Anthropicが新たにリリースしたClaude Opus 4.6は、前バージョンのOpus 4.5を大きく上回る性能を持つ画期的なモデルである。最大の特徴は100万トークンのコンテキストウィンドウと、より長時間にわたってエージェント的タスクを持続できる能力にある。コーディング、財務分析、文書作成など幅広い領域で性能が向上しており、特に大規模コードベースでの動作信頼性とデバッグ能力が強化された。さらに、複数のClaude Codeインスタンスを協調させる「エージェントチーム」機能により、並列作業が可能になった。この進化は、SaaS企業の市場価値に大きな影響を与えており、AIが従来のビジネスツールを代替する時代の到来を示唆している。

Claude Opus 4.6の登場とその衝撃
Claude Opus 4.6がついに登場しました。これはOpus 4.5からの大きな前進であり、実は早期アクセスを得て実際に使ってみたのですが、本当に素晴らしい性能です。すべてをお伝えしましょう。
公式ブログ投稿によると、Opus 4.6はより慎重に計画を立て、エージェント的タスクをより長時間持続でき、大規模なコードベースでより信頼性高く動作し、さらに自身のミスをキャッチするコードレビューとデバッグのスキルが向上しています。
ここで重要なのが「エージェント的タスクをより長時間持続できる」という点です。これはすべてのコーディングモデルが向かっている方向性なんです。よりエージェント的になり、より長い時間軸で実行でき、サブエージェントに作業を委譲できるようになる。これが業界全体が向かっている方向です。Claude Code、Codeex、Cursor、さらにはClawdbotでもこの傾向が見られます。
ちなみに、これをClawdbotに組み込むのが本当に楽しみなのですが、まだ実現できていません。進歩の速度を見てください。これは完全に垂直な線です。対数スケールになっています。ここで見られるのは、モデルが自律的に成功裏に実行できる時間の量です。
具体的には、これは異なるLLMが50%の確率で完了できるソフトウェアエンジニアリングタスクの時間軸を示しています。見てください、GPT-5.2 highは6時間半以上自律的に実行し、タスクを成功裏に完了しています。まさに今お話ししているのがこれです。エージェント的自律性の時代が到来しているのです。
100万トークンのコンテキストウィンドウという画期的な進化
このグラフは数日前に公開されたもので、今日時点で2つの新しいモデルがあります。先ほど述べたOpus 4.6と、この動画を録画している最中に、GPT-5.3が発表されました。それについては別の動画を近日中に作成する予定です。でも、これらのモデルがこのチャートでどう見えるのか気になりますね。
Opus 4.6のもう一つの特別な点を知りたいですか? それがこちらです。100万トークンのコンテキストウィンドウです。現在ベータ版ですが、GoogleのGemini以外でこれを提供しているのはAnthropicだけです。これはAnthropicチームにとって大きなマイルストーンです。
Claudeモデルファミリーや、OpenAIのモデルファミリーの平均的なコンテキストウィンドウは約20万トークンでした。そして今、100万トークンのコンテキストウィンドウを手に入れたのです。これはあらゆる面で役立ちますが、特に大規模なコードベースで威力を発揮します。
しかし、大きなコンテキストウィンドウを持つだけでは不十分です。その100万トークン全体にわたって品質を維持できなければなりません。時々、いやよくあることですが、「コンテキスト劣化」と呼ばれる現象が起こります。
コンテキストを増やせば増やすほど、モデルがそのコンテキストウィンドウから必要なものを見つけ出すのが難しくなります。Opus 4.5との比較ベンチマークをすぐにお見せします。
財務分析から文書作成まで、広がる活用領域
Opus 4.6は財務分析の実行、リサーチの実施、文書やスプレッドシート、プレゼンテーションの使用と作成において改善を遂げています。これらはすべてClaude CodeとClaude Co-workの両方に関連しています。
