。モデル1によって生成された画像をS₁の最も近い画像と比較します。
同じであることがわかります。システムは記憶化しています。S₂のシステムでも同じです。100でも同じで、まだ記憶化しています。そして押していくと、最後に彼らが言う100,000のとき、興味深いのは、生成、つまり逆向き動力学が同じ初期条件から始まり、S₁とS₂の両方に同じ熱ノイズを使って行われることです。
この段階で見えるのは、S₁、つまりモデル1とモデル2が、同じ画像、訓練セットS₁にもS₂にもない全く同じ画像を生成していることです。これは何を意味するかというと、2つのモデルが異なる訓練セットで訓練されたにもかかわらず、少なくとも典型的な構成で本当に同じ力場を学習し、実際に一方のケースでも他方のケースでも全く同じ軌道を実行しているということです。これは、本当に汎化している場合、スコアのgradient of log p_tを本当に学習した場合に、すべきことです。
これは汎化を見る美しい方法だと思います。この場合も、訓練セットを増やすと記憶化と汎化の間のこの遷移が見られます。結論として、記憶化は、大学でできる同じデータセットで行われましたが、Stable Diffusionのような最先端の拡散モデルも使うことができ、その場合でも少なくとも部分的な記憶化が見られることが示されています。
記憶化問題の理論的・実用的重要性
私の観点からの記憶化の問題は、非常に良い問題です。理論的でもあり、理論にとっても応用にとっても重要だからです。
生成モデルにおける汎化の意味の核心にあるため、理論にとって重要です。プライバシー、著作権の問題にとって重要であるため、民間企業にとっても明らかに重要です。これは実際、DeepMindの研究者と議論して、これに取り組み始めた理由の1つでもあります。
さて、問題は、なぜ実際に拡散モデルは記憶化しないのかということです。これが私たちの研究で答えようとした質問です。もちろん、私たちだけではありません。これらの質問に取り組もうとする人は多くいます。多くの異なる説明が考えられます。
議論されてきた1つの可能な説明は、モデルが十分に強力でない場合です。言ったように、スコア関数、つまり画像に戻す経験的スコアは、実際には非常に正則的になります。多くのピークの総和のlogの勾配だからです。これは原則として、データセットが大きく、十分なパラメータがない場合、モデルが十分に強力でない場合、表現するのが非常に難しい可能性があります。おそらく表現できないので、補間しようとするでしょう。
アーキテクチャと最適化の正則化
1つの可能性は、システムがこの関数を表現できないため、記憶化せず汎化しているというアーキテクチャ正則化があることです。しかし、これは明らかに重要なアイデアだと思います。私が言おうとしているのは、これ以上のものがあると思いますが、明らかに重要なポイントです。
もう1つの重要なポイントは、正則化すると知られているように、記憶化に対応する力場が非常に正則的になることです。正則化する方法について考える必要があります。特にRiccardoは彼の論文で正則化する方法について良い議論をしています。学習率の強度も正則化する方法として考えることができます。
ある種の明示的な動的正則化があれば、記憶化を避けるか減らすことができるかもしれません。これも明らかに役割を果たすと思います。しかし、強調したいのは、実際には、例えば、以前お見せした例は、畳み込みネットで作成されたUNetで得られたものです。
ネットワーク内にすでにある種のアーキテクチャ正則化があり、訓練手順でも、無限に小さい学習率ではなく有限の学習率があります。これらすべてにもかかわらず、訓練セットが十分に小さければ、モデルは実際に記憶化できることが見られました。
私たちの観点は、実際に他に何かが起こっているはずだということです。これが本当にお話ししたいことです。他のポイントが重要でないということではなく、より一般的な問題の異なる側面だということです。
私たちのポイントは、訓練ダイナミクスによる暗黙的な動的正則化という1つの現象があり、それがシステムに記憶化を避けさせるということです。では、最初に数値実験から始めましょう。
訓練時間と記憶化の関係
お見せするために、画像のデータセットを取り、サイズが非常に異なる訓練セットを取りました。異なるUNetサイズで異なる最適化、最適化ダイナミクスで、結果が堅牢であることを確認しました。Fabbriらも、これらの種類の数値結果を見つけており、彼らはtext-to-imageや画像モデル、さらに大きな画像も研究しています。
