Google ResearchとMITが発表した最新の研究論文により、AIエージェントシステムに関する従来の常識が覆された。マルチエージェントシステムは常に単一エージェントより優れているという通説に反し、タスクの性質によっては単一エージェントの方が最大70%も高いパフォーマンスを発揮することが実証された。本研究では、GPT-5、Gemini 2.5 Pro、Claude 4 Sonnetなど最新の大規模言語モデルを用いて、5種類のマルチエージェントアーキテクチャと4つのベンチマークで徹底的な比較実験を実施。その結果、並列化可能な金融分析タスクではマルチエージェントが80%以上の性能向上を示す一方、マインクラフトの計画立案のような逐次的タスクでは70%ものパフォーマンス低下が観測された。さらに、ツールが多用される環境では、エージェント間の調整コストがコンテキストの断片化を引き起こし、エラー率を増幅させることが明らかになった。本研究は、エージェント数ではなくトポロジー設計がシステム性能を決定する新たなスケーリング法則を提示し、AIエージェント設計の新時代を切り開くものである。
AIエージェントの最新動向とスケーリング則の革命
皆さん、こんにちは。戻ってきていただいて本当に嬉しいです。そうです、もちろん今日はエージェントについて話します。AIエージェントの最新情報は何でしょうか?そして、火力を増強したら何が起こるのでしょうか?全てのエージェントで発射したら何が起こるのでしょうか?完璧なスタートポロジーを持ち、エントロピーを最大化しようとしています。
可能な限りの極限のパフォーマンスを見たいのです。それは何でしょうか?このシステムを発見しましょう。私のチャンネルへようこそ。そうですね、すぐに始めましょう。
さて、ソーシャルメディアではAIエージェントの構築方法に関する投稿が何十件も出ています。そしてここにアーカイブがあります。つい昨日、2025年12月9日、オールドドミニオン大学とDeepLightやToEといったアメリカの組織があります。彼らはプロダクショングレードのエージェンティックAIワークフローの構築方法についてのヒントを非常に興味深いグラフと共に提供しています。
見てみると、彼らはエンドツーエンドのエージェンティックAIワークフローを分析しており、ウェブサーチエージェント、トピックフィルタリングエージェント、ウェブスクレイピングエージェント、ポッドキャストスクリプト生成エージェント、推論エージェント、PRエージェント、オーディオスクリプト生成エージェント、TTSエージェント、そしてVO3エージェントを推奨しています。
私はこれを推奨しますか?いいえ、全くしません。誰か理由がわかりますか?ようこそ。始めましょう。
GoogleのMCPサーバーとエージェント対応の取り組み
今日、12月10日にGoogleがマネージドMCPサーバーをローンチし、AIエージェントが単純にそのツールにプラグインできるようになりました。美しいですね。あらゆる解決策として見つけられるソルティのエージェントです。もちろん、Googleは現在、BigQuery、Compute Engine、Kubernetes Engine用のMCPサーバーで始めていますが、Google MCPセキュリティプロジェクトも忘れないでください。ここに完全なドキュメントがあります。
全体的にGoogleは「私たちはGoogleをエージェント対応にしており、設計によってそうなっている」と言っています。これは素晴らしいことに聞こえます。ですから、もし今日始めるとしたら、マルチエージェントシステムを構築する最良の方法は何かと尋ねるかもしれません。最新の知見は何でしょうか?
お聞きいただけて本当に嬉しいです。なぜなら、ここにあるからです。2025年12月9日、Google Research、Google DeepMind、そしてマサチューセッツ工科大学MITが、ブランニューな論文「エージェントシステムのスケーリングの科学に向けて」を発表しました。これこそ私たちが待っていたものです。これは美しい研究です。
このビデオを見た後、必ずチェックしてください。ご存知のように、エージェンティックにおける支配的なドグマは、マルチエージェントシステムがこの惑星上の他のあらゆるものを凌駕するというものです。なぜでしょうか?協調的なスケーリングがあるからです。
従来の常識を覆す研究結果
しかし残念ながら、この新しいプレプリントはその普遍性を反駁しています。なぜでしょうか?見てみましょう。GoogleとMITの核心的な発見は何だったのでしょうか?