もしClaude Co-workを使ったことがないなら、ぜひ試してみることをお勧めします。ちょうど昨日、「SaaS黙示録」と呼ばれる出来事がありました。基本的に、大手SaaS企業の時価総額から3000億ドルが消し飛んだのです。
多くの人々が指摘しているのは、Anthropicがさまざまな業務ツール向けのプラグインを大量にリリースしたという事実です。これによりClaudeはこれらのツール内で基本的に作業を行えるようになりました。
その理由は、Claudeがますます多くの作業をこなし、アプリケーションを作成し、チャットインターフェースを通じてすべてを自律的に実行できるようになれば、SaaS企業はビジネスを失うことになるからです。そして今、Opus 4.6によってそれがさらに顕著になっています。繰り返しますが、Co-workを試したことがない方は、ぜひ使ってみてください。
そしてOpus 4.6を今すぐ試すことができます。Boxは独自の評価をまとめました。彼らはOpus 4.6への早期アクセスを得て、大幅な改善も確認しました。この動画をスポンサーしてくれたBoxに感謝します。彼らが発見したことをお見せしましょう。
Boxによる実証評価と驚異的なスコア向上
これはOpus 4.6を使ったBox AIの複雑な作業評価です。黄色がOpus 4.6で、紫がOpus 4.5です。これらはエンタープライズコンテンツに関する困難な推論タスクです。数千の文書について推論し、異なる文書間の点と点を結びつけるようなタスクを考えてください。これがこのベンチマークです。
完全なデータセットでは、Opus 4.6で10%の向上が見られます。データからのレポート作成、つまりデータを読み取ってそのデータについてのレポートを作成する部分では、ベンチマークスコアが実際に倍増しました。Opus 4.5からOpus 4.6へと36%から75%になったのを見てください。
デューデリジェンス部分のベンチマークでは、45%から51%に上がっています。具体的な業界別に見てみましょう。公共部門が68から75、金融サービスが66から71、ライフサイエンスとヘルスケアが大きく跳ね上がって39から64、そして法律が45から51です。
これらは単一のドットバージョンアップとしては大規模な改善です。Boxは、文書、契約書、研究論文、製品デザイン、財務諸表から真の価値を引き出すのを支援します。すべてをBoxに読み込んで、Box AIに作業をさせましょう。Boxの使用を強くお勧めします。リンクは下に貼っておきます。
主要ベンチマークでの圧倒的優位性
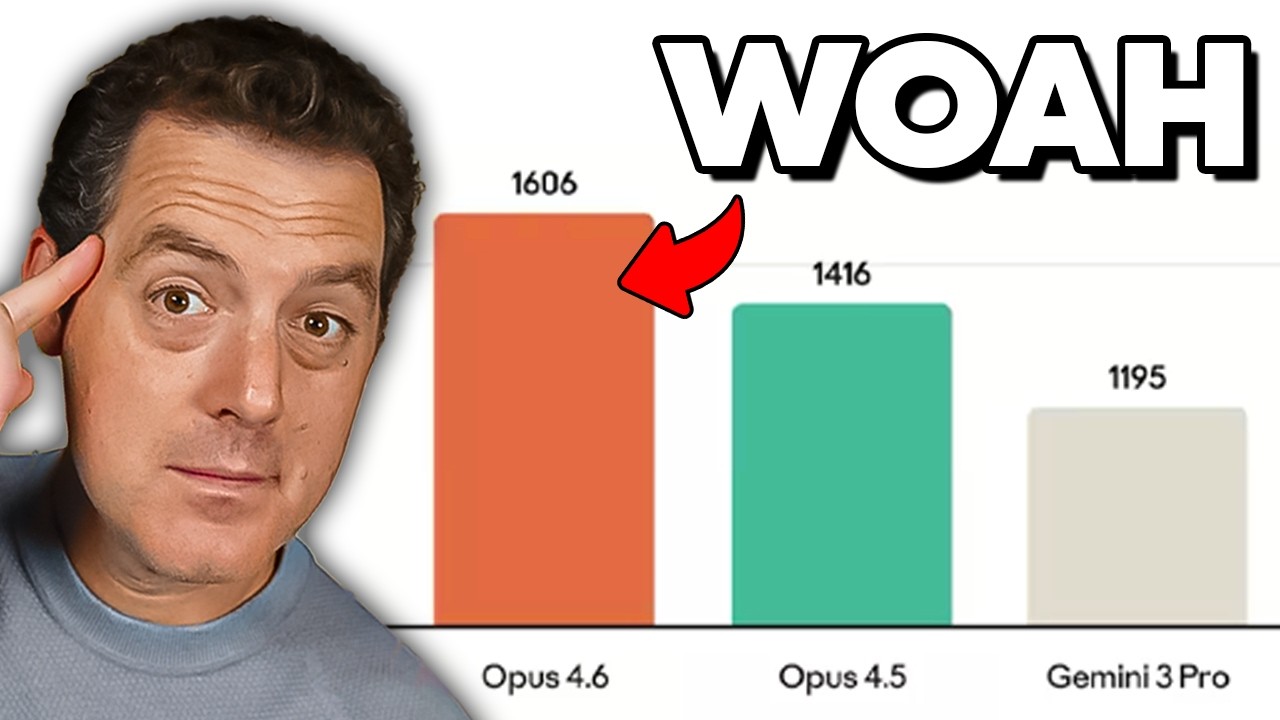
ベンチマークを見ていきましょう。皆さんが見たいと思っているはずですから。これはGDP Valで興味深いのは、これが実際にはOpenAI自身のベンチマークだということです。
ナレッジワークのスコアです。Opus 4.6はELOスコア1660で、Opus 4.5から200ポイントの跳躍です。そしてGPT-5.2は1462です。Opus 4.6より150ポイント低いです。Gemini 3 Proは1195で、他のモデルをはるかに下回っています。
こちらはBrowse Compベンチマークです。これはエージェント的検索です。Opus 4.6は84点を記録しています。Opus 4.5から20ポイントの上昇です。こちらにGPT-5.2 Proがあります。繰り返しますが、5.2と比較しているのは、このチャートで利用可能だからで、まだ5.3を確認する機会がありませんでした。
こちらはTerminal Benchで、Opus 4.6は65.4%です。Opus 4.5から6ポイントの上昇です。しかし驚くべきことに、GPT-5.2 Codeexは実際にほぼ同じスコアです。
そしてHumanity’s Last Examです。ここで見られるのは、ツールありが濃い色で、ツールなしが薄い色で、53対40です。これはOpus 4.5の53対43と比較してのものです。はい、Opus 4.6は全体的に、地球上で最高のモデルです。
エージェントチームという革新的機能
それだけではありません。今、「エージェントチーム」という新機能があります。エージェントスウォームに少し似ています。多くの企業が異なる名前で呼んでいますが、本質的には同じものです。