ここにFIDがあります。FIDは生成される画像の品質を評価する方法です。FIDが小さければ、良い画像、良い品質を意味します。ここにあるのは、τは訓練時間です。
行っているのは、時間τまでモデルを訓練し、停止して画像を生成するために使うことです。もちろん、訓練を非常に早く停止すれば、良くない画像が得られます。FIDは非常に高くなります。そして、十分長く訓練すれば、FIDが下がることがわかります。
ここにある異なる曲線は、ちょっと質問がありますか。
申し訳ありません、中断して。Remyから質問があります。τは正確には何ですか。エポック数ですか、それとも最適化器の反復回数ですか。
最適化器の反復回数です。
わかりました。ありがとうございます。
ここにある異なる線は、異なる訓練セットサイズに対応しています。ここにある数nが増加しているので、訓練セットサイズを変えると、この部分はあまり変わらないことがわかります。訓練セットが十分に大きければ、品質は増加しますが、訓練セットサイズにほとんど依存しません。ある時間τの後、生成された画像は良い品質になります。
もう1つ見ることができるのは、画像を得たら、画像が良く見えることを望みますが、訓練セットにあるかどうかも見たいということです。システムが記憶化しているかどうかです。ここで見えるのは、この側に記憶化の割合があります。
n=1.5×10⁴のとき、この訓練時間で見ると、訓練時間を10⁵の後まで押すと記憶化が始まることがわかります。興味深いのは、訓練セットを大きくすると何が起こるかです。画像の品質についてはほぼ同じ曲線が得られますが、記憶化を始める時間がさらに押されます。
訓練時間のスケーリング則
ここでこれが起こる理由がわかりませんが、確認してみましょう。これらの異なる曲線が、訓練時間を訓練セットサイズで割ったときにスケールすると、実際に一緒に崩壊することがわかります。
ここで行ったのは、訓練セットのサイズの観点で時間を測定すれば、これらの曲線が実際に一緒に崩壊することがわかりました。これは、ここにあるこの時間が訓練セットサイズを増やすとどんどん大きくなり、どのように大きくなるかというと、実際には訓練セットサイズに線形に大きくなることを意味します。
ここで同様の結果が得られますが、今度はFIDと記憶化割合を見る代わりに、損失、訓練損失とテスト損失を見ます。訓練とテストがまったく同じであることがわかります。
これが訓練で、これらがテストで、まったく同じです。ある時間まで汎化誤差がゼロで、その時間で異なり始め、汎化誤差が増加し始めます。この時間は訓練セットサイズを増やすとより大きなτに押されることがわかります。
繰り返しになりますが、これらすべての時間を崩壊させることができます。汎化誤差が増加し始めるこの時間は訓練セットサイズに依存し、インセットから見ることができるように、訓練セットサイズに線形に依存します。
これは私たちが見つけたものですが、Mallatのグループによっても見つけられ、その後他のグループによって確認されました。見つけたのは、記憶化に達する時間です。これらすべてのケースで、訓練を十分長く押せばシステムは記憶化しますが、本当に長く押す必要があり、どれくらい長く押す必要があるかというと、大まかには、良い汎化、画像の良い品質に達する時間かける訓練セットサイズnまで押す必要があります。
ランダム特徴モデルによる解析
モデルはまず汎化を学習し、その後はるかに後、訓練セットサイズに比例する時間で記憶化を始めます。これが数値です。この問題を解析的にも研究しました。
スコアのランダム特徴モデルの場合に研究しました。ランダム特徴は、多層パーセプトロンを取り、実際にこれらの重みを固定し、これらの重みだけを最適化する簡単なモデルです。これは、スコアがこのように書かれ、最適化する唯一のパラメータがこのaであることを意味します。これらはランダムに取られ、固定されます。
解析的に研究できる簡単なモデルで、行ったのは、データとしてある共分散を持つガウスデータを取り、データ数が次元とともにスケールする高次元極限にあり、両方が無限大に正方形で、パラメータ数p、つまり隠れ層にあるノード数も次元dとともにスケールします。これらは2つのパラメータcとαで、次元に比較してどれだけのパラメータがあるか、次元に比較してどれだけのデータがあるかを示します。
さて、経験的損失を見ることができます。この場合、書き下ろせば、ここで良いのは、スコアがパラメータに線形で、損失が単に平均二乗損失だからです。