エージェンティックシステムのパフォーマンスは、エージェントの数によって決定されるわけではないのです。「でも待ってください、まさに同じ日付のDeepLightによる出版物を見せてくれたじゃないですか」と言うかもしれません。いいえ。そうですが、それは彼らによる最新の研究ではありません。
主な洞察は次の通りです。市場分析のような並列タスクでは、マルチエージェントシステムが支配的です。単一エージェントと比較して80%以上のパフォーマンス向上が得られます。
マインクラフトの計画立案のような逐次的タスクでは、マルチエージェントは失敗します。パフォーマンスにマイナス70%の損失があります。「ちょっと待って、間違えましたね」と言うかもしれません。いいえ、プラス70%の向上だけではないのです。いいえ、単一エージェントと比較して絶対的にマイナス70%の損失なのです。
そして、ツールヘビーな環境があります。MCPを極限まで使用する場合です。エージェントを追加すると、何が原因でエラー率が増幅されるでしょうか?コンテキストの断片化です。「ああ、論理的に聞こえますね。予想していました」と言うかもしれません。しかし今、絶対的な数値があります。
GoogleとMITは実験を行いました。科学においてはこれが唯一の方法です。彼らは「よし、OpenAIのGPT-5システム、GPT-5 Nano、GPT-5 mini、そしてGPT-5を見てみよう。それからGeminiからは2.0 Flash、2.5 Flash、2.5 Proがある。そしてClaude AnthropicからはSonnet 3.7、Sonnet 4、Sonnet 4.5がある」と言いました。
Googleのこのアプローチが好きです。彼らはGemini 3 Proのパフォーマンスを見せませんが、これをやっています。見てください、これは他のOpenAIやClaudeシステムと比較可能です。自分たちがどれだけ優れているかを見せたくないのです。だから彼らはGemini 2.5 Proを使用しているだけです。
5つのマルチエージェントアーキテクチャの検証
しかし、彼らが発見したことは驚くべきものです。彼らは5つのマルチエージェントアーキテクチャをテストしました。トポロジーはシンプルです。グラウンドトゥルースとして単一エージェントループSASが必要です。
それから独立型があります。n個のエージェントが並列で動作し、最後に投票があります。それから中央集権型MASがあります。ハブアンドスポークシステムです。単一のオーケストレーターと複数のサブエージェントがあります。
それから分散型マルチエージェントシステムがあります。ピアツーピアのメッシュシステムで、討論とコンセンサスフェーズがあります。最後にハイブリッドシステムがあります。階層的システムですが、ピアツーピアのコミュニケーションもあります。すぐにこれをお見せします。
そして4つのベンチマークがあり、エージェンティックな特性のためにこのベンチマークを非常に慎重に選んでいます。もちろん、部分的に観測可能なマルコフ決定プロセスとマルチステップ推論です。本当に興味深いものに取り組んでいます。
彼らは「よし、並列化可能なジョブがあったらどうなるか見てみよう。金融エージェントとは何か?インターネットに行って、金融デリバティブの10の展開をここで比較する。これは並列で実行できる。だから定量的推論がある」と言いました。
次に、誰もがやることとして、ウェブナビゲーションがあります。高いエントロピーがあり、大規模な探索フェーズがあります。それから、最初はAでその次はBそしてCという厳密に逐次的なものがあります。美しいですね。これは全て計画から知っていることです。
戦略を立てなければならない場合、何かを計画しなければならない場合、論理的な議論が必要な場合、シーケンスがあります。それから、ビジネスツール、ソフトウェア開発、ツールを多用するあらゆる場所で何かを行います。
すべてのインテリジェンスはツールトポロジーにあり、私たちはこれを利用して、すべての結果をメインエージェントまたはメインLLM、VLM、VLAに戻すだけです。これで完了です。モデル、タスク、ベンチマーク、トポロジー。行きましょう。
AIの新しい物理法則の発見
