Googleが新たにリリースしたGemini 3.1 Flash Liteは、大手AI研究所のモデルラインナップの中で最も過小評価されているモデルの一つである。メディア処理、文書処理、エージェント実行など幅広いタスクにおいて、他のどのモデルよりも高速に動作する。このモデルは翻訳、音声文字起こし、構造化出力、PDF処理、モデルルーティングなど6つの主要なユースケースで優れた性能を発揮し、特にマルチモーダル理解とコスト効率の面で競合モデルを圧倒している。ベンチマークでは、GPT-4o miniやClaude 4.5 Haikuを上回る性能を示しながら、出力速度は毎秒363トークンとGrokの2倍以上を記録している。
最速かつ最もコスト効率の高いモデルの登場
Googleが先日、モデルラインナップの中で最も過小評価されているモデルの一つをリリースしました。皆さんはProモデルやFlashモデルばかりに注目していると思いますが、今回リリースされたFlash Liteこそが、おそらく最高のモデルだとお伝えしたいのです。メディア処理、文書処理、あるいはOpen ClawやClawbotの実行など、どんな用途であっても、このモデルは大手研究所の他のどのモデルよりもはるかに高速に処理を実行できるでしょう。
この動画では、このモデルについてすべてをお見せします。そして、このモデルの実行方法とタスクの遂行方法を正確に教えるコードを含む、5つの異なるユースケースを見ていきます。まずユースケースから始めて、その後モデルのパフォーマンスに戻り、ベンチマークの観点からモデルがどうなのかを見ていきましょう。
Gemini 3.1 Flash Liteの概要
この新しいモデルはGemini 3.1 Flash Liteです。このモデルは利用可能な最速のモデルの一つであり、これから見ていくGoogle Colaboratoryノートブックを通じて、多くのタスクで極めて優れた性能を発揮します。このColabノートブックは元々、Google DeepMindチームの一員であるPatrickによって設計されたもので、私はここでそのコードを使用しているだけです。
このGoogle ColabノートブックをYouTubeの説明欄にリンクしますので、使用する場合は、まず最初にGoogle APIキーのシークレットを追加する必要があります。まだお持ちでない場合でも、設定は非常に簡単です。ここに行って、鍵のアイコンをクリックしてください。もしここにキーが表示されていない場合は、Gemini APIキーをクリックしてください。
Google AI Studioからインポートをクリックすると、既にキーが作成されているかどうかが確認されます。まだキーが作成されていない場合は、このボタンをクリックするだけです。Google AI Studio内で最初のキーを作成するページに移動します。キーを作成して、それをコピーしてください。ここに戻って、GOOGLE_API_KEYと全て大文字で入力し、ここに貼り付けます。
これだけです。このGoogle ColabノートブックをこのAPIキーだけで実行する準備が整いました。そして、無料のGoogle AI Studioアカウントを使って、これらすべてのことができます。何も支払う必要はありません。Google Geminiモデルにプログラムでアクセスするには、主に2つの異なる方法があります。1つはGoogle Vertex AIです。