つまり、損失はパラメータに二次です。最後に、最適化ダイナミクスとして勾配流を研究すれば、aが大きな行列であるため複雑だが、線形であるため単純なダイナミクスがあります。最後に、損失が二次のとき、勾配流や勾配降下を行うと、a dotマイナスある行列かけるaかけるあるソース場のような方程式があります。
最後に、ダイナミクスで何が起こるかを理解したければ、この行列Uとこの行列Vを研究する必要があります。行列Uを見ると、Uがaを掛けているので、実際にUの固有値がダイナミクスを制御しているものです。結果をお話しする前に、説明したランダム特徴モデルの数値シミュレーションを行えば、損失、訓練とテストを見ると、実際のシステムで以前お見せしたものと非常に似たものが見つかります。
これらの異なる曲線は訓練セットの異なるサイズに対応し、再び分離し始めることがわかります。汎化誤差が異なる時間で増加し始め、これらの時間はnに線形です。これは学習されるスコアと真のスコアとの間の距離です。この場合、ガウスデータを使っているだけなので、真のスコアがわかります。
この距離が下がり、実際にゼロにほぼ達し、その後、訓練セットのサイズに応じて、経験的損失に向かって進むため、再び大きくなる可能性があります。しかし、これはより後に起こり、訓練セットサイズが大きいほどより後に起こります。
ダイナミクスを理解したければ、これが示していることは、実際に最初に汎化し、その後記憶化を始めるということです。ダイナミクスを理解したければ、ここでのダイナミクスはこれらのランダム行列によって支配され、特にダイナミクスの緩和時間はこの行列U + λ×単位行列の値の逆数に関係しているだけです。λは非常に小さく置く正則化です。
固有値分布と記憶化ダイナミクス
最後に、問題は私たちが研究したランダム行列理論の問題に帰着します。固有値を見ると、固有値が2つのバルクに分かれることがわかります。
1つのバルクは1のオーダーの固有値があり、1のオーダーの緩和時間に対応します。そして、実際には非常に小さいバルクの固有値があり、ズームするとここにあり、これらの固有値は1/nのオーダーで、これらの固有値はnのようにスケールする緩和時間です。これらは記憶化に対応します。
ここで、ダイナミクスを完全に解析的に解くことができます。より大きな値は、テスト損失と訓練損失が同じオーダーで、汎化誤差がゼロであるダイナミクスの最初の進化に本当に対応します。そして、実際には非常に小さい値がダイナミクスの第二段階に対応し、ここで示していたもの、記憶化に向かって進むところです。
現実的なケースで見つけたことをまったく見つけました。このアーキテクチャ組織化も見つけました。これは議論していたもので、記憶化時間がn×汎化時間に比例する段階は、実際には過パラメータ化されたシステムがある場合、パラメータ数pが非常に大きい場合まで続きます。nを増やしても、nがパラメータ数に比例するn_starに等しくなると、実際にもはや記憶化がなくなります。
理由は、ここでは非常に多くのデータがあり、パラメータ数を考えると、システムはもはや実際に記憶化できないためです。これは実際にMallat以前に研究されていたものです。
記憶化と汎化の位相図
2つの図で結論させてください。ここに位相図があります。これは位相図の図解ですが、実際のデータでの数値実験とランダム特徴モデルの場合の両方で見つけました。
ここにデータ数があり、ここにパラメータ数があります。何が起こるかというと、あるパラメータ数があるとして、あまり大きくないデータ数があれば、システムは記憶化しています。データ数を増やすと、記憶化時間、つまりここにあるものが汎化時間からかなり離れ始める段階に入り始めます。
このギャップが開いており、このすべての段階で実際にこのギャップが開いており、どんどん開いていきます。つまり、実際にダイナミクスを停止すれば、早期停止でさえありません。この記憶化時間が非常に遠くに押されているため、実際に見るには本当に狂ったように訓練しなければなりません。
このすべての段階で、システムはダイナミクスによって暗黙的に正則化されています。訓練すると、訓練スコアが汎化スコアに非常に近い非常に極端に遅いダイナミクスがあり、非常に非常に遠くまで押した場合にのみ記憶化に行きます。
このすべての段階で、実際にシステムは訓練ダイナミクスのおかげで記憶化を避けることができます。そして、このパラメータ数について、ある点でデータ数を本当に非常に高く押すと、ある点で実際にシステムはアーキテクチャ正則化の段階に入ります。システム、モデルは実際に経験的スコアを表現できません。これは非常に不規則な関数だからです。この場合、システムは実際に記憶化していません。
