Opus 4.5の登場により、AI開発は新たな段階に突入した。このモデルはClaude Codeと組み合わせることで、従来のLLMとは一線を画す性能を発揮している。重要なのは、AI開発における「問題空間」という第4の要素である。データ、アルゴリズム、計算能力に加え、AIが動作する環境そのものが知能の形成に影響を与える。自動運転車がその好例であり、AIの「心」が車体という「身体」を通じて道路という問題空間で進化する。同様に、LLMにとってのコマンドラインインターフェースは、コンピュータという問題空間で動作するための「デジタルな身体」である。Opus 4.5とClaude Codeは、この新しいパラダイムにおける最初の成功例であり、GPT-3.5のリリースに匹敵する転換点となっている。継続学習が実現する前でも、問題空間の飽和によって経済的価値は十分に創出される。ソフトウェア工学や科学的発見の領域において、1〜3年以内にコンピュータ上の全ての作業が解決される可能性が高い。

Opus 4.5がもたらす新時代
皆さん、どうも。ニールです。チャンネルへようこそ。皆さんも感じているかどうかわかりませんが、私は加速を感じ始めています。Opus 4.5は本当に驚異的なモデルです。これは明らかに、少なくともバイブコーディングの時代、あるいはAI全般における大きな変化の一歩だと思います。
個人的には、ChatGPTやGemini 3 Proと話すよりも、Opus 4.5と話す方が好きです。事前学習の観点から、直感や汎用性を持っているという点で、はるかに優れたモデルです。しかし、バイブコーディングの観点からも優れています。これはまるで、GPT-5.1 Codex MaxとGemini 3 Proが子供を作ったような感じです。考えるだけで驚異的ですよね。本当に素晴らしいモデルです。
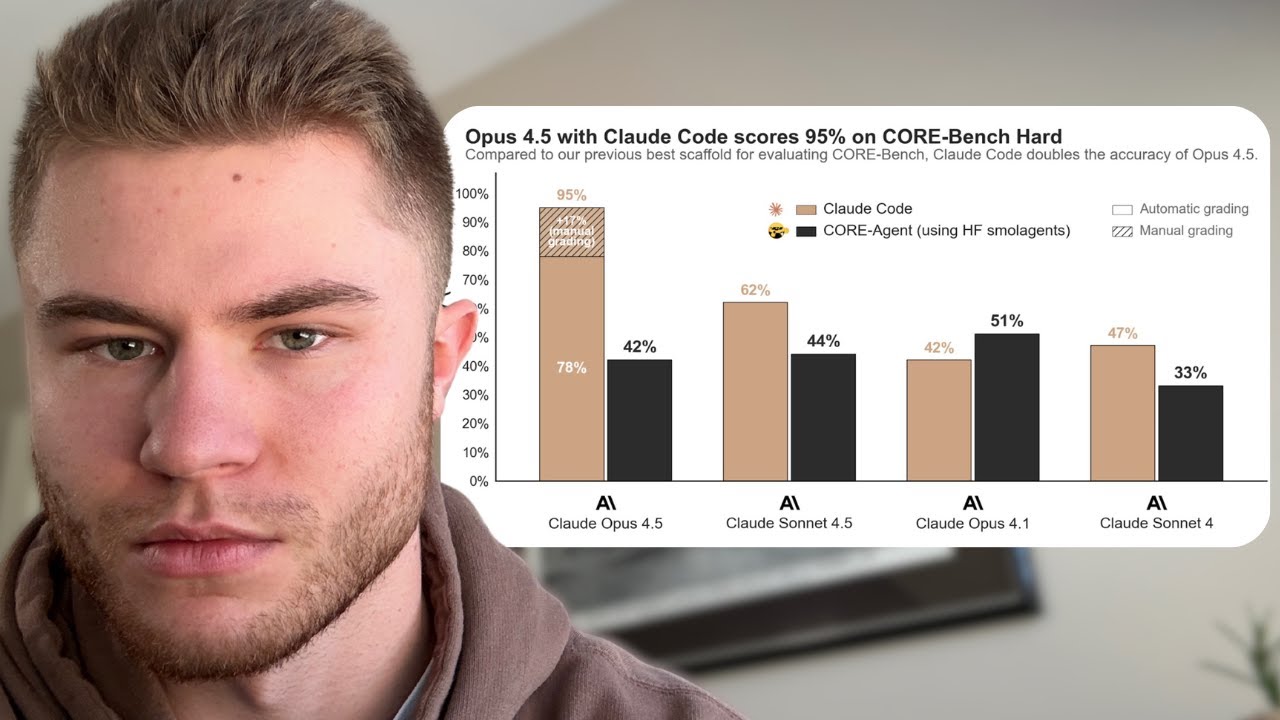
このグラフをお見せしたい理由は、Claude Codeを使ったOpus 4.5に注目していただきたいからです。それこそが皆さんに注目していただきたい点です。Claude Codeを使ったOpus 4.5です。特にClaude Codeに注目していただきたい理由は、このモデルで新たな飛躍が見られるからです。なぜなら、私たちは文字通り、これらのものが構築される方法において新しい時代にいるからです。
これはほとんど、ChatGPTでGPT-3.5が立ち上げられたときと似たようなものだと思います。それに近いものがあります。説明させてください。
自動運転から学ぶAIの進化
自動運転車を例に見てみましょう。私はテスラにバージョン14.2を持っています。最近、感謝祭のためにオハイオに行きましたが、8時間のドライブでした。オハイオへの道中、車はずっと運転してくれました。ハンドルに一度も触れませんでした。アクセルペダルにも触れませんでした。料金所で停止して支払いをさせてくれて、それから自分で進みました。充電ステーションを見つけて、充電器にバックで入りました。
私がしなければならなかったのは、ドアを開けて、プラグを差し込んで、車に戻って座ることだけでした。充電が終わったら、ただ「行く」をクリックすれば、残りの道のりを運転してくれます。行きも、オハイオにいる間も、帰りも、ハンドルには一切触れませんでした。それは何時間もの運転時間で、一度も触れる必要がありませんでした。正直なところ、長い間運転していません。