1つのモデルが複数のサブエージェントに委譲し、それらに作業をさせ、その作業を時間をかけてオーケストレーションできるのです。エージェントチームのドキュメントを見てみましょう。非常に興味深いです。
エージェントチームを使えば、複数のClaude Codeインスタンスが協力して作業するのを調整できます。1つのセッションがチームリーダーとして機能し、作業を調整し、タスクを割り当て、結果を統合します。
チームメイトは独立して作業し、それぞれが独自のコンテキストウィンドウを持ち、互いに直接コミュニケーションを取ります。これを読んでいて聞こえてくるのは、トークン、トークン、トークンという言葉だけです。Opusはすでに非常に高価です。Claude Codeのようなものはすでに大量のトークンを使用しており、今度は基本的に複数のClaude Codeインスタンスを並行して立ち上げることになります。私に聞こえるのはGPUがブンブン動く音だけです。
しかし興味深いことに、実際にはサブエージェントとは異なると言っています。説明させてください。単一のセッション内で実行され、メインエージェントに報告するだけのサブエージェントとは異なり、リーダーを経由せずに個々のチームメイトと直接やり取りすることもできます。
エージェントチームを使うべき場面とは
では、いつエージェントチームを使うべきでしょうか? エージェントチームが最も効果的なのは、並列探索が真の価値を追加するタスクです。
リサーチとレビュー、新しいモジュールや機能、競合する仮説を使ったデバッグ、そして階層間の調整です。例えばリサーチとレビューでは、メインの調整エージェントに異なるパスについてのリサーチを行わせ、そのリサーチが完了したら戻ってきて意見を比較させることができます。
ここが重要です。エージェントチームは調整のオーバーヘッドを追加し、単一のセッションよりも大幅に多くのトークンを使用します。
サブエージェント対エージェントチームの考え方について、主な違いは次のとおりです。コンテキストについては、サブエージェントはそれぞれ独自のコンテキストウィンドウを持ちますが、すべてメインエージェントに報告し、そこに統合されます。一方、エージェントチームは完全に独立しており、それらのチームメイトそれぞれと直接やり取りできます。
コミュニケーションについて言えば、エージェントチームではチームメイトが互いに直接メッセージを送れますが、サブエージェントを生成する単一のエージェントでは、それらのサブエージェントは元のメインエージェントにしか報告できません。
調整についても同様で、メインエージェントがすべての作業を管理するのに対し、エージェントチームでは共有タスクリストと自己調整があります。トークンコストについては、サブエージェントの方がはるかに少ないです。
より細かい制御と適応的思考
Claudeは実際の推論プロセス中に起こることに対して、はるかにきめ細かい制御も提供しています。1つは、APIを使用してコンパクション(圧縮)を行うことができます。
これは大きなコンテキストを縮小して圧縮するものです。明らかに、コンパクションを行うと忠実度が失われ、時には重要な側面が失われます。しかし、拡張されたコンテキストウィンドウは、より長い間、より多くのコンテキストを保持するのに役立ちます。
また、「適応的思考」と呼ばれるものも導入しています。モデルは実行中に、実際に思考量を上下に調整できます。つまり、実際にタスクを実行している間、タスクのコンテキストに応じて、より多くの思考、より少ない思考を調整できるのです。本当にクールです。
新しい労力制御もあります。知能、速度、コストについて、よりきめ細かい制御が得られます。
しかし、次の行こそが、Microsoftが今少し恐れているかもしれない理由であり、SaaS黙示録が起こった理由です。Claude in Excelに大幅なアップグレードを行い、Claude in PowerPointをリサーチプレビューでリリースしています。
これは、これらのエージェントが人々が毎日使うツールで素晴らしい仕事をしているからです。しかしそれはAnthropicの独自ツールではありません。競合他社のツール、Microsoftのツールで行っているのです。これがどう展開するか見るのは興味深いです。