パラメータ空間でのダイナミクスの重要性
ここに例があります。例えば、1次元の場合にダイナミクス中に何が起こるかを理解させるためのものです。ここにあるグレーは経験的スコアです。言ったように、ピークの総和のlogの勾配なので非常に不規則な関数です。黄色は訓練ダイナミクス中のスコアの進化です。破線の黒は汎化スコアに対応するもので、無限数のサンプルを取れば得られるものです。これは単にそれが何であるかがわかるケースです。
訓練ダイナミクスの最初には、経験的スコアに等しくなく、真のスコアに等しくないものから始まりますが、長い間、このすべての段階で、実際にシステムが落ち着きます。訓練スコアが汎化スコアに非常に近い関数に落ち着き、非常に長い時間の後にのみ、実際にシステムはニューラルネットワークをモデル化するパラメータを、訓練スコアが経験的スコアを表現できるように動かさなければなりません。
できますが、長い時間がかかります。この暗黙的な正則化、ダイナミクスによる暗黙的な正則化の背後にある非常に興味深いと思うことは、ニューラルネットワークを通じてスコア関数である関数をパラメータ化する方法が、この現象を引き起こすことです。
訓練ダイナミクスが関数空間ではなくパラメータ空間にあるからこそ、パラメータ空間で、おそらくこの非常に不規則な関数を作成することは可能ですが、極端に長い時間がかかり、システムは最初に実際に滑らかなものを表現し、その後非常に長い時間で実際に非常に不規則なものを表現します。これは教師あり学習の場合に少し前に議論されていたもので、スペクトルバイアスと呼ばれていました。
結論と今後の展望
結論を述べさせてください。お見せしたかったのは、記憶化を避けるメカニズムで、非常に表現力のあるAIモデルが実際に最初に汎化し、その後はるかに後に記憶化を学習することに関連しているという事実です。実際に取り組んでいて考えているいくつかのフォローアップがあります。テキスト生成の場合に同様のことを行うことです。
そして、ここでは記憶化の非常に厳密な定義を考慮しました。つまり、まったく同じデータがあることを意味しますが、もちろん実際には部分的な記憶化について考えることができます。これは理論的に興味深く、実際にも興味深いと思いますが、定義するのも難しいです。
これで私の注意を引いてくださってありがとうございました。
ありがとうございます、Giulio。素晴らしい講演でした。本当に感謝します。聴衆からの質問の時間があります。ミュートを解除するか、チャットに入れてください。Remyが手を挙げているので、彼から始めましょう。
はい、講演をありがとうございました。非常に興味深いです。たくさんの質問がありますが、そのうちの1つは、記憶化の良いメトリクスはありますか。講演の最初に、スコアを完全に学習すれば、デルタピークの総和に収束するので記憶化すると言いました。このデルタピークの総和項を計算できます。
記憶化のメトリクスの1つのアイデアは、デルタピークの総和である真実とスコア関数の間の距離を計算することです。つまり、例えばUNetやTransformerやアーキテクチャで、この距離を計算すればある種のメトリクスが得られますが、これについて良いアイデアはありますか。
理論でやりたいか実際にやりたいかによって、異なる答えがあるかもしれません。理論では、モデルによって生成される確率とデルタピークの総和に対応する確率との間の距離を見ることができます。例えば、真の基礎となる確率との間で、システムが一方に近いか他方に近いかを見ることができます。
実際には、例えば、画像を見るほかに、できることは、点を生成したら、訓練セットの点との距離のヒストグラムまたは統計を見て、この点がランダムな典型的な点であった場合に得られるものと比較して、他のものよりもはるかに近いものがあるかどうかを見ることができます。これは実際に多くの人によって実際に行われています。
わかりました。最近傍距離のようなものですね。
はい。その統計です。そうです。
わかりました。
特徴空間でやるかもしれませんが、あなたが考えていたこともそうかもしれません。
そうですね、特徴空間でもピクセル空間でもできます。そうですね。他に質問は。
はい、お願いします。
ああ、どうぞ。
ありがとうございます。この素晴らしい講演に感謝します。なぜ早期停止ではないと言うのか知りたいです。ここで何かを見逃しました。
