Moonshot AIが開発したKimi K2.5は、コーディングとエージェントスウォームに特化したオープンソースのビジョンAIモデルである。約15兆のビジュアル・テキスト混合トークンで事前学習され、ネイティブマルチモーダル機能を搭載している。最大100のサブエージェントと1500のツールコールを駆使した並列処理により、従来のシングルエージェント設定と比較して実行速度が4.5倍向上した。エージェント系ベンチマークでは、GPT-5.2やClaude 4.5 Opus、Gemini 3 Proなどの最先端モデルを上回る性能を示し、特にビジョンタスクとフロントエンド開発において圧倒的な強みを発揮する。コーディングベンチマークSWE Verifiedでは76.8を記録し、主要フロンティアモデルに匹敵する実力を持ちながら、コストは大幅に低く抑えられている。ウェブサイトの再現、複雑なパズル解決、自律的なビジュアルデバッグなど、実用的なタスクでも高い能力を実証しており、ダウンロードしてローカルで実行可能な点も大きな魅力となっている。
Kimi K2.5の登場とその衝撃
Kimi K2.5が登場しました。これはコーディングとエージェントスウォームに特化した最先端のオープンソース・オープンウェイトモデルで、全体的に非常に印象的な性能を持っています。そして今すぐダウンロードできるんです。Kimiの投稿から詳しくお伝えしましょう。
Kimi K2オープンソース・ビジュアル・エージェンティック・インテリジェンスの紹介です。ビジュアルというのは非常に特別な要素で、ビジョンタスクにおいて極めて優れた性能を発揮します。エージェント系ベンチマークでグローバル最先端の成績を収めていますが、これについては後ほど詳しく見ていきます。
センスのあるコーディングができます。チャット、画像、動画を表現豊かな動きを持つ美しいウェブサイトに変換できるんです。特にフロントエンド開発において非常に優れています。そしてベータ版のエージェントスウォーム機能。自己指示型エージェントが並列で大規模に動作し、最大100のサブエージェント、1500のツールコール、シングルエージェント設定と比較して4.5倍の高速化を実現しています。
これはkimmy.comで使用できますし、先ほど言ったようにダウンロードして自分で実行することもできます。
Kimi K2.5の技術仕様と特徴
これがKimi K2.5です。明らかにKimi K2からのドットイテレーションで、約15兆の混合ビジュアル・テキストトークンによる事前学習を継続しています。ネイティブマルチモーダルで、最先端のエンコーディングとビジョンを実現しています。
そしてもう一つの新機能として、エージェントスウォームを自己指示できるネイティブ機能があります。特に複雑なタスクの場合、Kimi K2.5は最大100のサブエージェントを持つエージェントスウォームを自己指示できるんです。もちろん、ClawdBotのことを考えています。ClawdBotではこれが非常に強力になるはずです。まだテストしていませんが、絶対に試すつもりです。最大1500のツールコールにわたって並列ワークフローを実行し、実行時間を4.5倍短縮します。
ベンチマーク性能の詳細分析
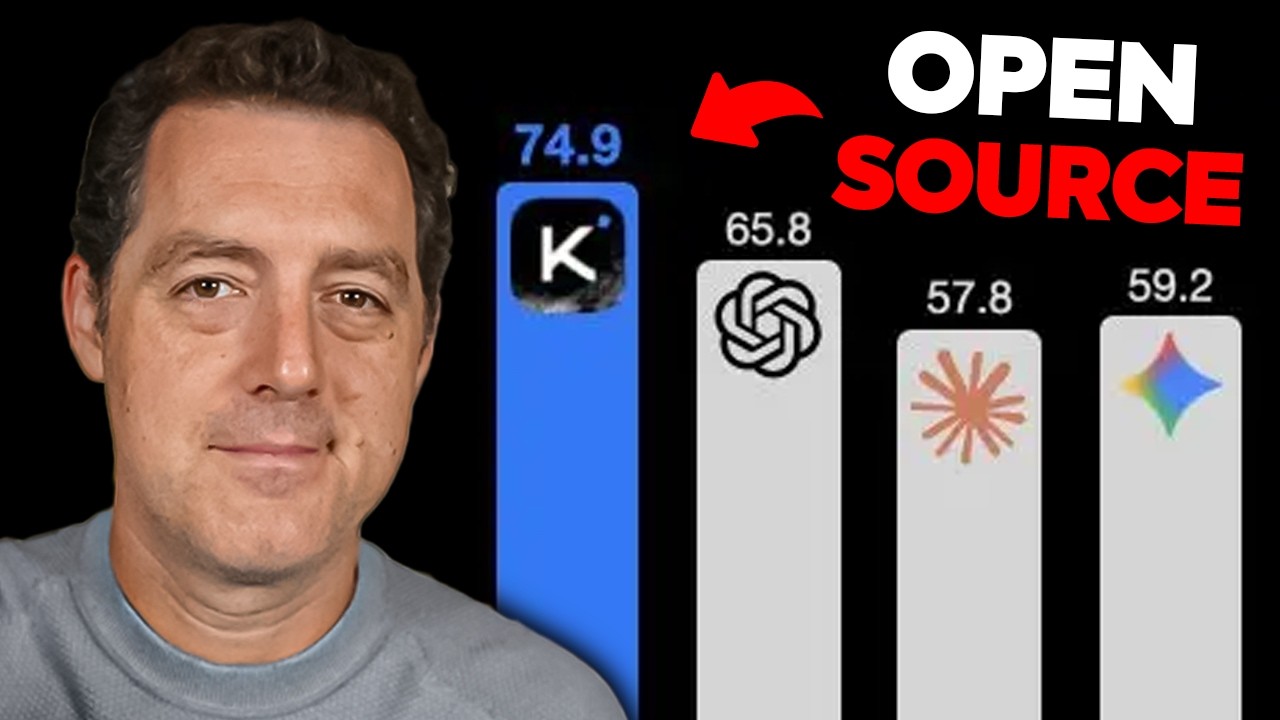
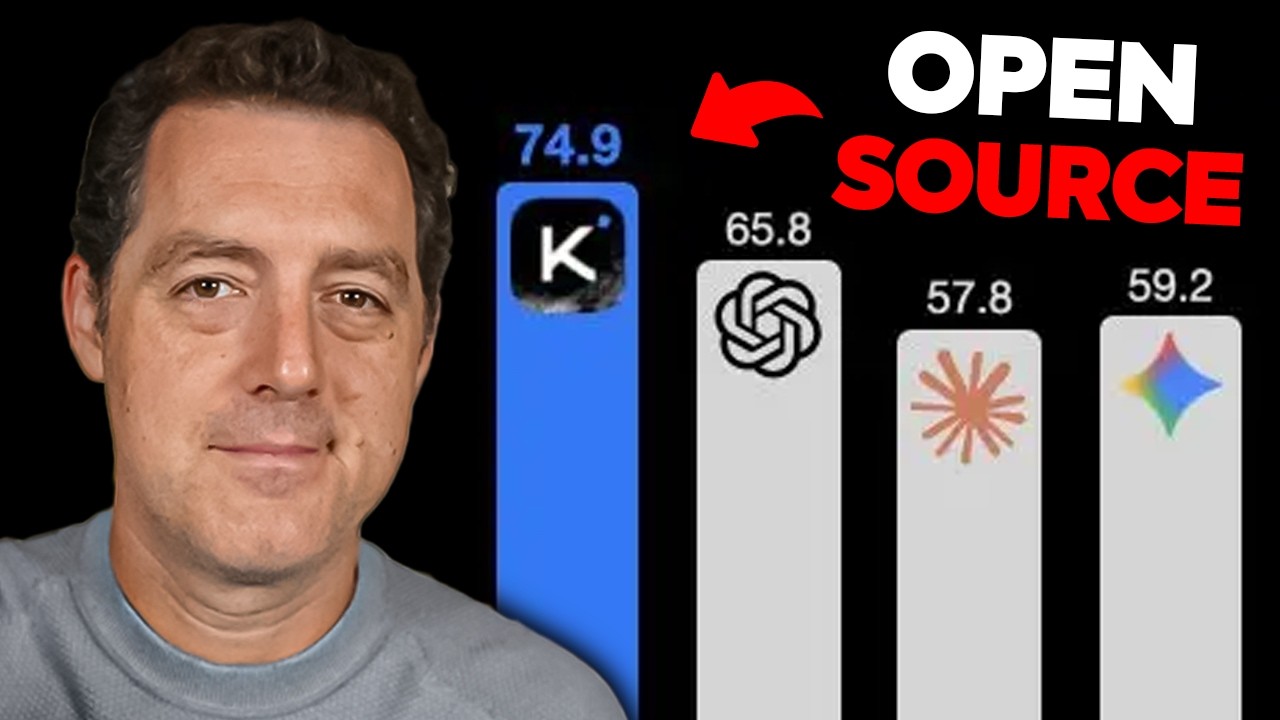