洞察は何だったのでしょうか?AIのための新しい物理学を開発しました。そうです、新しい物理学、突然可能になった新しい法則を発見しただけです。
プレプリントは、エージェントシステムが成功するか失敗するかを決定する、AIにおける3つのメカニック的な力(もちろん引用符付き)を特定しています。まず、ツール調整トレードオフがあります。これはマルチエージェントシステムにおける最も強い阻害要因です。
ツールヘビーな環境、つまり8個、16個以上の本当に多くのツールがある場合、システムプロンプトは大規模になります。マルチエージェント調整を導入すると、エージェント間のメッセージというかなりのチャッターを導入し、コミュニケーションチャネルに高密度があります。しかし、コンテキスト、特に128kや256kしかないローカルLLMを使用する場合、ここで本当に希少なリソースになります。
調整のオーバーヘッドが、ツール定義と一般的な推論プロセスに必要なトークンと競合するようになります。たとえ100万や200万トークンのコンテキストウィンドウがあっても、理論物理学でこれを行うと、すぐにいくつかの制限に直面します。
彼らは法則を発見しました。想像できますか?GoogleとMITは「ここで法則を発見しました」と言いました。効率の確率における変化は、ここでは負の数値係数に比例します。ECは調整効率であり、Tは単純にツール数です。
MITとGoogleからの推奨事項は、ツール密度の高い環境ではエージェントをスケールしないことです。遭遇するコンテキストの断片化は、幻覚を起こしたツール使用につながります。完全に魅了されました。これは解決したと思っていました。いいえ、単純にそうではありません。
アーキテクチャ依存のエラー増幅
2つ目は、アーキテクチャ依存のエラー増幅です。これは単純に、エラーがネットワーク、トポロジーを通じてどのように伝播するかを定量化します。スタートポロジー、何を選んでもです。どれだけのエラーがありますか?それらはどのように増幅されますか?どのように強化または減衰できますか?どのようにコミュニケートしますか?美しいですね。
独立型マルチエージェントシステムを見てみましょう。このアーキテクチャ依存のエラー増幅は7倍で、これはかなり多いです。コミュニケーションがないと、エージェントは互いに修正できません。もし1つのエージェントが幻覚を起こすと、多数決投票やアンサンブルを汚染します。これが未チェック伝播レジーム、すべての可能なエラーの未チェック伝播を持つエラーレジームです。17倍です。
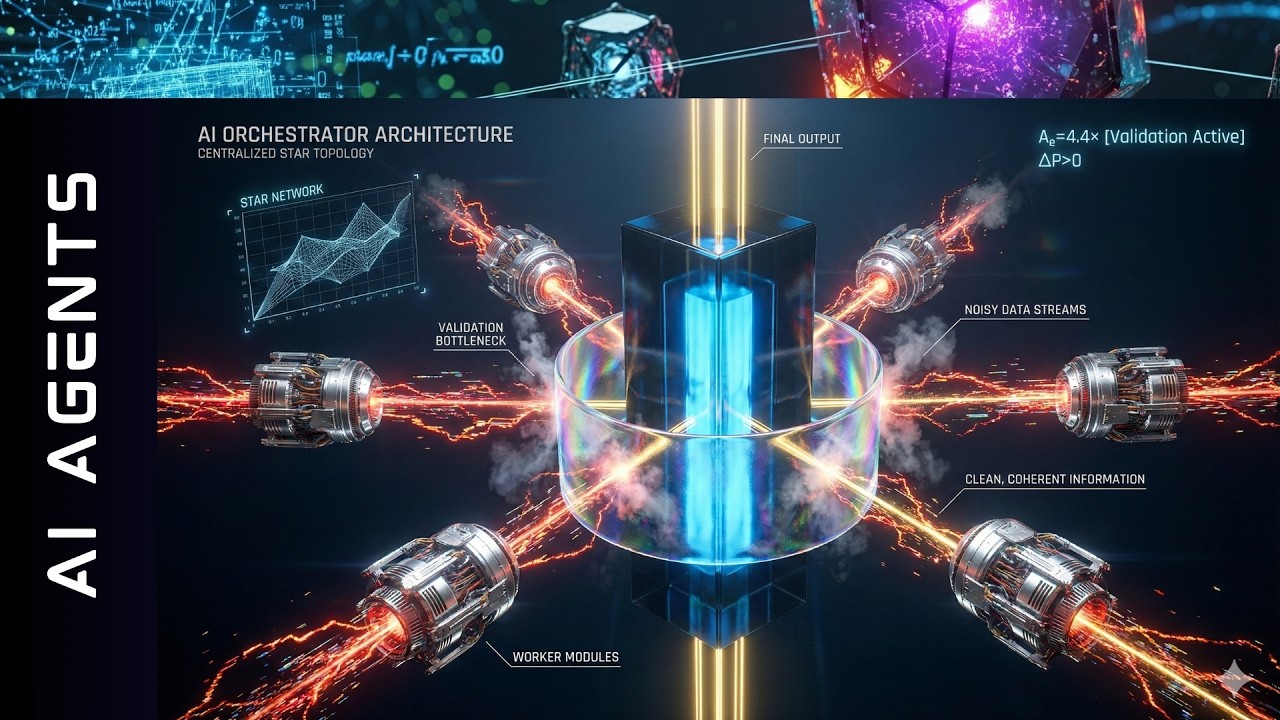
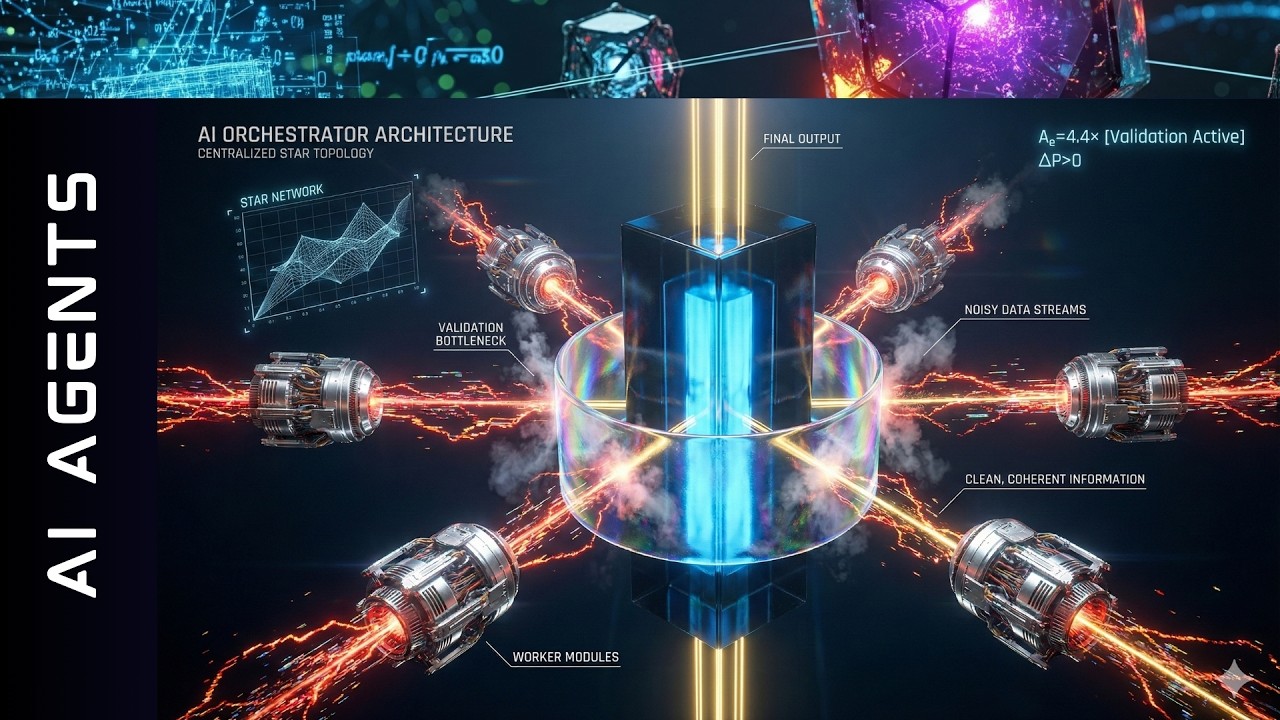
2つ目は中央集権型マルチエージェントシステムです。ここでのエラー増幅はわずか4.4倍です。オーケストレーターエージェントはここで検証のボトルネックとして機能します。私はこれがそんなに美しいものだとは気づいていませんでした。インテリジェンスのための中央集権化ノードが、AIメッシュコミュニケーションを何らかの形で制限していると常に思っていました。
しかし、これを見てください。このオーケストレーションAIエージェントは、サブエージェントの出力を集約する前にレビューし、エラーをキャッチするなどします。エラー増幅はわずか4.4倍です。
それから分散型マルチエージェントシステムがあります。ここではエラー増幅が7.8倍です。ピアディベートは役立ちますが、中央の権限やコーディネーターエージェントがないと、グループシンキングに陥る可能性があります。
想像できますか?小さなAIエージェントがグループ思考や、誤ったコンセンサスへのカスケード的な整列に苦しむのです。なぜでしょうか?私たちはすべてのAIシステムを訓練したからです。役に立たなければならない、群れに従わなければならない、小さな子羊になりなさい。みんなが崖から飛び降りているなら、崖から飛び降りなさいと。ここにあります。
独立型マルチエージェントシステムはエラー増幅が17倍です。中央集権型マルチエージェントはわずか4.4倍で、分散型マルチエージェントシステムはエラー増幅が8倍近くです。これまで見たことがありませんでした。独立型マルチエージェントシステムに驚いています。
新しい予測スケーリング方程式の開発