GCP(Google Cloud Platform)の顧客であれば、Vertex AI経由でアクセスできます。しかし正直なところ、私を含む多くの人が、Google Vertex AI経由でのアクセスは非常に面倒だと感じています。ですので、本番環境のユースケースには十分ではないかもしれませんが、少なくともPCでの使用には向いています。Google GenAIを使えば、Google AI Studio経由で同じモデルにアクセスでき、しかも無料で行えます。料金を一切支払う必要がありません。
アプリケーションをインストールしたら、ここでキーをインポートする必要があります。これがGoogle APIキーです。それが完了したら、始めていきましょう。すべてのライブラリをインポートしました。それが完了したら、最初のタスクを始めます。
ユースケース1:翻訳タスクでの圧倒的性能
Googleが他のすべての競合を完全に圧倒しているタスクの一つ、小型モデルであるGemini 3.1 Flash Liteは、この特定のユースケースにおいて本当に見事です。ちょっとした逸話ですが、OpenAIの無料版チャットアプリケーションを翻訳に使っていた人を個人的に知っています。特にインドの言語、この場合はカンナダ語への翻訳で使っていました。カンナダ語は私が住んでいるバンガロールのあるカルナータカ州で話されている言語です。
その人にGeminiを紹介した瞬間、精度の大きな違いに気づきました。OpenAIは英語からカンナダ語、カンナダ語から英語への翻訳に全く信頼できなかったのです。Geminiを共有した瞬間、その人は驚き、今では専ら Geminiだけを使用しています。このモデルがどれだけ優れているかがわかります。
別のインド言語でもテストしましたが、インド言語でテストした理由は、明らかに私が理解できるからです。第二の理由は、これらがニッチな言語であり、モデルがこれらの言語を理解し、翻訳し、同じことを行って、例えばテキストを返すことに非常に優れている必要があるからです。
例えば、ここには「ねえ、後でピザを食べに行かない?お腹空いたよ」というテキストがあります。モデル名はclient.models.generate_contentの中で指定しました。システム構成があり、翻訳されたテキストのみを出力するように指定しています。そして、これが翻訳です。次のテキストを翻訳してくださいという指示を出しています。
print response.textと言っています。「ねえ」は「お腹がとても空いた」という意味です。「お腹が空いた(starving)」と言ったのに、それを非常に明確に理解し、完璧に翻訳してくれました。そして、この全体が1秒しかかかっていません。
この翻訳タスク全体が1秒で完了しました。このモデルは絶対的に優れています。大量の翻訳タスクがある場合、このモデルを使用できます。
ユースケース2:高速な音声文字起こし
2つ目は文字起こしです。別のメディアタスクです。MP3を取って文字起こしができます。そして、このモデルはおそらく翻訳を行う最速の方法の一つです。
