
本動画は、スタンフォード大学とMITによる最新のAI研究「メタハーネス(Meta Harness)」について解説するものである。AIエージェントの中心となる推論用LLM自体を強化するのではなく、その周辺で入力データを準備・最適化する「外殻(ハーネス)」のコードを、別のLLMを用いて自動的に最適化するパラダイムシフトを紹介している。1回の評価で数百万トークンのログをファイルシステムに保存し、それを分析してコードの改善提案を行う仕組みや、従来のDSPyなどとの違いについて詳しく考察している。さらに、現在の結果が単なる局所的なコード最適化にとどまっているのではないかという独自の視点から、将来的なニューロシンボリックなアプローチの必要性についても論じている。
メタハーネスとは何か:AIエージェントの新たなパラダイムシフト
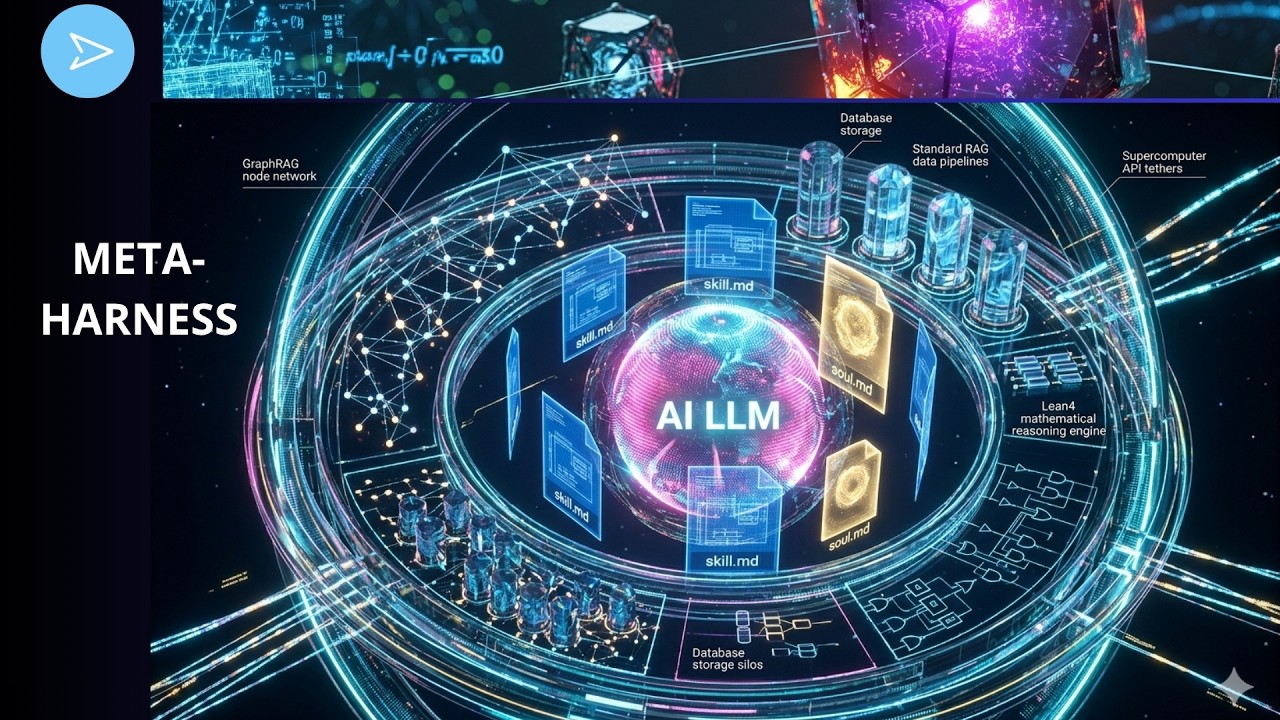
皆さんこんにちは。また戻ってくることができて嬉しいです。一緒に楽しみましょう。最新のAI研究であるメタハーネスについてお話ししますね。ご存知の通り、ここにはエージェントのコアとなるLLMがあり、そしてスキルファイルやマークダウンファイル、soul MDファイルがあります。さらにデータベースへのアクセス、Lean 4、そして標準的なRAGやデータベースストレージ、グラフRAGノードネットワークなど、あらゆるものへのアクセスが備わっています。
これについて考えてみましょう。前回の動画の一つで、ここのスキルマークダウンファイルをどのように改善できるかをお見せしました。そして、Q1がAnthropicの公式のスキルMDよりも優れたスキルMDファイルを持つようになったことを紹介しました。彼らはすべての問題と複雑さを単一のスキルMDファイルに統合できるよう、128のエージェントを並行して実行して最適化しているからです。
さて、このシステムはもう少し複雑だということをお伝えしておきます。少し近づいて見てみましょう。もしこれを4Kの解像度で見ているなら、私たちが何について話しているのかすぐに理解できるはずです。ここには小さなLLMがあり、その周りにはすべてのものがあります。これを、LLMに入力を提供する外殻(アウタースフィア)と呼びましょう。
そして今、パラダイムシフトが起きています。なぜなら、コアにあるLLMをよりインテリジェントにするのではなく、この外縁部、つまり私たちの外殻をよりインテリジェントにしようとしているからです。ここにも標準的なRAGパイプラインがありますね。そしてグラフRAGパイプラインがあります。Lean 4の形式的な推論エンジンもあります。
ここにはホモトピー型理論、論理的証明論があります。そして最先端のクラスターやLeonardoスーパーコンピューターへのAPIがすべてここにあります。ベクターデータベースクラスターやリレーショナルSQLデータレイクなど、あなたが持っているものは何でもです。データが保存されている場所、接続できる場所、コアのLLMに入る前にデータを事前計算する場所ならどこでもです。
これが今私たちが最適化しようとしているものです。そこでシンプルな疑問が浮かびます。これは理にかなっているのでしょうか?それとも、グローバルなAI企業が「ねえ、次世代のAIコアLLMを開発するのは単に費用がかかりすぎるから、外殻を少しだけ賢くしよう。思っているほどお金がかからないことがわかったからね」と言っているだけなのでしょうか。見てみましょう。
複雑化するファイルシステムとハーネスエンジニアリングの登場
ご存知のように、RAGの一部であり、多くのRAGシステムが存在しますが、それは気にしないでください。しかし、この複雑さを見ると、「どうやってこれを制御できるのか?どうやってこれをコーディングできるのか?」と思うかもしれません。最初の段階から始めましょう。まずLLMがあり、おそらくDSPyの最適化アイデアや、LangChain、あるいはRAGパイプラインを最適化するためのカスタムPythonスクリプトが入力にあるかもしれません。もしくは、LLMの周りにエージェンティックなループを構築しているかもしれません。
あなたはコーダーとしてそこにいて、少なくとも手動で、オーケストレーションのタイプやエージェンティックネットワークのトポロジーをここにハードコーディングします。さて、アイデアはシンプルです。複数の入力チャネルの中に、互いに依存している部分がある、または一度だけ計算すればよくて複数回計算すべきではない同一のシーケンスがあると想像してみてください。