これがAIモデルによって解決されるエンドツーエンドのタスクなのです。さて、皆さんは「LLMはある面では非常に賢いけれど、他の面では本当に愚かだ。エッジケースに本当に弱い」と言います。それは、私たちが実際に知能を訓練する方法を学び始めたばかりだからです、明らかに。
AIを構築する第4の要素
しかし、伝統的に、皆さんはこう言います。「AIを構築する方法はこうだ。データが必要で、アルゴリズムが必要で、計算能力が必要だ」と。しかし実際には第4の要素があり、私はそれがより重要だと主張します。あるいはより重要というわけではありませんが、同じくらい重要です。それは、AIが動作する問題空間です。
これはリチャード・サットンの「経験の時代」に戻ります。そして今、Claude Codeを使ったOpus 4.5は、これが真実であることの証拠です。なぜなら、GPT-5 Codex、CLIのCodexではなく、AIモデルのGPT-5 Codexと同じように、そのモデルはGPT-3.5のようなものだからです。
これは、コマンドラインインターフェースという問題空間内で訓練された最初のバージョンのAIモデルです。車と同じように、テスラのAIモデルのロボットボディと同じように、コマンドラインインターフェースは、LLMにとっての身体、デジタルな身体なのです。
では、なぜこれが重要なのでしょうか。大きく一歩下がって考えてみましょう。あまりに哲学的にならないようにしますが、大きく一歩下がって、宇宙で生命がどのように進化するかを考えてみてください。人間を例に使いましょう。
私が私の身体であるわけではありません。私は私の心であり、私の心は私の身体とインターフェースして、宇宙の私たちの部分、つまり地球で動作します。重力プール、私たちが住んでいる環境があります。私たちの心、私たちの知能は、このインターフェース、つまり私たちの身体を使って、この問題空間内で動作します。
心は、身体と呼ばれるこの問題空間とインターフェースします。それは私たちの身体を制御します。身体という問題空間内で動作し、この身体を使って、私たちがいる宇宙と、熱力学的に効率的な方法でインターフェースします。地球と呼ばれる私たちの宇宙の場所、宇宙の問題空間内で。そうですよね。
これは自動運転車と同じです。自動運転車には、車の身体とインターフェースするAIの心があり、それが宇宙の一部である問題空間、つまり道路と運転とインターフェースします。
問題空間が知能を形成する
この点が特に重要な理由は、環境、つまり問題空間が実際に情報に選択圧をかけ、それが知能の形成方法を形作るからです。再び進化を見てみると、猿と人間を見ると、私たちは似たようなインターフェースを持っています。私たちの身体は極端に異なるわけではありません。しかし、心は一定の速度でしか進化していません。
生物学は単に固定された情報です。遺伝学を見ると、細胞やDNAを見ると、これらすべての異なるものは、文字通り固定された、固められた情報です。それが言葉として成立するかどうかは別として。とにかく、考え方としては、問題空間が実際の知能、情報、データに選択圧をかけているということです。
ですから、データに選択圧をかけるために計算能力とアルゴリズムが必要なだけではありません。問題空間も必要で、これら3つの制約が、知能がそのように出現し、可能な限り有能になることを可能にします。
私たちが持っていなかったもの、そして今ちょうど手に入れたものは、大規模言語モデルにとってのインターフェース、つまり身体、デジタルな身体です。それによって、実際にエージェント的になり、コンピュータの問題空間内で動作できるようになります。私たちは今まさにそれを見始めているところであり、だからこそClaude Codeで飛躍的な進歩が見られるのです。失礼な言葉を使ってしまいました。