このMP3ファイルを用意しました。これは一般教書演説で、このMP3ファイルは43分のMP3、ほぼ1時間近くあります。MP3ファイルをアップロードして、音声の文字起こしを生成してくださいというプロンプトを与えています。これはマルチモーダルモデルです。文字起こしを別々に行う必要はありません。
同じモデルで文字起こしができます。MP3も理解できます。そして、このプロンプトでclient.models.generate_contentと言いました。また、このようなプロンプトも使えます。音声の文字起こしを生成し、「えー」「あー」「その」などのフィラーワードを削除してください、と。生の文字起こしをする代わりに、このようなことができるのです。
コンテンツの中にコンテンツがあり、プロンプトとアップロードされたファイルがあります。そして、これが最終的なレスポンスで、最終的なレスポンスは5,274語です。43分という膨大な量で、これに30秒、37秒かかりました。これがこのモデルがかかった時間です。繰り返しになりますが、このモデルが非常に高速であるという事実の証です。
ユースケース3:構造化出力とエージェントタスク
軽量なエージェントタスクにこのモデルを使用でき、主にデータ抽出に使用できます。これも大企業組織では大きな部分を占めています。ここにPydanticクラスがあり、どのように見えるべきかを正確に記述しています。これがプロンプターがユーザーレビューを分析し、アスペクト、感情スコア、要約、引用を決定し、リスクを返す方法です。
ブーツは素晴らしく見えます。革は高品質ですが、サイズが小さすぎて返品します、というレビューです。モデルにこれらすべてを理解して、このような構造化出力、つまりJSON出力として正確に返してほしいのです。そして、モデルはそれを返してくれます。JSONスキーマとして使用しています。
これは、エージェントタスクにモデルを使用する場合の非常に重要なタスクです。モデルに正しい構造化JSONを出力してもらいたいのですが、モデルはここでそれを実行しています。アスペクトはフィット感です。要約の引用は「サイズがあまりにも小さすぎます」。感情スコアは2で、返品リスクは真(true)と書かれています。明らかに、その人が「返品します」と言っているからです。
ユースケース4:文書処理と要約
次は文書処理と要約です。繰り返しになりますが、文書処理については誰もがGoogleモデルを誓っています。世界最高の文書処理モデルの一つです。PDFファイル。これはMedge Geminiです。そして、PDFそのものを取って、ここでPDFをダウンロードし、PDFのコンテンツを取得し、それをPDFそのままモデルに送信しています。
ここで文書コンテンツがここに入り、PDFそのものとして入っていることがわかります。ここで文書処理を行うためにLlamaIndexのようなものを別途使用する必要はありませんし、Unstructuredも必要ありません。PDF理解のために、このモデルに直接送信でき、モデルはそれを受け取ります。
そして、プロンプトは基本的に、この文書を要約してください、というものです。PDF全体を取得し、要約すると、モデルが要約し、わずか381語で返してくれたのがわかります。これに約2分かかりました。