事前計算があるかもしれません。つまり依存関係があるわけです。それでは、コアLLMの周りにこの外殻を構築してみましょう。例えばDSPyです。これはプロンプトエンジニアリングの最適化を行う非常に美しいプログラムです。または、前回の動画の一つで紹介した自己学習に進むとすれば、推論を行うLLMへの情報の流入を制御する完全な外殻がここに含まれることになります。
もちろん疑問となるのは、トポロジカルグラフの自己学習が可能かどうかということです。私は「AIは自己進化できるか?」と単に問いかけた特定の動画で、この疑問を検証しようとしました。しかし今日は別のことに焦点を当てます。前回の動画で不満を漏らしたように、そして私のチャンネルの登録者であればお気づきのように、現在ではすべてがマークダウンファイルやPythonファイルの中にあります。
つまり、私たちは極めて複雑なファイルシステムを構築しているのです。Claude Codeや、Anthropicのさらなる実装について考えてみてください。私たちのsoul MDファイル、スキルMDファイル、私たちが定義するすべての環境。今やあらゆることがファイルシステムにエンコードされています。そして、すべてのファイルシステムを取り上げてこう言うかもしれません。「よし、それは素晴らしい。もし、Opus 4.6のようなものがあったとして、このシステムが何百万のGitHubリポジトリでトレーニングされたかはわかりませんが、DSPyや何らかのRAG最適化定理のために、さらに1万のGitHubリポジトリを追加してみましょう」と。
しかし重要な問題は、これが前進する道なのかということです。なぜなら、「AIのファイルシステムは本当に人工知能を解き放つことができるのか?」という動画でお見せしたように、Anthropicと清華大学に関する特定の動画を振り返ると、彼らはそれが考えているほど単純ではないかもしれないという指標を示しているからです。
素晴らしいですね。私たちはこの極めて複雑なファイルシステムを持っていて、今あなたや私がアプリケーションをコーディングしています。そこで新しいマーケティング用語に出くわします。それが「AIハーネス」です。これは一体何でしょうか。今日の論文を見てみると、彼らはハーネスを定義しています。これは、何を保存し、何を検索し、そして純粋な推論を行うエージェントのコアである内部LLMに何を見せるかを決定するコードのことです。
そしてこのハーネスは、しばしばエージェントのコアにあるLLMモデル自体と同じくらい重要であると彼らは語っています。この感度の高さが、現在ハーネスエンジニアリングに対する関心の高まりにつながっています。つまり、私たちはプロンプトエンジニアリングからコンテキストエンジニアリングへ、そして今度はハーネスエンジニアリングへと移行していることがわかります。これは単に、AIシステム全体のパフォーマンスを向上させるために、LLMの周りのコードを洗練させるという実践です。
メタハーネスの仕組み:LLMによる外殻の最適化
「なるほど、シンプルに聞こえるね」と思うかもしれません。しかし、ここからが面白いところです。もし私がこれをコーディングして私がこの黄色の部分にいるとし、あなたがコーディングしてあなたが緑色の部分にいるとします。私は異なるコードベースを使うかもしれません。私はPythonを使い、あなたはC++を使うかもしれません。私はプロンプトエンジニアリングにDSPyを利用し、あなたは外部データの統合にグラフRAGシステムを選ぶかもしれません。
私は、プロンプトシーケンス自体の中でのデータのインテリジェントな準備により焦点を当てるかもしれません。「うーん、プロンプトにもっとコンテキスト情報を提供しよう」といった具合です。このように、選択できる可能性は無数にあります。そして疑問はシンプルです。「これは最適化の問題だ。では、最良の解決策は何なのか?」
皆さんにこれをお見せしたいのです。なぜなら、これらが私に「ああ、そういうことか」と考えさせた研究だからです。これは2025年6月のGoogle DeepMindのAlpha Evolveに関するものです。Googleの大規模な計算スタックの重要なコンポーネントを最適化するために適用されたとき、Alpha Evolveはデータセンターのためのより効率的なスケジューリングアルゴリズムを開発しました。わかりますか?これこそが、私たちが今日自分たちに問いかけていることなのです。
