本動画は、複数のAIモデルを連携させることでシステム自身がプロンプトを最適化し、自律的に性能を向上させる「自己進化するAIシステム(Learning to Self-Evolve: LSE)」の最新研究を解説したものである。軽量なローカルモデルを自己進化ポリシーとして訓練し、クラウドベースの強力なアクションモデルの出力を監視・修正させるというデュアルエージェント構造を採用することで、手動でのプロンプト調整の限界を超え、システムが動的かつ自動的にエラーを学習して精度を向上させる仕組みを詳しく説明している。
AIモデルの自己進化と自動化されたAI研究室
コミュニティの皆さん、こんにちは。またお会いできて嬉しいです。今日は、AIモデルに自己進化を教える方法をご紹介します。それでは見ていきましょう。現在、私たちは単なるAIモデルを構築しているわけではありません。1つのAIシステムが別のAIシステムにプロンプトを出し、テストし、最適化する、自動化されたAI研究室を構築しているのです。なぜなら、プロンプト最適化の複雑さは、数学的に見てあまりにも複雑になりすぎたからです。
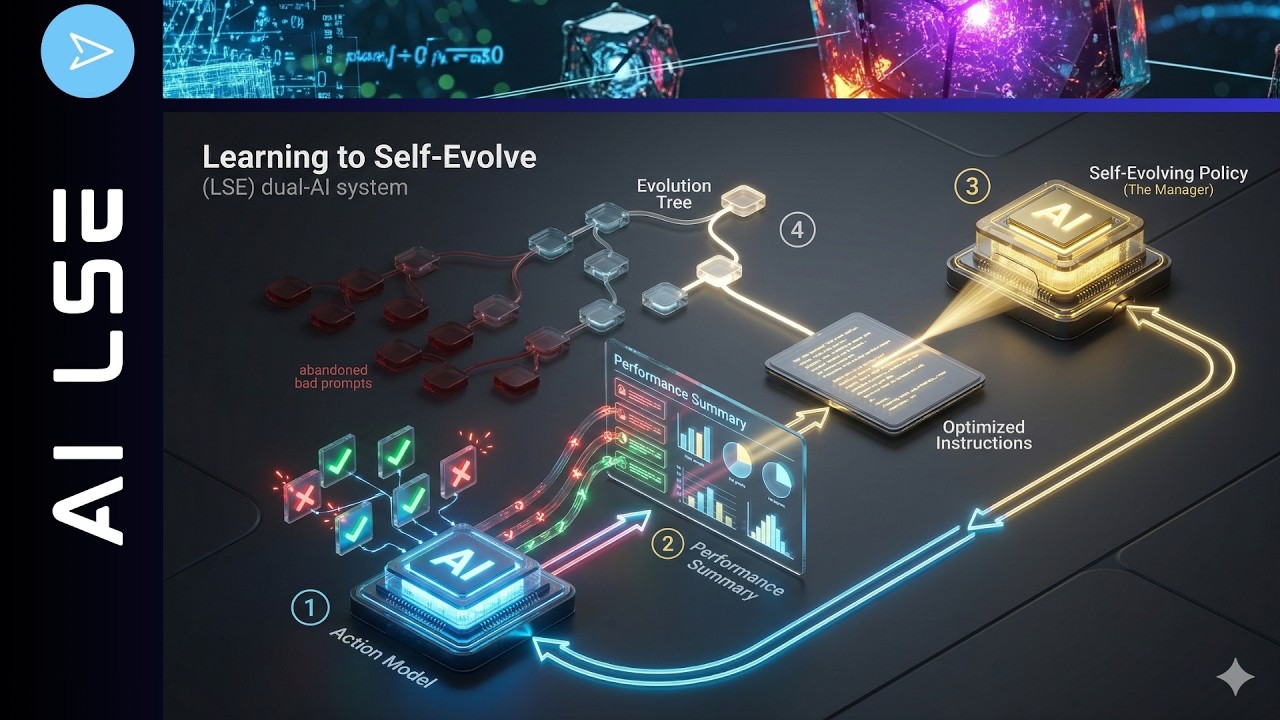
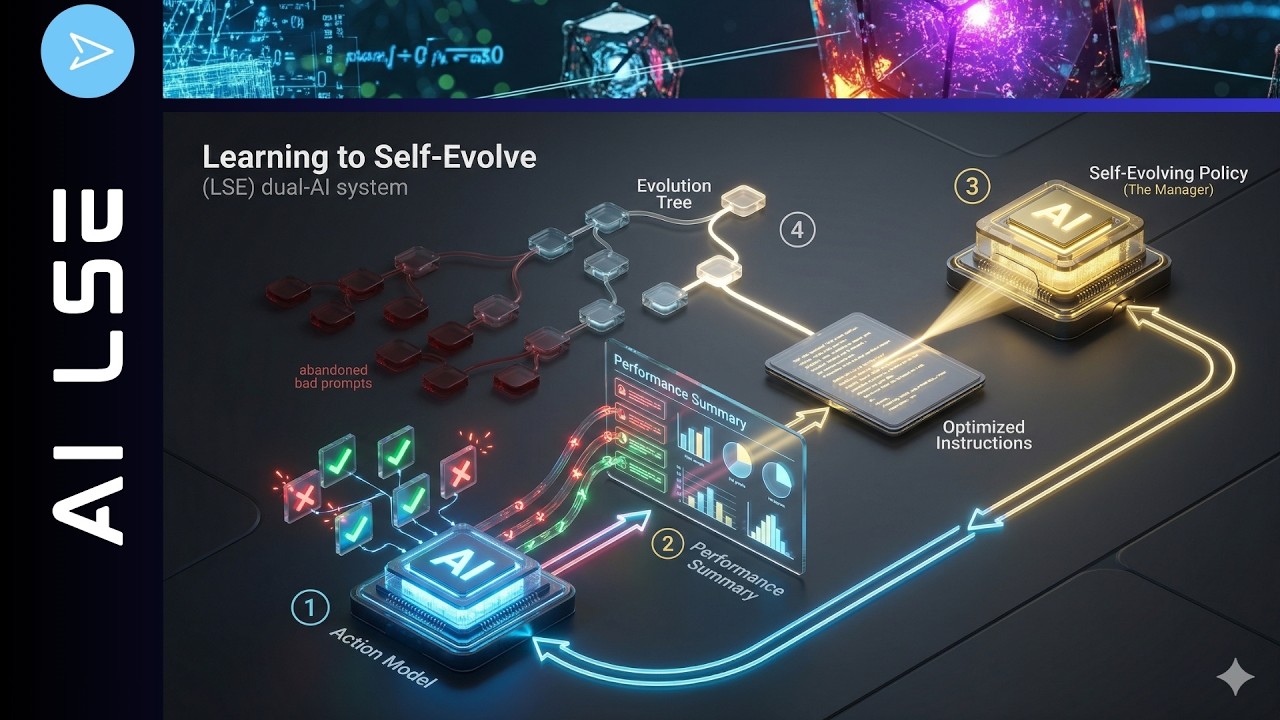
さて、これは実は非常にシンプルな方法になり得ます。自己進化を学習するには、少なくともデュアルAIシステム、つまり2つのAIシステムが必要です。1つはアクションモデルと呼ばれるAIシステム、もう1つは自己進化するポリシーモデルです。これら2つのモデルの相互作用によって、システムのパフォーマンスを飛躍的に向上させることができるのです。
クラウドベースモデルとローカルモデルの組み合わせ
ここで非常に興味深い部分をお見せしたいと思います。この自己進化するポリシーモデルは、40億パラメータや80億パラメータの非常に小さな、無料でトレーニング可能なローカルで使用できるモデルで構いません。しかし、アクションモデルの方は、クラウドベースのプロプライエタリなモデルを使用できます。つまり、例えばGeminiなどの強力なモデルと、理論物理学、医学、化学、金融など、特定のドメインに最適化された自己進化するポリシーモデルを組み合わせることができるのです。これら2つのモデルを組み合わせた場合のパフォーマンスの向上は、まさに驚異的です。モデルが自ら学習するようになるからです。後ほど、本当に素晴らしいパフォーマンスの向上をお見せします。
でも、これはまだ最初のシンプルな実行結果に過ぎません。それでは見ていきましょう。前回の動画では、自動プロンプト最適化について既にお話ししましたね。まだこの話をしなければならないことに、私は驚いていました。前回は、Gaperや、VISTAと呼ばれる新しい手法をお見せしました。VISTAはマルチエージェント対応のフレームワークであり、これについては詳しく説明しました。
前回の動画の最後で、私は未来の仕事はシンプルだと言いました。多様なタスクにわたる大規模な最適化の軌跡を収集し、特定のドメイン、例えば医学における失敗ケースを、意味的な類似性などでクラスタリングします。そして、繰り返し現れるパターンをヒューリスティックなカテゴリに抽出し、これがシステムによって自動的に行われることを期待するのです。そしてなんと、その未来は今日やってきました。なぜなら、前回の論文と全く同じ日に公開された新しい論文があり、私たちがまさにこのトピックに焦点を当てているからです。
自己進化を学習する新しいフレームワーク「LSE」