Claude Codeを見ると、飛躍が見られます。そして思い出してください。ほんの数ヶ月前、私たちはこの新しいパラダイムに入りました。それはChatGPTでのGPT-3.5のリリースに匹敵するものです。私たちが今いるのは「経験の時代」です。これは巨大なことです。そして再び、データだけではなく、アルゴリズムだけではなく、計算能力だけではなく、問題空間も関係するということに戻ります。
そして問題は、LLMにとってのデジタルな身体とは何かということでした。LLMがインターフェースする適応的なデジタル身体、コンピュータの問題空間とインターフェースするための適応的なインターフェースとは何かということです。コマンドラインターミナルがかなり明白な答えだと思いますが、その問題空間内で強化学習を行ってこなかったのです。GPT-5 Codexがリリースされ、今Opus 4.5がリリースされるまでは。これは私たちがいる完全に新しい時代です。完全に新しい時代です。本当に信じられないことです。
継続学習は本当に必要か
これが最初の2つのポイントです。最初のポイントは、データ、アルゴリズム、計算能力だけではないということです。問題空間もあります。そして2番目のポイントは、その問題空間のためのインターフェースが必要だということです。人間の身体、車の身体、猫の身体、犬の身体、あるいはコンピュータの問題空間のためのLLMの身体のような、いわば身体です。
それが私たちが欠いていたもので、今私たちはそれを持っており、数ヶ月前から初めてそれを最適化しています。これは本当に巨大なことです、私が言ったように。さて、ここから移りましょう。なぜこれが重要なのでしょうか。
ドゥワレシュのポッドキャストで聞いたことがあるかもしれませんが、継続学習を解明するまで、これらのモデルから大規模な経済的価値を実際に見ることはできないということです。継続学習を解明するまで、それは実現しないと彼は言っています。私はこれは完全に間違っていると思います。
完全自動運転の例を見てみましょう。完全自動運転には継続学習がありません。それでも約98%が飽和状態です。2つの円の例を使いましょう。自動運転を1つの円とし、それから少し大きい人間の円があり、2%のリムがあって、そこでは人間がまだ自動運転車よりも優れています。
そして、それは実際には円ではないかもしれません。自動運転車とは異なる形状です。自動運転車がある面で優れていて、人間が他の面で優れているかもしれません。しかし、要点は理解していただけますよね。AIがより良くなるにつれて、その問題空間全体を飽和させ始めます。そして、私たちは自動運転車についてはほぼそこに到達しています。
私の自動運転車の例はすでに述べました。本当に良くなっています。来年には、本当に注意を払う必要がないでしょう。ただ眠ればいいのです。多くの人がすでにそうしています。サングラスをかけてテスラで眠り、目的地に到着します。私はお勧めしませんが、人々はそうしています。
そして、無監督自動運転はおそらく1〜2年後、長くても3年後には実現するでしょう。アンドレイ・カーパシーが言うように、9の列を下っていかなければなりません。90%、99%、99.9%、99.99%、99.9999%と進んでいきます。そして最終的には、「もう二度と運転するのはなぜだ。それは危険だ」となります。