あるいは、2026年2月中旬のこの研究を見てください。「ソフトウェアエンジニアリングベンチマークモバイル:大規模言語モデルエージェントは産業レベルのモバイルアプリケーションを開発できるか?」というもので、彼らは「ノー」と答えました。これはほんの2月中旬のことです。彼らは、現在のエージェントの能力やすべての合成ベンチマークと、実際の産業要件で起こっていることとの間には大きなギャップがあると言っています。
実際に野生の世界に出たときの結論として、不足分は主にクロスファイル推論と要件理解における失敗によって引き起こされていると彼らは指摘しています。そして、もし私が複雑なファイルシステムの点群をお見せして、2月中旬の時点で失敗の原因はクロスファイル推論だったと言えば、あなたもすぐに理解して点と点を結びつけることができるでしょう。
もし人間がうまくできないとしたら、私のパフォーマンスがたった25%だとしたらどうでしょう。簡単です。理論物理学者としてこれを見て、「なあ、簡単だよ。これは最適化問題だ。これには純粋な数学を適用できる」と言うかもしれません。これは現在、AIシステムのための数学的な最適化プロセスとして定義されています。
私がここでコードを書く必要はなく、あなたもコードを書く必要はありません。私はただ、すべてを別のAIの事前トレーニングデータに入れるだけです。そして、この別のAIは外部のファイルシステムを制御し、コアのLLMに対する最適な入力プロセスのための最良の特定のパターンを提供、あるいは見つけ出してくれるのです。
そこで私は言います。「よし、これで外殻のLLMができた。そしてこれの唯一のタスクは、すべての外部情報と、私たちのデータや事前DSPy、事前エージェンティックループなどの最適なデータ準備と事前計算を提供することだ」と。そうすれば、完璧な入力チャネルが得られます。コアLLMのための完璧なデータパイプライン、完璧なプロンプトコンテキストです。
[咳払い] そして、この点群がハーネスと呼ばれるなら、どうなると思いますか?このLLMによるハーネスの最適化こそが、現在私たちが「メタハーネス」、つまり従来のハーネスの1つ上のレベルと呼んでいるものなのです。これは今や、別のLLMにとっての単なる最適化問題となっています。しかし、私たちが手にしているこの美しさにお気づきでしょうか?私たちのLLMは決定論的なモデルではありません。純粋な論理モデルでもありません。
それは統計的な分布なのです。これについては後で詳しく説明します。さて、今日の論文の研究に戻りましょう。これは本当に2026年3月末、30日のものです。スタンフォード大学とMITによるものです。そしてMIT、ご覧の通りOmarがいてMITがここにいるのは、OmarがDSPyの作成者だからです。もしあなたがDSPyを少し飛ばしてしまったり、DSPyやコンテキストエンジニアリングにおける最新の開発に気づいていなかったとしても、気にする必要はありません。
今や、すべてを含む次の外殻が存在するのです。[咳払い] そして彼らはこれをメタハーネスと呼んでいます。推論のみを行うコアAI LLMの周りにあるあらゆるAIモデルのハーネスのエンドツーエンドの最適化です。つまり、言ってみれば私たちには2つの仕事があるのです。外側の仕事は、ここを最適化し、要件を理解し、コアの推論LLMのためにデータを準備することです。
そしてコアのLLMは、推論を行うという仕事だけを持っています。インタラクティブなデモがあるプロジェクトページがあり、スタンフォードIris LabのGitHubリポジトリもあります。素晴らしいですね、飛び込みたければすべてがそこに揃っています。さて、スタンフォードとMITのこの素晴らしい研究の著者たちは今、LLMアプリケーションのためのハーネスコード全体を探索するアウターループシステムであるメタハーネスを導入すると述べています。
1000万トークンに及ぶ実行ログの重要性
これこそが、私が少し前に皆さんに言った理由です。Claude Codeを持っていると想像してみてください。数百万のGitHubでトレーニングされたOpus 4.6を持っているとしましょう。そして今、ハーネスコードがあります。さらに10万のGitHubリポジトリを追加してみましょう。まったく問題ないはずですよね。しかし、そう単純ではないことが判明しました。