それがこちらです。ケベックAI研究所、モントリオール大学、Snowflakeによる2026年3月19日発表の新しい論文、Learning to Self-Evolve、自己進化の学習です。彼らは非常に特殊なAI自己進化システムを持っています。彼らは強化学習フレームワークを使用しており、推論時にLLM自身のコンテキストの複雑さを向上させるように訓練します。
これを読んだ時、私は少し奇妙に感じました。推論時に実行するのに、訓練時に強化学習フレームワークを持っているとは、どういうことなのでしょうか。調べてみると、これはかなりシンプルな仕組みであり、Claude 3.5すらも上回る性能を発揮することがわかりました。さらに驚くべきことに、Gaperシステムをも上回るのです。前回のGaperの話を忘れていましたね。7ヶ月前に公開したRL Gaper、新しい生成AI構造という特定の動画があります。Gaperについて深く知りたい方は、そちらの動画をご覧ください。
それでは、この動画の内容を続けましょう。私たちのAIシステムにおけるテスト時のエピソード間の進化について、かなりシンプルな純粋な数学的解釈で進めることもできますが、よろしければ、ここではメインとなるアイデアを、少し高い視点から何が起こっているのかをお見せしたいと思います。
訓練時のコンピューティングと推論時のコンピューティング
皆さんはAIのシンプルな仕組みはご存知でしょうが、ここで少し追加しなければならないことがあります。異なる計算時間で複数のAIシステムを運用しているため、少し注意が必要です。ご存知のように、まず訓練時のコンピューティングがあります。ここに自己進化するポリシーモデルがあります。そして、例えば私のクエリがあり、そのクエリが実行されます。次にテスト時のコンピューティング、つまり推論の実行があります。そしてここにアクションポリシーAIモデルがあります。素晴らしいですね。ここで訓練が行われます。
自己進化するポリシーモデルは訓練時のコンピューティングであるため、当然、強化学習の複雑さを持つことができます。これがいかに可能であるかをお見せします。推論においては、アクションポリシー側のインコンテキスト学習による最適化に多かれ少なかれ制限されますが、自己進化するポリシーAIは、まさにこのアクションポリシーを操縦することになります。お見せしましょう。
まず、この自己進化するポリシーモデルは、それ自体が特定の基本問題を解決することは決してありません。このモデルが行うのは、もう一方のAI、つまりアクションポリシー側の入力と出力を観察することです。そして、そのもう一方のシステムが失敗した時、内部メモリにすべてを書き留めます。入力、出力、失敗の要約を確認し、そのドメイン知識を活かして、時間 t+1 におけるもう一方のAIの指示を書き換えようとします。ここではコンテキストをCとします。この指示によって、もう一方のAIシステムが抱えているアクションポリシーの認知的盲点を修正しようとするのです。
一方、もう一方のAIシステムであるアクションポリシーは、環境と直接相互作用します。私の問題X、つまりプロンプトやクエリXと、現在の指示Cを受け取ります。例えばポリシー最適化を行ったり、コンテキストフローを最適化する他のシステムがあったりして、単純な出力Yを生成します。例えば、SQLで操作しているとしましょう。このアクションポリシーモデルの重みは、このフレームワークのライフサイクル全体を通じて永久に凍結されています。だからこそ、先ほど言ったように、プロプライエタリなクラウドベースのGeminiなどのモデルを使用でき、それを心配する必要がないのです。なぜなら、訓練、適応、自己進化は、アクションポリシーモデルで起こるのではなく、ローカルにある小さな自己進化ポリシーモデルで起こるからです。
プロンプトコンテキストの書き換えとデュアルエージェントシステム