価格設定とモデルの思考の深さ
価格設定はこうです。Opus 4.6はOpus 4.5と同じ価格です。はい、依然として高価です。
20万トークン未満のプロンプトの場合、入力100万トークンあたり5ドルです。20万以上の場合は10ドルです。
出力については、プロンプトが20万トークン未満の場合は100万あたり25ドル。20万以上の場合は37.50ドルです。もちろん、プロンプトキャッシングを使用することで大幅な割引が受けられます。
Anthropicによるモデルの雰囲気について少し。これを聞いてください。Opus 4.6はしばしばより深く、より慎重に考え、答えに落ち着く前に自身の推論を再検討します。
これはより難しい問題でより良い結果をもたらしますが、より単純な問題ではコストとレイテンシが増加する可能性があります。もちろん、/effortで常に調整できます。
100万トークンの真の実力とコンテキスト劣化への対応
100万トークンについて話しましょう。これがこれまでで最大のブレークスルーである可能性があるからです。先ほど、100万トークンを持つことだけが重要ではないと言いました。
実際にその100万トークン内で高品質を維持できなければなりません。モデルは実際に100万トークンすべてを読み、理解し、それらすべてのトークン間でつながりを作ることができなければなりません。そしてそれがOpusが輝いているところのようです。
これを聞いてください。Opus 4.6は、大量の文書セットから関連情報を取り出すのがはるかに優れています。
これは長いコンテキストタスクにも及び、数十万トークンにわたって情報を保持し追跡する際のドリフトが少なく、Opus 4.5でさえ見逃してしまうような埋もれた詳細も拾い上げます。多くの人がコンテキスト劣化について不満を言っていますが、Opus 4.6が顕著に優れているのがその点です。
実際にどう見えるか見てみましょう。これはMRCV2 8 needleで、干し草の山に針を探すものです。基本的に小さな情報を大規模なコンテキストウィンドウに落とし込み、その情報を取り出そうとします。単一のコンテキスト上に8つの異なる情報があります。
Opus 4.6の長いコンテキスト取得を見ると、25万6千トークンで93%の精度です。
それを100万トークンに上げると、76%の精度になります。確かに低下していますが、コンテキストのサイズを4倍にしているのですから、これは予想通りです。そしてこれがSonnet 4.5との比較です。明らかに大幅な改善です。
長いコンテキスト推論も改善されています。繰り返しますが、取得だけでなく、そのコンテキストで実際に物事を行うことができることが重要です。Opus 4.6が72対Sonnet 4.5の50、そしてBFS100万では38対Sonnet 4.5の25.6が見られます。
追加ベンチマークと実世界での性能
もう少し簡単なベンチマークです。これは根本原因分析で、見ての通り、Opus 4.5からOpus 4.6への良好な上昇が見られます。多言語コーディングについては、ほぼ同じです。わずかな上昇です。
長期的な一貫性。これは興味深いものです。Vending Benchです。これはモデルに実際の自動販売機を管理させ、利益を出せるかどうかを見るものです。見ての通り、Opus 4.5は5000ドル稼ぎました。Opus 4.6は8000ドルです。大幅な改善です。
これと比較して、Gemini 3 Proが5000ドル、GPT-5.2が3500ドルです。サイバーセキュリティとライフサイエンスでも改善が見られます。
そしてもちろん、アライメントと安全性について語らないAnthropicはありません。ここで、全体的な不整合動作です。実際にOpus 4.1と比較できます。これは約4.3でした。Opus 4.5は約18でした。そして今、わずかな改善で、Opus 4.6は約17です。
素晴らしいアップデートです。徹底的にテストするつもりです。Clawdbotに組み込むつもりです。どうなるかお知らせします。この動画を楽しんでいただけたら、ぜひいいねとチャンネル登録をお願いします。


コメント