アイデアはどのようなものでしょうか。アイデアはシンプルです。私たちにはこの極端なファイルシステムがあります。そして、私たちが持っているすべての経験は、スキルMDファイルやsoul MDファイル、あるいはデータベースファイルなどにあります。そこで今、外殻の新しいエージェントが登場します。エージェントはファイルシステムを読み込み、うまくいけばこのファイルシステムにはすでにいくつかの既存の知識が含まれています。すべての過去の候補ソースコード、システムからのすべての実行履歴、そしてシステムが過去にすでに達成したすべてのスコアです。
そして、このファイルシステムに保存されている経験に基づいて、このエージェントが新しいハーネス構造を提案します。何を使ったと思いますか?スタンフォードとMITはOpus 4.6、つまり最も高価なコードLLMを使用しました。もし私たちがゼロから始めなければならないとしたら、実行履歴には何もありません。しかし、すでに何度か実行したことがあるとしましょう。そうすればもっと簡単になります。
そして新しいハーネスができました。素晴らしいです。私の黄色い点群の代わりに、今度はあなたの緑色の点群になったとしましょう。そこで私たちは言います。「よし、タスクがあるから、真ん中にコアLLMを配置したこのハーネスのパフォーマンスを評価しよう」と。パフォーマンスを評価し、それがどうなるかを見ます。そしておそらくシステムは新しいコードや新しい推論の軌跡を提案したり、推論の軌跡の中で「ねえ、古典的なGitHubリポジトリ7,800でバグを検出したよ」と教えてくれたりして、評価スコアを出してくれます。
この評価タスクは大規模なものです。私が大規模と言う時、それは本当に、1回の評価につき数百万トークンを意味するほどの巨大なものです。そして評価から得られたいくつかの洞察があり、その後すべてをログに保存し直さなければなりません。すべてをファイルシステムに書き戻さなければなりません。なぜなら、思い出してください、これはループだからです。
これは延々と続く継続的なループであり、私たちはこの知識を真ん中のLLMのコンテキストウィンドウに統合するわけではありません。いいえ、推論のみだと言いました。ですから、これは非常に巨大すぎて、外殻のLLMのコンテキストウィンドウに収めることはできません。だからこそ書き留めなければならないのです。
これはどのメモリシステムにも収まらないため、ファイルシステムを作成する必要があります。なぜなら、1回のトレーニングと評価の実行だけで数百万というトークンを扱うことになるからです。そのため、システムは現在私たちがAnthropicで行っているように、すべてをMDファイルやPythonファイル、あるいはあなたが好むどんな形式にでも書き留めます。そして、ループは単に繰り返されます。
DSPyとの違いと、コード空間におけるポリシー探索
アイデアはシンプルで、「うん、素晴らしいね」と思うでしょう。しかし、ここにあるこの新しいエージェント、外殻のエージェントの要件は何でしょうか?それは、コーディングエージェントに非常に強く焦点を当てている必要があります。彼らのデータセットが、それが正しいかどうかを実際に計算できる、検証可能な報酬システムに本当に焦点を当てていることがわかるでしょう。彼らは、「うーん、これは解釈の余地があるな」と言えるようなオープンエンドなシステムはあまり採用していません。
いいえ、結果が欲しいのです。コードが作動し、実行されるかどうか、イエスかノーかが欲しいのです。コーディングエージェントと言えば、何だと思いますか?そうです、Opus 4.6です。開発者ツールを呼び出し、コードを変更できるものです。おわかりのように、私たちはここでは検証可能なコーディングという本当に安全な側にいます。コーディングエージェントの選択、その価格はいくらでしょうか?Opus 4.6未満のものを使用した場合どうなるか、後ほど結果をお見せします。
さて、システムはコードベースとの直接のやり取りを通じて、すべてをうまくこなし、すべてを検証することができます。これは原則としてClaude Codeやあなたが好むものです。そしてお伝えしたように、1回の評価でも、診断情報だけで最大1000万トークンを生成する可能性があります。