その方法をお見せします。ここで見ることができます。このプロンプトのコンテキストである現在の指示があり、このシステムが時間 t+1 で指示を書き換えます。つまり、入力、出力、そして失敗モードについての洞察を持っているのです。これはまさに、私が前回の動画で終わったところを最適化しているだけです。前回の動画でも同じようなことをお見せしましたね。システムは、なぜそれらの例が失敗したのかについて、いくつかの異なる仮説を生成しました。昨日の前回の動画でも、2つのエージェントが存在していたことを思い出してください。カリフォルニア大学バークレー校も、このデュアルエージェントシステムを採用するという同じアイデアを持っていました。
それでは、これをどのように構築し、コーディングし、訓練できるかを見てみましょう。フェーズ1は当然、訓練時のダイナミクスです。強化学習の訓練フェーズでは、両方のモデルがアクティブになります。もちろん互いに依存していますが、アクティブラーニングを行うのは1つのモデルだけです。お分かりの通り、それは自己進化するポリシーモデルであり、私のPC上にあるあの小さな40億や80億パラメータのモデルです。
フォワードパスを詳しく見てみましょう。アクションポリシー側はアクティブですが、重みは凍結されています。つまり、アクションポリシーモデルはここではデータジェネレーターとして機能します。開始時のコンテキストを使用して、バッチ処理された問題を単に試行します。開始時のコンテキストはゼロでも構いませんし、特定のドメイン固有のコンテンツに対してパレート最適なプロンプトを既に提供していても構いません。
昨日お見せしたのと同じように、仮説が立てられます。自己進化するポリシーは、アクションポリシーモデルの失敗を見て、新しいコンテキストを生成します。なるほど、あなたはABCという間違いを犯したのですね、だから、これを修正する方法はこれです、と言うわけです。そして、アクションポリシーモデルはこの新しいコンテキストT1を受け取り、ホールドアウトセット、つまり検証用データセットの問題Dに挑戦します。つまり、全く同じ訓練データセットに戻るのではなく、検証データセットを持つのです。そして、まさにこの精度の差を取ることで、報酬を生成することができます。この報酬は非常にシンプルなものです。昨日の動画を見てみてください。パフォーマンスの向上のみに基づいています。
そしてここからが本当の学習プロセス、アクティブラーニングプロセスです。テンソル構造や重みの更新は、ここでは強化学習を用いて行われます。PPOなど、好きなものを使って構いません。そして、自己進化するポリシーAIモデルの勾配のみを計算します。当然、小さなモデルの方が速く学習し、より良いプロンプトの書き方を学習します。アクションポリシー側のニューラルネットワークの重み、つまりテンソルは変化しません。
推論フェーズにおけるインコンテキスト学習と木探索
フェーズ2に入ります。ここでは、医学、金融、理論物理学などのドメインについて質問するといったクエリが発生します。推論時にはあることが起こります。これをアクティブなデプロイメントと呼びましょう。両方のモデルはアクティブで、当然入出力が必要ですが、アクティブラーニングを行うモデルはゼロです。つまり、私たちが今行っているのはインコンテキスト学習です。これらのモデルの強化学習ではありません。テスト時のコンピューティングです。
もう少し詳しく見てみましょう。推論時には、勾配降下法も、バックプロパゲーションも、テンソルの重み更新もありません。強化学習システムは完全にインコンテキスト学習に移行し、ここでは古典的な木探索アルゴリズムと組み合わされます。訓練時のコンピューティングで新たに鍛え上げられ、重みが凍結された自己進化するポリシーAIは、これまでのパフォーマンスに基づいて最適化された新しいプロンプトの複数のバリエーションを生成します。