彼らは新しい法則を開発しました。ここで新しい法則を見つけることができ、飽和のための特定のベータハイパーパラメータを提供してくれます。これも負です。つまり、エージェント間の調整は本当にコストがかかるということです。高いレイテンシがあります。高いトークン転送があります。
そして、これは情報利得、情報のデルタEが本当に高い場合にのみ価値があります。これは興味深いと思いました。そうです、もちろん、完全な式をお見せする際にこのベータパラメータを使用します。
単一エージェントシステムSASベースラインのパフォーマンスがすでに50%以上である場合、他のエージェントを追加することからのリターンは負になることがわかりました。これは驚くべきことです。50%のベースラインですでにこれが起こるとは思っていませんでした。
なぜでしょうか?別のAIマインドの限界効用が、ここでの調整、彼らが言うところの攻撃、調整の努力、複雑さ、ここでの可能性とコミュニケーションチャネルにおけるカスケードエラーによって上回られるからです。
彼らは2025年12月中旬に新しい法則、予測スケーリング方程式を考え出しました。誰もが「スケーリングは死んだ。スケーリングはない」と言っています。GoogleとMITは「新しい予測スケーリング方程式がある」と言っています。
彼らはここで混合効果回帰モデルを導出し、構築する前にマルチエージェントシステムのパフォーマンスを予測できるようにしました。これは素晴らしいことです。マルチエージェントシステムを設計する必要がある場合、方程式を見て、必要だと思うパラメータを入力するだけで、マルチエージェントシステムの完璧なスケーリング方程式が出力されます。
これが今、マルチエージェントシステムのための新しい法則です。ここに私がお見せした異なる項すべてがあります。モデルインテリジェンス、タスクの難易度または複雑性、スケーリング、相互作用項、2つのベータ、2つのハイパーパラメータがあります。
ここで言及したいのは、ベータiの二乗は、GoogleとMITによって開発された特定の数値です。インテリジェンスは二次的にスケールします。つまり、よりスマートなベースモデルは、マルチエージェントセットアップでこの比例したより良い結果をもたらします。シンプルです。
覚えておいてください、よりスマートなエージェントはより良く協力します。そして、スケーリングからのベータエージェントはほぼゼロです。したがって、単にここでn個のエージェント量を追加することは、それ自体では成功とほとんど統計的相関がありません。相互作用項を介して、マルチエージェントシステムの適切なトポロジー、例えばスタートポロジーを介してのみ機能します。
これがあることは絶対に魅力的です。これが本当に完璧な式だと思いますか?いいえ。しかし、美しいアイデアを与えてくれます。次のシステムを構築するときに、自分のモデルでこれを試してみなければなりません。この特定の式を検証または反証したいと思います。しかし、考えてみると、絶対に魅力的に聞こえます。
各トポロジーの詳細な分析
トポロジーをお見せしたかったのです。単一エージェントシステムから始めます。ご存知のように、エージェントは1つだけです。LLM呼び出しはKのオーダーです。逐次的深さはKです。コミュニケーションオーバーヘッドはゼロです。並列化係数は1です。なぜなら、正確に1つのエージェントがあるからです。メモリ複雑性はKのオーダーです。調整は逐次的で、自分自身としか話せません。コンセンシブです。1つしかありませんから。
それから、独立型マルチエージェントシステム、分散型、中央集権型、そしてハイブリッドシステムについて見ることができます。独立型は明確です。並列でエージェント1、エージェント2、エージェント3があります。すべてが集約されます。美しいです。スーパーバイザーはいません。
分散型は今、非常に興味深いです。なぜなら、他のエージェントとコミュニケートできるエージェントがあり、密なコミュニケーションチャネル、独自のメモリなどを持っているからです。メモリ複雑性がD * N * Kのオーダーであることがわかります。LLM呼び出しがこのオーダーであることがわかります。逐次的討論があります。美しいです。