ですから、今日のどのLLMのコンテキストウィンドウにも1000万トークンを入れるチャンスはありません。確かにいくつかのプロトタイプはありますが、現実的に考えてこれは意味がありません。なぜ1回の評価実行に1000万トークンも必要なのかと言うかもしれませんね。実は、これをしなければ、完全なログ、完全なプロトコル、Pythonスクリプトからデバッガー、そして絶対にすべてを伴わないで行った場合、ほんのわずかな要約でも行った場合、少しでも「1万5000トークンの短い段落にまとめよう」ということをした場合、それでは情報が足りないことが判明したのです。
絶対的な計算フローに可能な限り近いものを提供しなければなりません。1回の評価につき1000万トークンの診断情報です。なぜ私たちが今ファイルシステムを必要としているのかおわかりでしょう。これは言ってみれば、私でさえ理解できる正当な理由です。「LLMをこれについてトレーニングすることはできない。なぜなら、サイクルの1回目の実行から2回目の実行を理解するためには、ここですべてのログを保持しなければならないからだ」と。
そして外側のLLMの仕事は、すべてのログ、1000万トークンすべてを実際に調査し、「ああ、このシーケンスでは何かを最適化できる」とか、「これら2つのパラメーターの関係において、新しい数学的最適化定理を持たせて、平均値の代わりに何か別のものを計算できる」と決定することです。あるいは、「このシステムの将来の分布を計算できる」といった具合です。
ですから、膨大なデータを保存できる必要があります。そしてこのシステムは、ハーネスレベルでクレジットを割り当てます。過去からの、前回の実行からの、前回のロールアウトからの経験を使用して、どのステップとどのコンポーネントが失敗の原因であるかを意図的に推論します。
私は思いました。「わあ、もし1000万トークンもあるのなら、純粋なLLMはどこを正確に見るべきか、どのシーケンスを分析すべきか、さらに最適化すべきシーケンス間の依存関係をどうやって決定するのだろうか?」と。「そして、外部コードを書き直すか、将来の動作を制御するコードを単に最適化するかを、どうやって決定するのだろうか?」と。
実は、このケースではそれはすべてClaude Code次第なのです。このコードLLMがシステムのさらなる最適化方法を理解する上でどれほど優れているかにかかっています。ご存知の通り、TextGradやGopher(前回の動画の一つで紹介しましたね)やOpen AI Wolfのようなシステムがあります。これらは、過去の試みからのフィードバックを使用して、プロンプトや他のテキストアーティファクトを反復的に改善します。
つまり、このループ構造は私たちに知られています。しかし著者たちがここで検証しているように、これらの方法はハーネスエンジニアリングにはあまり適していません。ハーネスエンジニアリングでは、最適化の対象が完全な実行可能な手順であり、関連する環境からのフィードバックは、コードや報酬システムの検証者だけでなく、実行履歴の内部実行への完全なアクセスにも分散しており、それを要約することは全く困難な方法だからです。
どんな要約でも、どんな圧縮でも、どんな情報の削減でも始めた途端に、このハーネスエンジニアリングは失敗します。最も深いレベルの計算にアクセスできなければならないのです。さて、このメタハーネスの新しいアイデア(sが抜けていますがごめんなさい)は、選択的に過去のコードや実行履歴をファイルシステムアクセスを介して検査する提案(これが私たちのClaude Codeです)を持つというアイデアに基づいています。損失のある要約から最適化するのではなく、これが今や新しいアプローチなのです。
これは単純な数学的な最適化定理だと言いました。ここにはそれしかありません。ハーネスの最適化をコード空間におけるポリシー探索問題として扱います。Mを固定されたLLMとし、Xをタスク分布とします。ハーネスHはロールや軌跡を決定します。目標は、期待される報酬を最大化する最適なハーネス構成を見つけることです。
これは古典的なAIの最適化問題です。ここには報酬構造に関する期待値の最大値(arc maximum)があります。そして著者たちは、Opus 4.6のファイルアクセス統計を追跡すると何が発見されたかを教えてくれます。中央値で1回の反復につき82個のファイルがあり、これら82個のファイルのうち約41%がソースコード、40%が実行履歴、そして残りが何らかの数値的な推定やスコアだということです。