つまり、システムはこれらのプロンプトの進化ツリー、いわばグラフを構築するのです。そして、おなじみの上限信頼限界アルゴリズム、UCBを使用してツリーを探索し、どれが勝者のシステムであるかを分析できます。学習は純粋にアルゴリズム的なものであり、テンソルの重み更新はありません。システムは、AIプロンプトの最適なグローバルマキシマムを見つけるために、コンテキストCのテキスト空間を探索します。もしあるプロンプトの枝がパフォーマンスを低下させた場合、どうなると思いますか。UCBの方程式が自然にそれを剪定し、メタモデルにツリーを逆戻りさせて、以前に成功したプロンプトの祖先に戻るように強制します。これは古典的な木探索アルゴリズムですね。
タスク実行とメタ推論の認知的次元の分離
お気づきかもしれませんが、ここで認知的次元の分離が行われています。分子動力学における物理学を考えてみてください。100年前のボルン・オッペンハイマー近似を思い出してください。あれは何をしていたのでしょうか。動きの速い電子と、重くて動きの遅い原子核を分離していたのです。特性の異なるシステムを分離したわけですが、彼らはAIでも全く同じことをすることに決めました。
私たちのLSEは、タスクの実行と純粋なメタ推論を分離しています。彼らはここでSQLデータベースの例を取り上げています。非常に複雑なSQLデータベースの結合問題を解決するには、特定の潜在的な経路が必要です。10個の失敗したSQLクエリのバッチを分析し、そこから一般的なヒューリスティックを導き出し、なぜ失敗したのかを理解するには、一般的な最適化を行う場合とは全く異なる認知経路が必要です。そこでは、言ってみればSQLの専門家である必要があります。
したがって、タスクの複雑さを2つのエージェントに分離することで、ポリシー最適化エージェントは、そのパラメータ空間全体を仮説生成のロジックに排他的に捧げることができます。前回の動画や、テキストの最適化を見てみてください。2つのエージェントがそれぞれの専門分野に取り組みます。そして、ポリシー最適化はプロンプトコンテキストからテキストを出力するだけなので、主要なクラウドベースモデルのアーキテクチャには完全に依存しません。
論文が鮮やかに示しているように、結果のセクションでお見せしますが、研究者たちはここで40億パラメータのQwenモデルをまさにこのオプティマイザーになるように訓練し、それを解き放ちました。これはまたローカルにある全く別の高度に特化した70億パラメータのAIモデルで、この小さなQwenモデルは兄貴分のエラーをうまく診断し、70億モデル用により良いプロンプトを書き、それによって最終的なパフォーマンスを7%向上させました。この自動プロンプト最適化手法が、新しい数学的最適化定理によって、本当に優れたシステムパフォーマンスを達成しているというのは興味深いことです。
LSEのパフォーマンス結果とTextGrad、Gaperとの比較
それでは、これを見てみましょう。訓練時のコンピューティングでは、アクションポリシーAIモデルは凍結されており、自己進化するポリシー側で強化学習が行われます。特定のドメインでクエリを実行する際、両方のシステムは凍結され、プロンプト内、つまりTransformer層のアクティベーションパターン内でのインコンテキスト学習のみが行われます。自己進化するポリシーモデルは、言ってみれば超最新世代の熟練したプロンプトエンジニアリングエージェントとなるのです。本当にインテリジェントなエージェントが、アクションポリシーAIモデルをアクティブに操縦しているのです。