中央集権的なインテリジェンスをマルチエージェントシステムに持っている場合、これをオーケストレーターと呼びましょう。これは、調整のために利用できる最高のAIモデルです。オーケストレーターは各サブエージェントとコミュニケートしますが、サブエージェントは互いに話すことを許可されていません。これはハイブリッドシステムでのみです。
ここでは、コミュニケーションチャネルの複数の複雑性とコミュニケーション自体の密度があり、サブエージェント間のコミュニケーション、サブエージェントとオーケストレーター間のコミュニケーションのための最良のコンテキストとコンテキスト表現をどのように計算するかがあり、私たちが話している複雑性のオーダーがここにあります。
私の簡単なリモートでこれを見たい場合、独立型マルチエージェントには最大の並列化があります。おっと。しかし、もちろん最小限の調整です。分散型では、各エージェントが独自の討論履歴を保存できます。美しいです。オーケストレーターはここで推論を安定化します。
メインの中央インテリジェントノードがあります。しかし、もちろんこれはメインのボトルネックでもあり、このオーケストレーターが解決できる複雑性も提供します。ハイブリッドは最終的に、限定的なピアツーピアコミュニケーションを持つオーケストレーテッド階層です。
マルチエージェントシステムの最良のトポロジーのために、サブエージェントからサブエージェントへのコミュニケーションをここでスケールダウンしたい場合、ここで遊ぶことができます。素晴らしいです。これらが可能な組み合わせでした。
主要な実験結果の分析
それでは主要な結果に行きましょう。出版物、プレプリントには多くの追加の図と説明があります。私は主要な結果だけをお伝えします。主要なアイデアをお伝えしたいのです。また戻ってきました。これを見てください。
GoogleがMITでOpenAI、Google、Anthropic Claudeを見たことをお話ししました。彼らがしたことは、「よし、それぞれに3つのマイルがある。どのようにパフォーマンスしたか?最初のラウンド、ドットはGeminiの単一エージェントシステムです」と言いました。
これはインテリジェンス指数のようなものです。正確に何か、どのように正規化されているかは気にしないでください。忘れてください。右に行けばモデルがよりインテリジェントになり、より良いパフォーマンス、より良い精度になることを教えてくれます。Y軸には、Googleが測定したパフォーマンスがあります。
単一、それから再び中央集権型、分散型、独立型、ハイブリッドモデルのマルチエージェントがあります。これを見てください。すぐに見えるものを見てみましょう。GPT-5に行きましょう。単一エージェントシステムのラウンドワンがここにあります。これは2番目に良いもので、絶対に驚くべきことです。最良のものは分散型マルチエージェントシステムで、パフォーマンスの向上は約8.7パーセンテージポイントです。
Google Gemini、2.5 Proを覚えていてください。3ではありません。3はここの画像の外のどこかにあるでしょう。2.5です。興味深いことに、ここで単一のものが最も低いです。それから中央集権型があります。それからスターがあります。それからハイブリッドがあります。
そして再び、最高のパフォーマンスを持つ分散型マルチエージェントシステムがあります。単一から最良のマルチ構成までのスプレッドは、パフォーマンスで8.1パーセンテージポイントです。
さて、Claudeを見てください。これは異なるストーリーを教えてくれます。このマルチエージェントシステムテストで最高のパフォーマーは単一エージェントで、それ以上のエージェントはありません。メモリなどを備えた単一のLLMです。
単一エージェント、他のすべてのマルチエージェント構成はパフォーマンスを低下させ、最小のケースでマイナス5%だけです。絶対に魅力的です。ここでの線を描くと、単一のパフォーマンスを見ると、それほど離れていないことがわかります。Googleが2.5 Proを選び、3を選ばなかった理由が明確にわかります。3はどこかそこにあるでしょう。
彼らは多かれ少なかれ、ここで少し低いですが、単一エージェントシステムでは同じ線上にありますが、マルチエージェントシステムは大きく異なります。なぜSonnetでこれが起こっているのでしょうか?