素晴らしいですね。著者たちが主張するように、これは因果推論を実行します。私はその結果を共有し、システムで本当にこのようなことが起こっているのか議論したいと思います。しかし、段階を追って見ていきましょう。「よし、素晴らしい。もし人間が、もし私がこれを行い、あなたがこれをコーディングするなら、確かにどこかに私たちの両方よりも優れた数学的な最適化問題、メタハーネスがあるはずだ」と。
素晴らしいです。しかし、このシステムの数学的最適化において、コアにLLMがあることに気づいていますか?そしてLLMは決定論的なシステムではありません。私たちはどの温度設定でもゼロやゼロに近い状態では操作しませんよね?新しい解決策を思いつく自己学習型の創造的なシステムが欲しいからです。
つまり私たちは今、システムのコアにある統計的なジェネレーター、ライターを見ているのです。そして今、数学的な最適化を行っています。システムの中心にあるコア推論は、何らかの統計的に生成されたシーケンスを吐き出します。今や何千、何百万ものデータが必要になるため、これはある意味、楽しい数学的最適化定理です。
実験結果への考察:局所的なコード最適化の限界と将来への展望
それでは結果を見てみましょう。著者たちはメタハーネスをオンラインのテキスト分類で評価することにしました。なるほど。数学的推論と、ええ、もちろん数学とコーディングです。推論、数学的推論、検証可能。エージェントコーディングも検証可能。テキスト分類は少しオープンエンドかもしれませんが、部分的には検証可能です。
素晴らしい。ここで最高の最高の結果をお伝えします。オンラインのテキスト分類でメタハーネスが達成した最大値は7.7ポイントの改善です。数学的推論において、Quasi Overと比較した場合に彼らが達成した最高のものは4.7ポイントです。そしてターミナルベンチ2では、最高クラスのHaikuエージェントの中にランクインしています。
ここですでに、「ちょっと待って。古典的な最適化定理を使った結果、達成したのが4ポイントの最適化結果?」と感じるでしょう。別のものをお見せしましょう。まず定義を見てみましょう。ハーネスとは何でしょうか?ハーネスとは、言語モデルをラップし、各ステップでモデルがどのコンテキストを見るかを決定するステートフルなプログラムのことです。
これは興味深いです。推論のためにコアLLMに情報、データ、知識が流れ込むのを完全に制御できるということです。そしてこのハーネスが、コアLLMに何を見せることを許可し、何を見せないかを決定します。どのレベルの複雑さがこのコアLLMに供給され、コアLLMには示されないかを決めるのです。
メタハーネスは現在、診断と提案をコーディングエージェント自体に委任しています。どの過去のアーティファクトを検査するかをエージェント自身が決定します。もし10万個のアーティファクトがあったとして、Claude Codeは「アーティファクト7,612を見に行く」と言います。どの失敗モードに対処するかも自身で決定します。そして、コードシーケンスでローカルな編集を行うか、あるいはプログラム全体の大幅な書き換えを行うかを決めます。
これは興味深いですね。ここでは完全にオープンです。メタハーネスはやりたいことは何でもできます。これはオープンなClaudeではありませんが、このコードシーケンスは世界中のすべての可能性を秘めているのです。こういう言い方をしておきましょう。しかし、シンプルなユーザーに対するいくつかの推奨事項が提示されています。
彼らは「優れたスキルを書くことが不可欠だ」と言っています。それは何でしょうか?「スキルテキストは探索を導くための主要なインターフェースであり、その品質はループがどう働くかに関する最も強力なレバーである」と彼らは語っています。ですから提案として、私たちのLLMはA)その役割、B)ディレクトリレイアウト、C)CLIコマンド、そしてD)出力フォーマットを定義する自然言語のスキルを受け取ります。
したがって実際には、スキルは提案者の診断手順ではなく、出力と安全性に関連する動作を制約すべきです。何が禁じられているか、どんなアーティファクトを作成すべきか、そして正確にどの目的を最適化すべきかを指定する一方で、必要に応じてスコア、履歴、以前のコードを検査する自由をモデルに残しておくべきだということです。