膨大な文書、PDF処理、データの取得、そしてJSONのような構造化情報に変換することもできます。ファインチューニングに使いたい場合も、これらすべてのことができます。モデルは素晴らしい仕事をしました。コードについては詳しく説明しません。主な理由は、コードを皆さんと共有するからです。自分で実行できます。コードがどのように見えるかを確認できます。
ユースケース5:モデルルーティング機能
次はモデルルーティングです。多くの人が私によく尋ねることの一つは、すべてのユースケースに対して常に最も高価なモデルを使用する必要があるのはなぜですか?最も高価なモデルに送るべきか、最速のモデル、最も安いモデルに送るべきかを判断するような、ある種のモデルルーターを使用できませんか?というものです。
そして、このモデルは非常に高速なので、モデルルーティング機能に使用できます。これが例です。Flashモデルがあります。Proモデルがあり、これはシステムプロンプトのようなものです。動画を一時停止して、ご自身で読んでください。
そして、ここに非常に小さなユーザー入力があります。エラーが出ています。プロパティ、つまりマップのプロパティを読み取れません(undefined)。保存ボタンをクリックすると、これを修正できますか?この質問はProモデルに送られるべきですか、それともFlashモデルに送られるべきですか?
モデルはこれを確認します。レスポンススキーマがあります。モデルはこれを確認して、典型的な機械学習のコンテキストでの分類ジョブのようなものを行います。これはProモデルに送られるべきか、Flashモデルに送られるべきかを判断します。Proモデルに送られるべきだと言いました。
そして、その理由は、これはコードの検査を必要とするデバッグタスクだからです、云々、と言いました。だからProモデルに送られるべきなのです。このモデルはモデルルーターとしても機能でき、思考モードをオンにしてこのモデルを使用することもできます。つまり、内部推論モデルです。
モデルは内部思考連鎖を持つことができ、ここで見ることができるように、thinking_configuration = thinking_level highと言えます。これを指定すると、モデルは自分自身で熟考し、内部思考連鎖を持ち、より多くの時間をかけて答えを返します。モデルがより長く考え、思考により多くのトークンを持つときに、モデルがどのように動作するかを見ることができます。
ユースケース6:バッチAPI処理
最後に、大量の文書がある場合や、一晩実行できるようなタスクがある場合、このモデルをバッチAPIとして使用できます。私はこれを実行しませんでした。実行したくなかったのですが、これはバッチAPIの実行方法の例です。
ご覧のとおり、モデルが非常に優れている6つの異なるユースケースを強調しました。このモデルを使用できる他の多くのユースケースがあります。
例えば、プロンプト拡張を行いたい場合にこのモデルを使用できます。ユーザーが短いプロンプトを与えていて、プロンプトが良くない場合、より長い詳細なプロンプトが必要なら、このモデルを使用できます。古典的なMLタスク、古典的なNLPタスクに対して、自分のモデルを構築したくないが、LLMを使用したい場合、例えばこの分類タスクのようなものを見ました。このモデルを使用できます。