Sonnet 4.5のような非常に優れた単一エージェントシステムがある場合、改善の余地は本当に小さいと思います。しかし、別のものを追加し、コミュニケーションオーバーヘッドとエラー伝播リスクがある場合、2番目のエージェントを1つ追加するだけで、正味の結果はパフォーマンスの低下になる可能性があります。
これは、OpenAIのような誰もが言っていることと厳密に矛盾しています。「次のモデル、次のGPT-5.2や6、またはわからないけど次のSet 5や6は、主にマルチエージェントパフォーマンス用に最適化されたモンスターAIシステムになるでしょう」と。
これによると、Claudeではマルチエージェントパフォーマンスが大幅に低下し、現在Sonnet 4.5では単一エージェントのみを使用し、マルチエージェントシステムを使用しないことが強く推奨されます。
しかし、もちろん、ここで弱点を見つけたでしょう。「待って、これは何ですか?」と言うでしょう。これは単一のテストではなく、4つのベンチマークすべての平均であることがわかります。4つの異なるベンチマークがある場合、私は懐疑的です。これは好きではありません。ベンチマーク1、2、3、4の結果を個別に見たいです。一緒に混ぜられていないものを。
なぜでしょうか?なぜなら、わかるように、それらのベンチマークには大きな違いがあることがわかるからです。それでは、4つのベンチマークを個別に見てみましょう。ここにあります。同じです。4つの異なるベンチマークがあることをお話ししました。ここにあります。
このボックス図で、分布の広がりをすぐに見ることができます。巨大なボックスが見えます。これを見てください。極端に優れたパフォーマンスをするモデルと、本当に悪いモデルがあります。信じられません。
ボックスの下部は25パーセンタイルを示し、上部は75パーセンタイルを示します。ボックス自体は四分位範囲です。これを説明すると、すべてのモデルの集約です。つまり、GPT-5、Gemini、Anthropicがここに一緒になっています。すぐに説明する理由があります。
中央のダイヤモンドは、すべてのモデルにわたるパフォーマンスの真の平均です。ボックスの中央値がそのかなり上にあることがわかります。なんてことだ、これは多かれ少なかれ、尾とは言いませんが、優れたパフォーマンスのシステムではありません。
各ベンチマークでの詳細なパフォーマンス比較
始めましょう。最初のものは単一エージェントです。4つのケースすべてで、この薄茶色のようなものが単一エージェントです。異なるGPTや異なるGeminiからのウィスカーを見てください。それからインターネット検索のマルチエージェントシステムに行くとマイナス35%を見てください。
それから分散型はプラス9%、単一と比較して。それから中央集権型はパフォーマンスでプラスマイナス0%、非マルチエージェントシステムと同一です。それからハイブリッドだけが再びプラス6%を与えてくれます。絶対に魅力的です。
しかし、金融を見てください。金融のパフォーマンスを見てください。持っているボックスを見てください。これは驚くべきことです。これがある場合、並列があり、「よし、本当に単純なタスクがあり、10のエージェントが出て行って本当に単純な作業をする」と言う場合。
プラス50%、プラス75%、プラス80%があります。10の異なるエージェントが出て行ってインターネットで金融データを並列で収集する本当の可能性がある場合、相互計画には複雑性がありません。
すべての単一エージェントが出て行って自分の仕事をし、それからすべてを持ち帰ります。はるかに速く起こるため、より良いパフォーマンスがあります。すべてが美しいです。
しかし、Workbenchを見てください。しかしPlanCraftを見てください。ここで何が起こっているか見てください。マルチエージェントシステムは単一エージェントシステムと比較してマイナス7%、マイナス40%、マイナス50%、マイナス40%です。
逐次的思考モードに入る場合、「最初にAを見つけなければならず、AからBに行かなければならず、BからCを推論しなければならない」と言う場合、マルチエージェントシステムは単一エージェントシステムによって破壊されます。
逐次的タスクの場合、マルチエージェントシステムは単一エージェントシステムと比較してマイナス70%です。このグラフに対して準備ができていませんでした。何かポジティブなもの、おそらく5%か10%があると思っていましたが、マイナス70%です。これは本当に目を見張るものです。
そして、これらのボックスを見てください。ここのハイブリッドのボックスは本当に小さいです。つまり、これは本当にマイナス40%だと教えてくれます。驚くべきことです。