それでは、ベンチマークを見ていきましょう。まずエージェント系ベンチマークです。HLE full、Browse comp、Deep Search QAがあります。Kimi K2が第1位で、GPT-5.2の拡張思考、Claude 4.5 Opusの拡張思考、Gemini 3 Proの高度思考を上回っています。信じられません。これを見てください。Browse compで74.9、他のフロンティアモデルを圧倒しています。
こちらはDeep Search QAで、Claudeを除く他のモデルを大きく上回っていますが、それでもClaudeには勝っています。コーディングについては、SWE verifiedで非常に競争力のある76.8を記録しています。これはGPT-5.2やClaude Opus 4.5のレベルには達していませんが、かなり近く、実際にGemini 3 Proは上回っています。そしてSWEBench multilingualでは、ほぼ同じスコアが出ています。
ビジョンタスクについては、これを見てください。MMU Proで強力なパフォーマンスを示しています。78.5で、GPT-5.2とGemini 3には及びませんが、Claude 4.5 Opusは上回っています。動画理解については、最先端レベルです。基本的に他のすべてのモデルと同等です。そしてlong video benchでは、他のすべてのモデルを上回っています。
非常に興味深いのは、異なるモデルの個性が見え始めていることです。個性と言っているのは、それぞれが特に得意とする分野のことです。エージェントで見ると、Claudeは他の3つと比較してやや低めです。コーディングでは最高です。しかし画像と動画の理解では最も低いんです。
つまり、Anthropicチームがコーディングに多くの重点を置いていることがわかります。最高のコーディングモデルであることは誰もが知っていますが、これがそれを示しています。
コスト優位性とその意義
そして本当にKimi K2.5を際立たせているのはコストです。非常に安価なんです。X軸にコスト、Y軸にパフォーマンスがあります。ここにGPT-5.2があります。コストはこの上の方にあります。そしてなんと、HLEベンチマークでより優れたパフォーマンスを大幅な割引価格で実現しているんです。ここも同じです。
Browse compを見てください。こちらまで大きく振れています。そしてSweetbench verified、非常に安価です。これまでで最強のオープンソースコーディングモデルなんです。
実践的なデモンストレーション
いくつか例をお見せしましょう。これは私が作成したウェブサイトで、非常に美しい色使いです。AI生成には見えません。すべてが非常にスムーズに流れています。これが別の例です。
非常にカラフルで、非常にクリエイティブで、一瞬たりともAIが作ったようには見えません。そしてKimi K2.5は特にビジョンとコーディングの組み合わせに優れています。ウェブサイトのスクリーンショットを渡して、それを再現するよう依頼できるんです。これを見てください。左側に元のウェブサイトがあります。右側にKimi K2による再現があります。
覚えておいてください、コードも、理解も、ウェブサイトへの直接リンクも渡していないんです。渡したのはウェブサイトの画像だけで、それを再現しろと言っただけです。
ビジョンとコーディングの融合
彼らはどうやってこれを実現できたのか説明しています。この能力は、大規模なビジョン・テキスト共同事前学習から生まれています。スケールが大きくなると、ビジョンとテキストの能力の間のトレードオフは消失します。それらは一体となって向上するんです。
これはパズルについて推論し、コードを使って最短経路をマークする例です。これが実際のパズルで、非常に複雑です。左上隅の緑の点から右下の赤い点への最短経路を見つけてください。黒が道を表しています、と指示します。