素晴らしい響きだけど、結果はどうなのと思われるかもしれませんね。彼らは多くの結果を提示していますが、ここではGaper、TextGrad、そしてこの新しいLSE手法に焦点を当てたいと思います。最終結果の平均を見てみましょう。Gaperは73%を達成しました。この新しいLSE手法は73.3%です。あなたはふむ、なるほどと思うかもしれません。TextGradは69.1%です。Gaperと比較すると、その改善は本当にわずかだと言えるでしょう。
しかし、昨日の動画でお見せしたように、Gaperには特定の条件セットにおいて大きな問題があり、Gaperの問題を克服するためにはVISTAが必要でした。しかし、これらのデータセットにおいては、こういった小さなことのためにVISTAの複雑さは必要ないように思われます。したがって、ここでのパフォーマンスの向上は、どちらかというと控えめな増加だと言えます。ちなみに、ご存知ない方は、私のチャンネルで検索ボックスにテキストを入れてみてください。1年前にDSPyからTextGradへ、あるいはDSPyやTextGradの先へと進む話題をお見せしています。皆さんが探索できるように、プロンプト宣言言語など、本当にたくさんの新しい方法論が存在します。
最適化されたプロンプトの構造とテキストベースの摂動
この研究で本当に素晴らしいのは、そして皆さんにお見せしたいのは、彼らがプロンプトを提供してくれていることです。ここには自己進化するポリシーのプロンプト構造があります。あなたはText-to-SQLエージェントを設計する専門家です。エージェントは固定のデータベーススキーマ上で実行されています。以下は現在のエージェントのプロンプトと、最近のパフォーマンスの要約です、と書かれています。
そして、この新しいAIの仕事は、実行精度を向上させるために指示のみを書き換えることです。これは、厳密な出力フォーマットを維持しながら向上させるという指標です。そして、現在のプロンプト、過去の問題に対する関係性の要約、エージェントの完全な思考プロセスを与え、指示の書き方を伝えます。ここには本当にすべてのことが指定されています。試してみたい方にはとても興味深い内容です。
また、ここではドメインごとにこの新しいLSEで訓練された自己進化するポリシーモデルによって発見された最良の指示も再現されています。ツリーガイドによる複数回の進化ラウンドの後、これらの指示がアクションモデルのシードプロンプトのシード指示を置き換えます。そして、これらが最良の指示であることを実際に示しています。常にこのフォーマットで正確に1つの有効なSQLiteクエリを返してください。自然言語の質問を注意深く分析し、ターゲット属性、関連するテーブル、その列、日付のフィルタリング、時間を特定してください。条件付き出力には決してこれを使用せず、この特定の命名規則を使用してください、といった具合です。
ご覧の通り、気をつけるべきことや注意すべきことなど、失敗する可能性のあるあらゆる事柄を提示し、パフォーマンスを向上させます。これは、スキルのマークダウンファイルや経験ファイルを見るのと同じようなものです。何が間違っている可能性があるのか、何に注意しなければならないのかを提示し、それによってアクションモデルAIのパフォーマンスを向上させているのです。
これが本当にドメイン特化型であることを強調しておきたいです。これはエキスパートモデルのためのものです。何十億もの人々が使えるようなモデルではありません。もっと気をつけて、と単に言うようなものではありません。SQLを使った特定の物理学を扱うのであれば、経験的な失敗ログから正確なデータベースの問題を抽出し、それらをハード制約としてプロンプト内のインコンテキスト学習の指示に従うように埋め込むのです。そうすることで、既知の失敗多様体をすべて除外するように、アクションモデルの出力空間を数学的に制限しました。つまり、出力空間の制限を見事に達成したわけですが、これも素晴らしいことです。