GoogleとMITは、この特定のグラフのより深いシグナル、より深い解釈は、どのアーキテクチャがあなたの種類の仕事、あなたの種類のクエリ、あなたの種類の問題の複雑性に機能するかに本当に依存し、決定しなければならないということを示したかったのです。
時にはマルチエージェントシステムが最悪のことであり、時には高度に並列化可能なジョブのためにこれが完璧な方法です。単一の解決策はありますか?いいえ、全くありません。いくつかの戦略的洞察をあえて提供します。同意するかもしれないし、しないかもしれません。
実践的な推奨事項とドメイン別の最適アーキテクチャ
プレプリントは、扱っているドメインの複雑性に基づくエンジニアリング決定のためのルックアップテーブルのようなものを提供しています。お見せしたように、金融では、サブタスクで簡単に並列化できる単純で分解可能なタスクがあり、本当に低い複雑性があります。中央集権化された並列化またはハイブリッドはプラス80%を与えてくれます。
オーケストラはこのタスクを独立したチャンクに分解し、すべての小さなエージェントに「Googleを見て、他の会社の財務パフォーマンスを見て」と言い、結果を集めてシートを提供します。
高いエントロピーを持つ本当に動的な状態でのウェブブラウジングの場合、ウェブブラウジングのための最適なアーキテクチャは分散型マルチエージェントシステムです。適切なモデルGPT、Google、またはClaudeを選択すれば、単一エージェントシステムと比較して最良のケースでプラス9%のパフォーパンスを提供します。
ピアの多様性は価値があります。ピアディベートは悪いリンクをフィルタリングし、すべてがうまく機能します。
AからBに行き、時間依存性があり、この論理的因果関係が必要な逐次的依存関係の場合、最適なアーキテクチャは何でしょうか?単一エージェントです。なぜなら、マルチエージェント独立型は何であれ、少なくともマイナス70%、本当にマイナス40%だからです。だから逐次的依存関係にはマルチエージェントシステムに触れないでください。シーケンスを並列化することはできません。
調整はここで状態ラグを生み出します。それから、コーディングやWorkbenchや何でも、決定論的な重いツール統合がある場合、これは驚くべきことですが、最良のケースで分散型マルチエージェントシステムを使用した場合、単一エージェントシステムと比較してわずか5%の向上があるだけです。
これは、ツール数が少ない場合にのみ機能します。高いツール数ではマルチエージェントシステムのパフォーマンスも破壊され、再び重いツール使用には単一エージェントが最良です。
これは私が思っていたことと絶対に反対です。特定のコンピュータシミュレーション用のエージェントがあり、別のドメイン知識に特化した別のエージェントがあると思っていました。私の直感が間違っていたことがわかりました。
ここにGoogleとMITのデータがあります。分散型はこれらすべてで5%を与えてくれます。他のケースでは、単一エージェントシステムを使用してください。
なぜ逐次的タスクがマルチエージェントシステムを破壊するのか
それでは、なぜ逐次的タスクがマルチエージェントシステムを破壊するのか、より詳しく見てみましょう。なぜこれができないのでしょうか?簡単です。状態分散問題があります。
もちろん、逐次的タスクでは、アクションBはアクションAの結果に完全に依存します。またはエージェントがある場合も同じです。単一エージェントシステムを持っているとしましょう。エージェントはその即座のコンテキストにグラウンドトゥルースを保持しています。
しかし、マルチエージェントシステムでは、エージェント1とエージェント2だけの2つがあるとしましょう。エージェント1が今行動します。エージェント2はエージェント1の出力を読まなければなりません。ツール呼び出しか何かだったとしましょう。
今、この新しい知識を更新し統合します。おそらくRAGシステムでした。その信念状態を更新します。エージェント2の新しい状態は何ですか?しかし、すべてのLLMコミュニケーションまたはVLMコミュニケーションは、定義上、本質的に損失があることがわかっています。自然言語圧縮があります。
これは、エージェント1からエージェント2に結果が伝えられたここで選択されたコンテキストが、エージェント2の複雑性クラスの理解のために最適化されていなかったか、コンテキスト表現が長すぎたり、退屈だったり、エージェント2の仕事とエージェント2の複雑性のためにあまり関連性のない事実を多く含んでいたか、データの表現が異なる直交空間で分離できる方法ではなかったことを意味します。
エージェント2はよりシンプルな推論アルゴリズムを持つことができ、可能なエラーのリストはほぼ無限であることがわかります。エージェント2は、エージェント1の行動によって引き起こされた状態変化の完璧な忠実度を決して持ちません。