これは興味深いです。私たちが普段skill.mdファイルに書く内容とは一致していません。彼らは2つ目の推奨事項を挙げています。ベースラインのハーネスと、解決が本当に困難な検索セットから始めることです。単純なベースラインのフューショットプロンプティングなどを作成し、ベースラインが常に間違える例をフィルタリングするか、本当に難しいインスタンスの多様なサブセットを選択して検索セットを構築します。
そして、ベースラインが評価においてすでに飽和状態にある場合、検索には最適化する余地がほとんどないと彼らは主張しています。1回の実行あたり約50回の完全な評価が行える程度に検索セットを小さく保ちます。そして各実行には約100の例が含まれます。興味深いですね。絶対に魅力的です。前にお伝えしたように、GitHubリポジトリStanford AI Labのここにメタハーネスからアーティファクトまでがあります。素晴らしい。
ご存知のように、この著者のグループにはDSPyの著者がいます。素晴らしいですね。では詳しく見てみましょう。一体何が違うのでしょうか?DSPy。すみません、プロンプトエンジニアリングは石器時代に戻りました。プロンプトテンプレート自体、制御フロー、モジュール式の大規模言語モデルパイプラインに対して高レベルのインターフェースを提供することで、プロンプトエンジニアリングをより体系的なものにしました。
しかし考えてみてください。DSPyについての私の動画をご覧になったなら、DSPyの魔法でさえ、それをLean 4と接続したとしても、フレームワークは依然として検索ポリシーの後に、またはメモリ更新構造の後に、あるいは少なくともほとんど常にオーケストレーションロジック自体の手動設計を典型的に必要とします。
そして今、私たちは「これが古いDSPyだ」と言います。どうなると思いますか?メタハーネスに統合された新しいDSPyでは、これらすべてがAIによって行われるのです。メタハーネスは異なるレベルで動作します。実行可能コードにおけるポリシーの実装を探索し、ハーネス自体を最適化のターゲットとして扱います。お話ししたように、私たちのコアLLMの周りにあるこの点群が、今やさらなる数学的最適化手順の対象なのです。
シンプルですね。言ってみれば、ここのDSPyは今やメタハーネスのサブセット、サブ要素になったわけです。絶対に魅力的なのはGatoです。Gatoは一度に1つの候補で動作します。1ステップあたり約8,000トークンで、どの情報が関連しているかを予測しなければならない固定の批評フォーマットを持っていたことを覚えているでしょう。もし私の動画を見ていないなら、これはGatoの新しい遺伝的AIで、Berkeley、Stanford、Data Bricks、MITによるものです。7ヶ月前にGatoについて詳しく説明しました。
しかし覚えていますか、つい数日前、新しい論文を紹介しました。それはGatoが本当に完璧なシステムではないというものでした。なぜならGatoは局所的な最小値にロックインしてしまうからです。そして、V Starと呼ばれる新しいマルチエージェントシステムがあるとお伝えしました。これは、仮説生成とプロンプトレライトを分離する新しいフレームワークであり、それによって意味的にラベル付けされた仮説、ミニバッチ検証、そして最終的に最適化の軌跡を可能にします。
そしてこのV Starは、例えばプロンプト機能のグローバルな極値を本当に検出することができました。すべての詳しい情報は動画にあります。人間のプロンプトはAIにとって最も複雑なものです。つまりGatoがあり、Gatoを理解しています。ここでのGatoの最適化も知っています。そして今、Gato自体が、言ってみればメタハーネスの一部になるか、統合されることができるのです。
なぜなら、メタハーネスは現在、提案者にすべての過去の候補へ同時にアクセスさせ、何を調べるかをエージェントに決定させるからです。さて、突然Claude Codeの目の前に1000万トークンが現れ、何を最適化するかをそれが決定するということを理解するのには少し問題を感じます。この学習プロセスをどのように構成するのでしょうか?このシステムをドメイン固有の知識でどのように事前条件付けし、コード最適化のために最も重要な候補を本当に探すようにするのでしょうか?