そうですね。いいえ、早期停止と呼ぶこともできると思いますが、早期停止の事実は、つまり停止です。もちろんダイナミクスを停止します。強調したかったのは、教師あり学習で早期停止を行うとき、一般的には、訓練が下がっていくのが見え、テストがあり、最小値で固定します。
ここでは実際に、システムが過学習していることを見るには、訓練を狂ったように押す必要があります。だから時々、つまり停止しますが、停止すべきだと考えているからではありません。
はい。はい。
1つの早期停止と他の早期停止の違いがわかりました。ありがとうございます。
他の人が質問している間に、私も簡単な質問をさせてください。ランダム特徴モデルのGiulioの解析について、1つより技術的な質問と、それからより広い質問があります。
重みに正則化子があると言及していましたが、小さかったです。これが何らかの暗黙的な正則化によって動機付けられているのかコメントいただけますか。ダイナミクス中にも起こっている。このフロベニウスノルム最小化項をどう動機付けますか。
いいえ、実際には、正しいです。実際には書きましたが、実際にはゼロに置きます。しかし正しいです。実際には、何らかの正則化を置くことができるか、できるかについて考えることができます。議論した種類の正則化で行ったことをやり直すと良いかもしれません。
ランダム特徴を書くとき、人々は常にこの種の正則化を置きますが、実際にはゼロに置きます。
わかりました。わかりました。そうですね。興味深いかもしれません、ええと、λを持っているいくつかのスケーリングに直接接続できるかどうかです。
ああ、そうですね、できると思います。私たちはやりませんでしたが、正しいです。λのnとのスケーリングを計算できると思います。記憶化と汎化の間を変えるものです。そうですね、間違いなく。
そうですね、良いです。ありがとうございます。
もう1つ質問があります。ああ、いえ、チャットでありがとうだけです。他に質問は。
はい、もちろんです。
ありがとうございます。第二の理論的部分で、理解が正しければ、解析的に解析するためにスコアの簡単なモデルを置きます。これを古典的な結果と関連付けます。MLPのような勾配降下と確率的勾配降下の比較のようなものです。
理論的な結果があるとき、損失の最小化子はGD対SGDで同じではないようなものです。SGDの方がよりパルシモニアスなもののようなものです。この種の解析に関連付けますか。暗黙的正則化という言葉を言いましたから、同じ種類のものですか、それとも私が理解していませんか。
いいえ、一般的なアイデアからすると、そうだと言えます。つまり、実際に助けになるのはダイナミクスのやり方です。しかし、少し違う意味では、ここでは勾配降下を使うか勾配流を使うかSGDを使うかの事実ではなく、パラメータでそれを行い、関数ではないという事実についてです。
パラメータでダイナミクスを行い、関数ではないために、ニューラルネットワークの観点で関数を書く方法が、この効果を作り、この効果はSGDを使っても勾配降下を使っても常にそこにあります。しかし、実際にはパラメータでのダイナミクスであるという事実がこの効果を出現させますが、関数空間で勾配降下を行えば、異なるダイナミクスになります。
損失関数、損失、勾配降下を行う風景は同じですが、軌道が異なります。この意味では、ダイナミクスによる暗黙的正則化でした。パラメータでのダイナミクスで、これも使用するモデルの種類、ディープニューラルネットワークであるものの方法に起因します。
ありがとうございます。
Remyのフォローアップ質問かもしれませんが、大丈夫ですか。ランダム特徴モデルを使って何らかのプリコンディショナーを設計することについて何か考えはありますか。実際により関数空間での勾配降下のような自然勾配降下を構築するために。
ああ、いいえ、良いアイデアだと思いますが、いいえ、私たちはやりませんでした。
わかりました。わかりました。
ありがとうございます。
何らかのプリコンディショニングを行う方法があるかもしれません。少なくとも関数でのダイナミクスに近づくために。
そうですね。そうですね。
でも後で話しましょう。
はい。わかりました。
素晴らしい。他に質問がなければ、ここで締めくくれると思います。Giulio、素晴らしい講演を本当にありがとうございました。本当に楽しみました。そしてここにいるすべての方を代表してもありがとうございます。
ありがとうございます。ありがとうございました。さようなら。


コメント