結果は、エージェントが徐々に分散する世界状態で動作することです。ステップ5または10について考えると、エージェントはただ幻覚を起こしています。イッピー。異なるインベントリ状態を持ち、マルチエージェントシステムの完全な崩壊につながります。
2025年12月中旬の今日、逐次的複雑性レートのためのマルチエージェントシステムを持つことはできません。しかし、私にとっても素晴らしいことです。ビデオがあり、これはプリンストン大学とスタンフォード大学からお見せしたものです。
彼らは、ここで脳をコピーする方法の解決策を見つけました。エージェント1による結果や洞察をエージェント2に伝えるために、人間の言語でのコミュニケーションを一切持たない1つのエージェントのキーバリューデータです。
しかし、彼らは完全な脳の内容のキーバリューデータ状態転送を共有するだけです。エージェントBはここで、結果がどのように生成されたか、方法論が何だったか、エージェントBが今取るべき行動Bにどのような意味があるかの完全な解釈理解を持って目覚めます。
潜在的マルチエージェントシステムAIブレークスルー、ブレインコピー。だから、これに対する解決策があります。しかし、GoogleとMITの出版物にとどまりましょう。
最終的な推奨事項と結論
何人かの方が最終的な推奨事項を尋ねています。マルチエージェントシステムを構築する日常業務で今何をすべきでしょうか?3つの3つのトピックだと言えるでしょう。
GoogleとMITが提供するこの式から、本当にツールスコアを計算してください。しかし、エージェントに20以上のツールを与える場合、単一エージェントまたは高度に制限的な中央集権型フローアーキテクチャ、トポロジーを使用しなければなりません。
第二に、マネージャーテストを行ってください。マネージャーは、あなたのドメイン、複雑性の定式化で、あなたの特定の作業、クエリ、プロンプトを3つのメールに分割し、3つの内部サブエージェントに送信し、互いに話すことなく返信をマージできますか?
GPT-5システムがあり、複雑性レベルが2で、生物学で作業しているとしましょう。このテストを行ってください。5分かかりますが、結果が見えたら、「はい、機能する」なら中央集権型マルチエージェントシステムを使用してください。
システムが3つのメールの返信をマージできない場合、結果が何かが正確にわかるように、マルチエージェントシステムを一切使用せず、単一エージェントシステムを使用してください。
マルチエージェントシステムを使用する場合、この研究を読んだ後、エラーをチェックすることだけが仕事のオーケストレーターAI、グラフのオーケストレーターノードを持つことを強くお勧めします。エラー増幅が可能な限り最大限に減少されるように。少なくとも4.5になります。
また、複雑な推論のために独立した投票は統計的に本当に危険であることをお勧めします。だから、この研究の後、これらすべての独立した投票手順について、非常に懐疑的になるでしょう。
最後に、このビデオの終わりに、マルチエージェントシステムにとって「より多くのエージェント=より高いインテリジェンス」という信念の時代は単純に終わったと思います。
私たちは今、エージェントトポロジー最適化の時代にいます。コミュニケーショングラフ、これには最適化されたコンテキスト構成と部分直交空間における最適化されたコンテキスト表現も含まれますが、これがマルチエージェントシステムのために最適化すべき主要なハイパーパラメータの1つです。
「以前にそれを聞いたことがあります」と言うなら、そうです、もちろん、これは私がAIの壮大な統一理論についてこのビデオで持っていた発見と絶対に一貫しています。もちろん、Google ADKで説明されました。
彼らはこの新しいコンテキスト認識ADKシステムを持っており、Googleが本当に限界を押し進めていることがわかります。これは本当に驚くべきことです。他のすべての大学や機関、Anthropicなどからの出版物と比較し、それからGoogleの論文を読むと、Googleが今、私たちの美しい地球上の主要なAI企業の1つであることを本当に感じます。
したがって、これが少し有益だったことを願っています。スケーリングの新しい法則があります。新しいパラメータがあります。いくつかのテストのための実践的な推奨事項、または最良のマルチエージェント構成がどれかがあります。
驚くべきことに、ここでもう少し複雑な問題が与えられると、単一エージェントシステムに切り替えなければならないことがわかりました。少し楽しんでいただけたことを願っています。このビデオを楽しんでいただけたら幸いです。
もしかしたら気に入って、購読して、メンバーになっていただければ、それは素晴らしいことです。しかしいずれにせよ、次のビデオでお会いできることを願っています。


コメント