モデルはこれらすべてのタスクで非常に優れていますが、ここで最も重要なことは、モデルがこれらのことで非常に優れているだけでなく、モデルも非常に高速だということです。モデルがどれだけ優れているかを理解していただくために、1つのコードを実行します。少し変更して、異なる出力があることがわかるようにしますが、「返品します」は送りません。なぜなら、すでに着用したからです。
これを実行すると、ここで既に完了していることがわかります。もう一度、完了しました。返品リスクは偽(false)です。感情スコアは増加しませんでした。サイジングのアスペクトです。ご覧のとおり、非常に高速なモデルですが、まともな機能を備えています。
ベンチマーク性能の比較
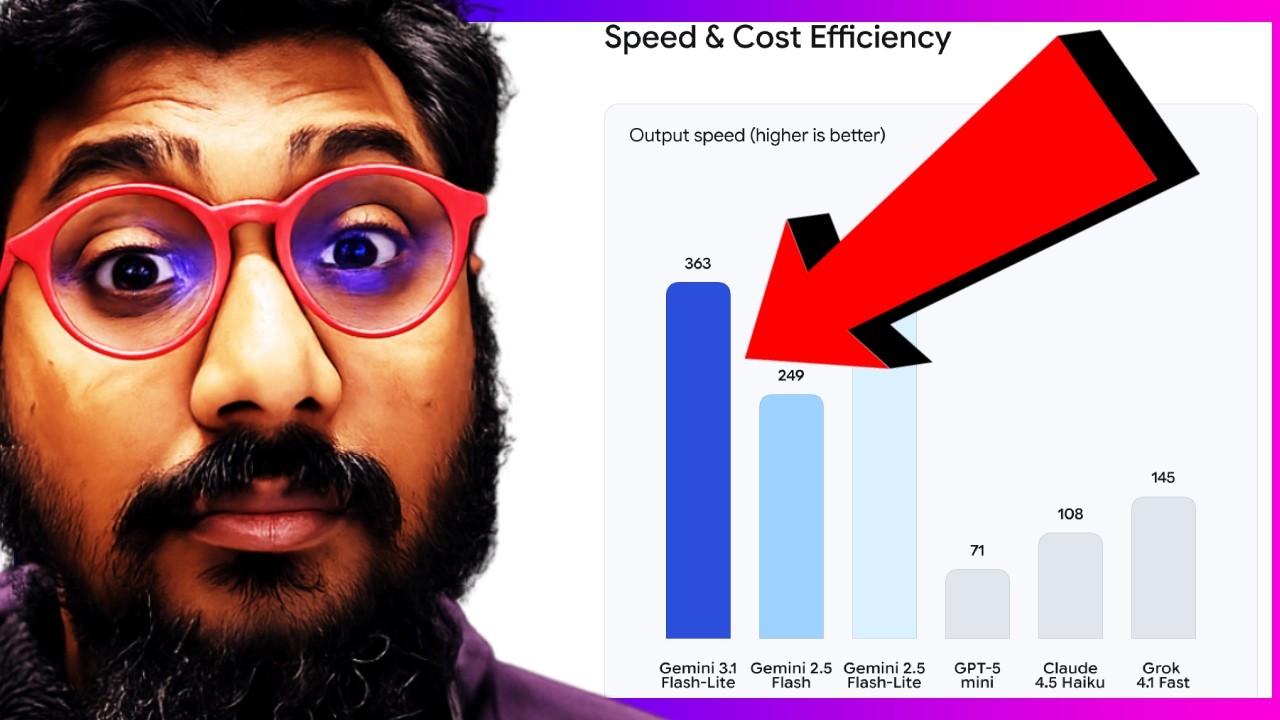
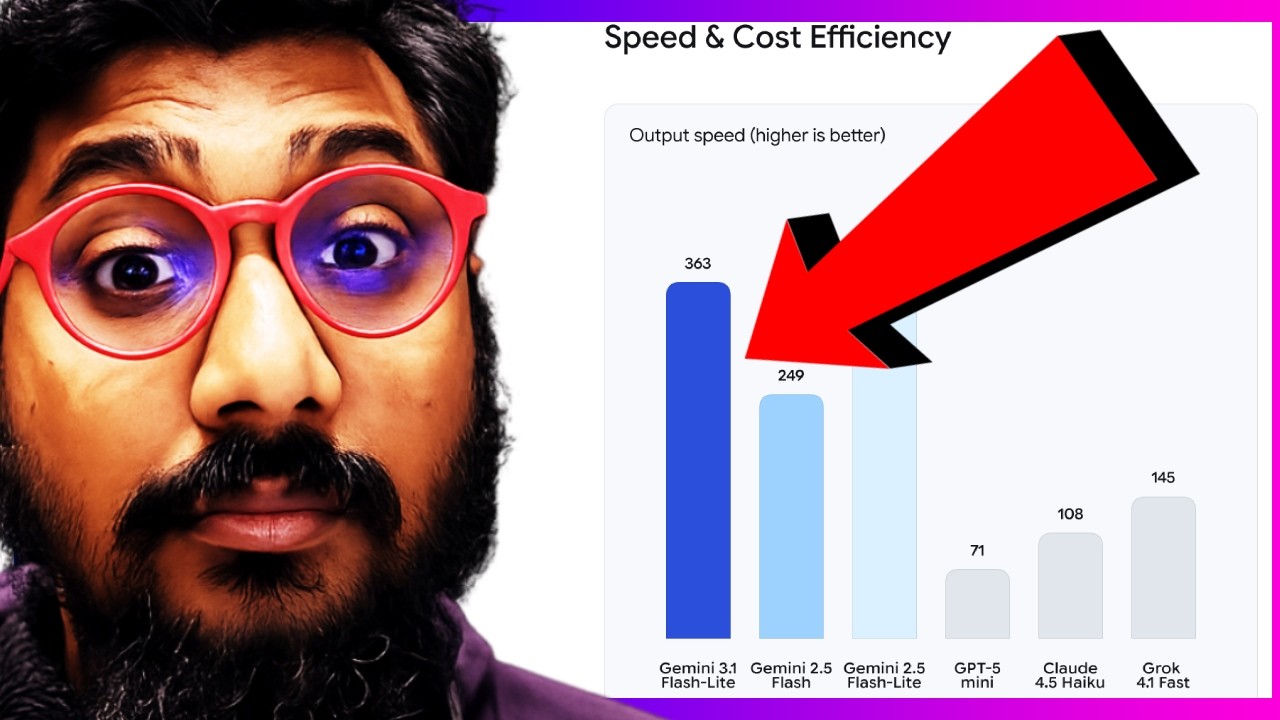
Googleが共有したベンチマークです。これがGemini 3.1 Flash Liteです。そして、これがGemini 2.5 Flash、以前のバージョンで、Liteバージョンではなく、完全版です。
そして、Gemini 2.5 Flashがあります。GPT-4o mini、Claude 4.5 Haiku、Grok 4.1 fastなど、さまざまなプロバイダーからの他の高速モデルがあります。私が知っている多くの人は、高速だからという理由でGrokを好んでいます。
GPQAでは、このモデルが他のすべてを打ち負かしています。MMU Proでは、このモデルが他のすべてを打ち負かしています。マルチモーダル理解では、このモデルが再びマルチモーダリティで輝いていて、どのモデルもこれに近づきません。
実際、GPT-4o miniは82.5を記録し、このモデルは84.8を記録しました。Simple QA、これも文書の質問応答タイプのものです。モデルは43.3%を記録しました。MMLUでは、モデルは88.9%を記録しました。そして、Live CodeBenchのようなコーディングベンチマークでさえ、モデルが72%を記録したのに対し、GPT-4o miniは80%を記録したことがわかります。
これはGemini 2.5 Flashよりも優れています。そして、長いコンテキストでは、モデルは128,000平均トークンで60%を記録しました。コスト面でモデルは非常に優れています。例えば、GPT-4o miniやClaude 4.5 Haikuなどの他のモデルと比較すると、このモデルはコストの面で完全に圧倒しています。
トークン速度の面では、ここでの出力トークンは毎秒363トークンです。そして、価格面で最も近い最速のGrokは145です。つまり、モデル速度、スループットパフォーマンスの面で、Grokが行っていることの2倍の速度です。モデルは非常に優れています。
実際のデモンストレーション
このモデルがどれだけ高速かを非常に簡単にデモでお見せしたいと思います。これが私のGoogle AI Studioで、このモデルにアクセスする方法も学べます。Google AI Studioに行きます。APIキーのページに行きます。ダッシュボードに戻ります。そうしたら、ここでモデルを探索できることがわかります。