さらに、漸近的なアライメントも備えています。物理学で摂動論を用いて、例えば既知のハミルトニアンに小さな補正を加えて現実に合わせたり、計算不可能な部分を処理したりするのを思い出してください。ここAIの世界では、メタモデルがテキストによる摂動を利用して、アクションの振る舞いがターゲットとなる現実世界の環境の癖と完全に一致するまで、反復的にヒューリスティックを追加していきます。
これを見て私は、テキストの摂動だけで本当に十分なのだろうか、と思いました。しかし、十分であることが判明しました。これこそが、彼らがシステムをこのような特定の方法で設計した理由です。昨日VISTAについて話した時、初期条件から局所的な最小値から抜け出すのに十分な勢いを持つことができないため、Gaperが失敗すると言ったのを覚えているでしょうか。Gaperで提供される摂動は十分に強くなく、力不足なのです。ここでは、同じような摂動が既に組み込まれており、それらは純粋にテキストによるものです。
これが昨日のモデルと本当に似ていることをお見せしたいと思います。時間 t の辺りでの訓練データではなく、観察バッチです。メタモデルは、アクションモデル、つまりクラウドベースのモデルやローカルの32Bモデルなどが試行した k 個の小さな問題のバッチを観察します。これがパフォーマンス要約 S です。そしてメタモデル、つまり私の小さな4Bモデルは、このローカルデータを利用して、その知能に基づいて何が間違っていたのかという仮説を形成し、時間 t+1 のための新しい最適化されたプロンプトを生成します。
汎用的な自動化AI研究手法としての可能性
間違いを見て新しいコンテキストを生成するわけですが、これはまさに私が昨日お見せした仮説エージェントで起こったことと同じです。そのエージェントも全く同じように仮説を生成しました。仮説は構造化されたタプルになっていました。カテゴリのラベルがあり、自然言語による説明があり、これをどう解決するかという具体的な修正方法がありました。全く同じ日に発表された論文で、著者たちが多かれ少なかれ同じアイデアを持っていたというのは本当に興味深いことです。
さらに本当に興味深いのは、ホールドアウトセット、つまり検証データです。訓練データセットがあり、そして検証データセットがあります。言ってみれば、これこそがこのようなシンプルな報酬関数を持つことを可能にしているものであり、このシンプルな報酬関数の天才的な部分です。システムは、アクションモデルが今見たばかりの10個の問題に対して新しいプロンプトのコンテキスト t+1 を評価するわけではありません。全く別の固定されたホールドアウトセット、例えば見たことのない15個の問題に対して、新しいプロンプトを使用してアクションモデルをテストするのです。そして、ただパフォーマンスを把握したいのです。なぜなら、その見えないデータセットにおけるこの特定の指標の精度の差として報酬が計算されるからです。このように行うのは非常に素晴らしいアイデアです。
これでお分かりいただけたでしょう。これら2つのエージェントの相互作用と、今お見せしたような厳密な経験的報酬ループを使用することで、AIシステムは、その言語的状態空間 C を更新するだけで、リアルタイムの推論コンピューティングにおいて通常環境に適応します。言語的状態空間のみを更新するのです。言語的な摂動さえあれば、システムが局所的最適化のローカルミニマムから勢いをつけて抜け出すのに十分なのです。本当に素晴らしいです。AIにおける絶対的な真理を見たことがないなら、これは純粋に美しいメカニクスだと言えるでしょう。