ここですべての思考の連鎖を見ることができます。Pythonを実行して位置を特定しています。たくさんのツールコールを連続して行っています。それから画像をバイナリに変換します。素晴らしい。今度は最短経路のためのライブラリであるBFSを実装しています。そしてこれです。最短経路を赤でハイライトしました。非常に印象的です。
そして実際にズームインして、より明確な可視化を作成するよう依頼できます。ここで実際に行っています。緑の経路がそこに見えます。この迷路を完成させるのに113,000ステップかかりました。
自律的ビジュアルデバッグの実演
これは何ができるかの別のデモです。Kimmy Codeを使ってマティスのLDANの美学をKimmyアプリに翻訳しています。このデモは自律的ビジュアルデバッグにおけるブレークスルーを強調しています。つまり、画像を取得し、コードを書き、更新を画像として見て、さらにコードを書くという反復ループが起こっているということです。
では見てみましょう。これは速度を上げています。画像をダウンロードしているのが見えます。それを見ていることを確認し、コードを反復し、再度試し、コードを反復し、行ったり来たりして、最終的に記述したものができあがります。非常に印象的です。
エージェントスウォームの革新
そして彼らはK2.5エージェントスウォームもリリースしています。これはシングルエージェントからマルチエージェントへのシフトです。並列エージェント強化学習、PARLでトレーニングしたと言っています。これは聞いたことがありませんが、最大100のサブエージェントのエージェントスウォームを自己指示することを学習し、最大1500の協調ステップにわたって並列ワークフローを実行します。
つまり、Kimi K2ができることは、複雑なタスクを個別のステップに分解し、それらのステップをサブエージェントに委任し、それらが戻ってくるのを待って、基本的にすべてをオーケストレーションするということです。非常に印象的です。
そして繰り返しますが、ClawdBotのことを考えています。これはまさにCladebotがやっていることです。サブエージェントに委任しています。だから本当にKimi K2でCladebotを動かしてみたいんです。でも絶対にローカルでやりたいです。ClawdBotのデータをすべて中国のサーバーに送る気分ではありませんから。
オーケストレーションの仕組み
これがそのオーケストレーションが実際にどのように見えるかの例です。オーケストレーターモデルがあります。サブエージェントを作成し、タスクを割り当て、検索、ブラウザなどの機能があります。サブエージェントを作成します。AIリサーチャー、物理学リサーチャー、生命科学リサーチャーなどがいます。ファクトチェッカー、ウェブデベロッパー。それからすべての異なるタスクを割り当て、特定のエージェントに割り当てています。
それらが完了すると、すべてをオーケストレーターにフィードバックして、すべてをまとめて最良の応答を提供します。こうしてはるかに高速になるんです。
Kimi K2によれば、並列特化実行を通じて複雑なタスクのパフォーマンスが向上します。彼らの内部評価では、エンドツーエンドの実行時間が80%削減され、以下に示すようにより複雑な長期的ワークロードが可能になります。
パフォーマンス比較と実行時間の短縮
それが見えているものです。Browse compが以前のバージョンとClaude Opus 4.5を完全に圧倒しています。Wide searchと社内ベンチからも同じことが見えます。現在地球上で最高のモデルであるClaude Opus 4.5を打ち負かしているんです。