そして私は、すべてが制御フロー最適化定理に戻ってくると考えています。そして、ほんの2026年3月19日の論文である「展望」というこの動画で、すでにお見せしました。そこでは未来の仕事は何かと議論しました。多様なタスクにわたって大規模な最適化の軌跡を収集し、意味的な類似性によって失敗ケースをクラスタリングし、そして繰り返されるパターンをヒューリスティックなカテゴリーに自動的に抽出することです。
そして今、つまり2週間後、スタンフォードとMITによるこの新しい論文が登場し、彼らはまさにこれを提案しているのです。ご覧の通り、私たちはそれほど的外れではありません。私たちはAIの未来に向けた明確で美しい軌跡の上にいます。私たちの動画や議論しているトピックの的を完全に射ています。
しかし、私が言ったようにあなたがチャンネル登録者であれば、単にエージェントに何を検査するかを決定させるだけではないことを理解したはずです。エージェントはLLMやコードシステムであり、統計的なシステムだからです。私たちはより高い精度を求めています。そしてどうやってより高い精度を達成するのでしょうか?それは、ニューロシンボリック・スケーリングによってです。
推論時ではなく、もちろんトレーニング時にも行えますが、私たちは純粋な統計データ構造から、トポロジカルな解空間を持ち、バックグラウンドに明確な数学的定理を伴って動作する、より構造化された記号的ソルバーアーキテクチャへとどうにかして切り替えなければなりません。そして、最高の実用的なパフォーマンスを得るために、これらの統計的なアイデアの多くを切り捨てる必要があります。
ですから展望としてあえて言うなら、これは論文には書かれていませんが、私の個人的な意見です。メタハーネスから次の段階へ進むとき、この特定の時期に同じような発展が起こるでしょう。統計的システムとしてのメタハーネス、そして統計的コアシステムに対する数学的最適化としてのメタハーネスは、将来に向けて非常に多くの可能な最適化軌跡を生み出すため、どんなAIシステムよりも、何らかの記号的ソルバーシステム(Lean 4でも何でもいいですが)、この場所に本当に構造と論理をもたらすような明確な数学的・トポロジカルな解空間の最適化が必要になるでしょう。
これで動画は終わりですが、私のことをご存知ですよね。スタンフォードとMITが4ポイントの改善を祝っていることは知っています。しかし、この4ポイントの改善は私にとって問題を引き起こします。なぜでしょうか?説明させてください。
再度お伝えしますが、ここには推論のみを行うコアLLMがあり、そしてすべてが含まれる極めて複雑で美しいファイルシステムがあり、特定のコードシーケンスのために最適化を行うLLMがあり、それで4ポイントを得るのです。これが私の黄色いコードだとしましょう。このシーケンスで1ポイント最適化し、論文で確認したところそれは1パーセントポイントであり、コードの2番目のシーケンスでもう1パーセントポイント最適化します。合計で、非メタハーネスシステムに対して4PP(パーセントポイント)の改善が得られるとしましょう。
しかし、これは私に疑問を抱かせます。このすべての最適化、すべての数学、現在私たちの複雑なファイルシステムのインタラクティブなパターンマッチングを最適化しているこの特定のLLMのすべてのトレーニングの後で、これだけなのでしょうか?これが何のようなにおいがするか分かりますか?これらの4PPは、このシーケンス、このシーケンス、そしてこのシーケンスのコード最適化を示しているだけだというにおいがします。
つまり、これは最小限のコード適応にすぎません。彼らは論文の中で例を挙げています。ぜひ論文を詳細に読んでみることを強くお勧めします。彼らは説明し、例を挙げ、達成できた最高の例を示しています。しかし、もしかしたら私の限られた脳のせいかもしれませんが、それらを読んでみてください。私の解釈では、それらの例は単なるコード最適化です。Claude Codeなら、ここに新しいLLMのクリーンなビームがなくてもできることです。
では、それは何を意味するのでしょうか?私が期待していたのは、私のコード構造、トポロジー、コードの複雑さを取り上げて、小さな単一ステップを1パーセントポイントの改善で最適化することではありませんでした。私がシステムに期待していたのは、解決策の完全に新しい構成を思いつくことでした。完全に新しいトポロジーを持ち、人間の私が黄色いシーケンスで実装することすら考えつかなかったような異なる要素を組み合わせることです。
なぜなら、人間の私はそれほど賢くなかったからです。しかし、何百万ものGitHubリポジトリを取り込んだこのAIシステムなら、現在私が求められているこの特定のタスクについて理解するのに十分なパターン認識を持っており、完全に新しい解決策を思いつくはずです。そしてこの完全に新しい解決策が、24PP(パーセントポイント)の改善をもたらしてくれる。これこそが私が期待していたことです。
そして、4から最大7PPという結果の性質そのものが、私にとってはこれがシステム最適化ではないという単なる指標なのです。もしシステム最適化なら私たちはもっと先の段階にいるはずですが、これはコード空間のサブ部分、サブコード要素の単なるコード最適化であり、私たちはまだそこには到達していません。
なぜなら、この1パーセントポイントの改善は私にとって自己学習ではないからです。自己学習は私にとって、その向こう側にあるものです。したがって、この研究を読んだ後の私の個人的な意見としては、私たちはおそらくまだ表面をなぞり始めたばかりだということです。しかし皆さんの意見にも興味があります。どう思われますか?
動画を楽しんでいただけたなら幸いです。いくつかの新しい情報があり、少し楽しんでいただき、ご自身で研究を読んでみたいと興味を持っていただけたなら嬉しいです。それでは、次回の動画でお会いしましょう。


コメント