最後になりますが、私たちは何を言えるでしょうか。AIシステムを環境と相互作用させ、それが失敗するのを観察し、精度と精度の低下を測定し、その間違いから学び、間違いを理解することで、動的に自らの操作マニュアルを書き換えさせれば、おそらくいつかエラー率は漸近的にゼロに近づいていくでしょう。AIシステムは特定の仕事のために自らを学習し、最適化しました。これは文字通り、オートパイロットで実行される人工的な科学的手法と言えるでしょう。
そして、これはCapatinaによるAutoResearchとも本当に似ています。しかし、これはメタパラメータの単純な行列表現の最適化を超えた一般的な方法論です。なぜなら、ローカルのポリシー最適化を使って、皆さんのドメインにこれを使用できるようになり、プロプライエタリなクラウドベースのアクションモデルに適用できるからです。個人的な見解ですが、これこそが美しさだと思います。
皆さんご存知の通り、物理学を思い出してください。環境が完全にカオスであったり、時間ステップごとにランダムに生成されたりする場合、いくら観察しても次の状態を予測することはできません。では、物理学では何をしなければならないでしょうか。構造、つまりシステムの不変性に目を向けなければなりません。ここでは構造的な不変性に目を向けます。私たちは、時間を超えて一定であり続ける、基礎となる法則や対称性を探求して発見し、そしてハードな法則を確立するのです。
この理論物理学のアイデアを取り入れてAIに適用すれば、これこそが自己進化するポリシーで起こっていることだと分かるでしょう。私たちは、特定のドメイン、例えばSQLデータベースの場合の因果的不変性やトポロジカルな不変性を定義します。したがって、先ほど述べたような問題に直面することはありません。これを見れば、訓練時のコンピューティングの複雑さと推論時のコンピューティング、そしてその両方のコンピューティングシステムで起こっている学習プロセスが理解できるはずです。推論中、メタモデル、すなわち自己進化するポリシーAIモデルはオブザーバーとして機能し、動作中のアクションポリシーモデルを見て、SQLiteの癖などのドメイン固有の不変性を推論し、それを新たに最適化されたプロンプト構造に書き込みます。
つまり、私たちは訓練時のコンピューティングと推論時のコンピューティングの複雑さにまたがるマルチエージェントシステムのプロンプト最適化手法に立ち返っているのです。これは私がこれまで見たことのないようなものです。私たちがここで構築しているのは、小さくローカルなエキスパートシステムであり、それらは自己進化するポリシーモデルです。これらは、自宅やオフィスのコンピュータインフラストラクチャ上でローカルに実行できます。クラウドベースのアクションポリシーモデルのフルパワーを活用しつつ、皆さんが所有し、おそらくファイアウォールの内側にある自己進化するポリシーモデルによる特定の強化学習の最適化を望むなら、これは非常に素晴らしいアプローチです。
さらに一歩進みたいのであれば、数日前に私が公開した、新しい代数的アプローチによる再構築の動画を思い出してください。もちろん、興味があればその動画に繋げることもできますが、それは専門家向けです。しかし、2つのヒントをお教えしましょう。グラフにおいて、トポロジーはリレーショナルデータベースの秘密の言語のようなものであることを思い出してください。そして、私たちの新しい手法であるLSEメタモデルが推論時の進化の間に何を行っているかというと、驚かないでくださいね、データベースのトポロジカルな不変性を発見しているのです。私の他の動画と繋げて考えたいなら、これがブリッジ機能になるでしょう。
さて、これは専門家向けの話でした。動画はこれで終わりです。楽しんでいただけたなら、そして何か新しい情報を見つけていただけたなら幸いです。少しでも楽しんでいただけたなら嬉しいです。


コメント