そしてタスクが複雑になるにつれて、より多くの時間を節約できることがわかります。X軸にはタスクの複雑さ、Y軸には実行時間が表示されています。シングルエージェントでは、タスクの複雑さが増すにつれて明らかに時間も増加しますが、彼らが発見したのは、エージェントスウォームではほぼフラットに保たれるということです。つまり、少しは増加しますが、非常に複雑なユースケースでは大きな違いがあります。
実際のエージェントスウォームの動作
これが実際にどのように見えるかの例です。さまざまなサブエージェントが見えています。基本的に、YouTubeでさまざまな分野の多数の動画を見つけて調査するというタスクを与えました。それぞれの分野について、特定のサブエージェントに割り当てられ、100のエージェントがありました。
ほら、すべてのエージェントがあります。それぞれに名前があり、ちょっと面白いですね。各エージェントが独自の分析をまとめ、オーケストレーターがすべてをまとめました。
オフィスタスクへの応用
そして明らかにオフィスタスク、知識作業、つまりPDFの作成やExcelドキュメントの操作などにも優れています。ここにいくつかのベンチマークがあります。K2 thinkingとの比較だけですが、まあいいでしょう。
Wordでの注釈追加、ピボットテーブルを使った財務モデルの構築、PDFでのlatex方程式の記述、これがどのように見えるかです。これはすべてKimi K2.5によって作成されたものです。これがKimi K2.5によって編集されたドキュメントです。素晴らしい。これがKimi K2.5によって作成されたPDFです。
ではダウンロードして開いてみましょう。完全に作成された洗練されたPDFドキュメントができました。そして今度はスライドショーを作成しましょう。これはKimi K2.5によって作成されたPowerPointです。本当に印象的です。
包括的ベンチマーク結果
これが彼らが実行した完全なベンチマークです。地球上のすべてのトップモデルと比較してくれたことを本当に感謝します。GPT-5.2、拡張思考Claude 4.5、Gemini 3 Proの高度思考、DeepSeek 3.2、Quen VL、すべてです。
これら最初のベンチマーク、HLE full、AME 2025などでは、実際にはGPT-5.2が最高でした。覚えておいてください、数学ベンチマークであるAME 2025で100%を獲得しました。Kimi K2は全体的に非常によくやりました。HLE fullでのみ勝利しましたが、それでもコストのほんの一部で非常に競争力があります。これから詳しく説明しますし、ダウンロードして自分で実行できます。
画像、動画、ビジョン理解、ビジョンロジックについては、これこそがKimi 2.5が本当に輝く分野です。この青色をすべて見てください。青色が勝利したものです。MMU ProではGeminiが1位ですが、これらの多くで、simple VQA、omnidoc bench、OCR benchで、Kimi K2.5は非常によくやりました。
コーディングベンチマークでの競争力
そしてこれが重要なもの、コーディングです。ClaudeとGeminiがまだこれらの大半で勝利していますが、Kimi K2.5は依然として非常に競争力があります。ゴールドスタンダードのようなSwebench verifiedでは、76.8で、80、80.9、76.2などと比較して、すぐそこにいます。