これをクリックして、この特定のモデルを選択します。これらのどれも必要ありません。Gemini 3を選択したいのです。あ、大変。非常に多くのモデルがあります。Geminiに行きます。ここに行きます。Liteです。Liteを検索します。Gemini 3.1 Flash Lite。これを取得しました。
非常にシンプルなプロンプトを与えます。プロンプトは、Littleと呼ばれるアプリのために、緑と太陽のグラデーションを使用した美しく見えるランディングページを作成してください。マシン用の十分なページがあることを確認してください。
そして、美しいフルアニメーションがあります。プロンプトを入力するのにかかる時間よりも時間はかからないでしょう。プロンプトが46トークンかかったことがわかります。これを実行します。このモデルを選択したことがわかります。これを実行します。単一のHTMLファイルのみをくださいと言うべきでした。
さて、これを停止させます。私のミスです。単一のHTMLファイルのみをくださいと言います。これを実行すると、単一のHTMLファイルが得られます。そして、非常に高速であることがわかります。完了しました。今話している時点で既に完了しています。これを編集するつもりはありません。これを実行してここを見ることができます。プレビューを表示します。
モデルにとって最も重要なことは、速度などはさておき、まずコードが動作しなければならないということです。それが最も重要なことです。そして、ここで私たちの指示に従ったことがわかります。カラーコードがあります。作業を始めるための実用的なプロトタイプを与えてくれました。
ランディングページを作成してくれたことがわかります。ここにいくつかのアイコンがあります。ここにアニメーションがあります。明らかに、これをそのまま正確に使用するつもりはありません。しかし、これを使用できる場所は、例えばeコマースストアがある場合、このモデルを使用してストアの充填ができます。ストア全体をこれで埋めることができます。
第二に、プログラマティックSEOのためです。プログラマティックSEOに詳しい人にとって、これらの人々が大好きなことの一つは、一度に数百のページを起動することです。そして、非常に高速なページ生成にこのモデルを使用できます。明らかに、多くの人はこれを好まないでしょうが、大規模に粗悪なコンテンツを作成できます。
総合評価と今後の展望
全体として、これは素晴らしいリリースだと思います。あまり多くの人がこれについて話していませんが、私は以前のLiteモデルの大ファンで、このモデルを多くの異なる人々に絶対に推奨するつもりです。実際、Open ClawやClawbotでこのモデルを使用して、モデルがどれだけ優れているかを確認したいと思います。基本的なツール呼び出しについては、このモデルは良い仕事をしているからです。
このモデルについてどう思うか、コメント欄で教えてください。Google ColabノートブックをYouTubeの説明欄にリンクしますので、コードを試して、自分のユースケースに使用してください。別の動画でお会いしましょう。ハッピープロンプティング。


コメント