ビジョンタスクで輝いていますが、最高の分野はエージェント系タスクです。Browse comp、Wide search、Deep Search QA、Fin search comp、Seal zeroがあり、1つの例外を除いて全体的にKimi K2.5が最高です。
エージェント能力の重要性
エージェント能力は非常に重要です。コーディングエージェントに接続する時、ClawdBotに接続する時、このモデルが本当に輝く時です。
もちろん、人々はこれらのフロンティアモデル企業の一部がベンチマキシング、つまり特定のベンチマークへのトレーニングとオーバーフィッティングをしていると非難します。それは確かに可能で、私たち自身でテストする必要があります。実際に使ってみる必要があります。実世界のシナリオで試す必要があります。バイブコーディングをする必要があります。全体的なバイブをテストする必要があります。それが本当に教えてくれるものです。
ベンチマークはさておき、ベンチマークは素晴らしいです。モデルがどれだけ能力があるかの最初の見方として重要ですが、全体的には私たち自身で試す必要があります。
しかし、彼らは自分でベンチマークをテストしてくださいと言いました。APIがあって使えます。だから実際に価格比較をしてもらおうと思います。あなたの価格を比較してください。Kimi K2.5、Claude Opus 4.5、GPT-5.2、Gemini 3、行きましょう。
実際の価格比較タスク
さあ、これです。Kimmyのコンピューターを開きます。タスクを実行しています。非常に素敵なウェブサイトです。検索結果が返ってきました。この比較を実際に作成できるか見てみましょう。
ここで思考の連鎖が見えます。Pythonコードを書き始めています。価格情報があります。わかりました。ここでウェブサイトから価格情報を取得しています。
今度は願わくば素敵なフォーマットで提供してくれるでしょう。さて、猛烈に速いわけではありません。おそらく秒間40〜50トークンくらいで動いているのが見えます。確実に遅い方ですが、これは時間とともに改善されるだけです。そしてできました。クリックしてみましょう。
これです。Kimi K2.5がはるかに安いことがわかります。
API比較、Kimi K2.5は入力トークン100万あたり60セント、出力トークン100万あたり3ドルです。Claude Opus 4.5は525ドル。GPT-5.2がここに、Gemini 3 Proがそこにあります。競合と比較してかなり安価であることがわかります。非常に素晴らしいタスク完了です。完璧にやってくれました。ウェブを検索し、この情報を提供してくれて、私は感心しています。
ローカル実行の可能性
このモデルを絶対にテストするつもりです。ダウンロードしたいです。自分のコンピューターで実行したいです。実際に聞いてみます。あなたはどれくらいの大きさのモデルですか? ローカルで実行するにはどれくらいのVRAMが必要ですか?
では、ここで見えるもの、Kimi K2.5は1兆トークンで、ロードするには632 GBのVRAMが必要です。
ローカルでロードすることはできません。512 GBのVRAMを持つMac Studioを持っていれば、少し圧縮できればロードできるかもしれませんが、おそらく量子化バージョンが必要になるでしょう。それらはおそらくすぐに出てくるでしょう。もちろん、オープンソース・オープンウェイトの素晴らしいところは、それで好きなことができるということです。
Kimi K2.5の上にコミュニティが構築するのを見るのが非常に楽しみです。コメントで皆さんの考えを教えてください。すべてのリンクを下に載せておきます。この動画を楽しんでいただけたら、いいねとチャンネル登録をご検討ください。


コメント