ソフトウェア工学の飽和
そして今、ソフトウェア工学でも同様のことが起こり始めています。ほんの少し前に動画を作りました。2日前だったと思いますが、Claude 4.5 Opusがコーディングを解決したという内容でした。コメントで人々が「コーディングを解決したなら、なぜBunを買ったのか」と言っていました。私は「彼らは9の列を下っているんだ」と言いました。もちろん解決していません。
Claude 4.5がClaude Codeのハーネス内で90%だとしましょう。あるいは、ベンチマークの例を使いましょう。95%です。しかし、それが真実だとは思いません。彼らはおそらくベンチマークに少し過剰適合しています。90%のところにいるとしましょう。90%です。そして、まだ10%の境界半径があり、そこでは人間がClaude Codeよりも優れています。Bunのデータや彼らが持っているすべてのものを使っても。
彼らは、モデルがさらにコーディングに優れている特殊なパッケージを考え出すかもしれません。そこでの計画は正確にはわかりませんが、目標は99%に到達することです。そして99.9%、そして99.99%です。そして最終的には、もうミスをしなくなるポイントに忍び寄り始めます。
そして、私たちが訓練してきた言語モデルの知能によって、新しいアルゴリズム、より良い数学を発見し始めることができます。彼らは工学や科学的発見においてより優れたものになっています。そしてGPT-6については、サム・アルトマンが言っていることを私はある程度信じています。それが科学的発見に役立つだろうと。明白に思えます。もしそうでなかったら、実際かなり驚きます。
ですから、実際には継続学習は必要ないと思います。それでも手に入れるでしょうか。はい。ドゥワレシュのポッドキャストでイリヤ・サツケヴァーを見たなら、イリヤ・サツケヴァーは言いました。「ああ、彼は基本的に後ろのはしごを引き上げたんだ」と私は見ました。彼は「私たちは研究の時代に戻っています」と言いました。そして彼は「継続学習アルゴリズムが必要になるでしょう。私は継続学習アルゴリズムを持っていますが、それで多くのお金を稼ぎたいので教えることはできません」と基本的に言いました。
それが彼が言ったことです。そして、ポッドキャストの残りは曖昧でした。それが彼が述べた3つのポイントで、その後はすべてが曖昧でした。ですから、継続学習は起こるでしょう。本当に必要でしょうか。経済全体を飽和させたい場合、さらにそれ以上に、真のAGIを持ちたい場合、おそらく必要です。
しかし、ソフトウェア工学や特定のタイプの工学タスク、科学的発見を解決したい場合、科学的発見を解決すると言うとき、明らかにそれは人間の視点からであって一般的にではありませんが、その時点で本当に必要でしょうか。いいえ。
これらのものを継続学習なしでスケールアップすることで、それらを飽和させることができると思います。なぜなら、それは円全体を食べ始めるからです。そして、それが起こっていることだと思います。
新しいパラダイムの到来
ですから、問題空間は、ほとんどの人が考えていたよりも重要です。そして、エージェントが動作している宇宙や環境の空間内でインターフェースするために使用している適応的なハーネスなしには、大規模な経済的価値を実際に提供する一般的に知能のあるエージェントを構築することはできません。
そして私たちは今まさに、それが実際に起こるのを見始めているところです。私たちはエージェントのGPT-3.5時代にいます。これは信じられないことです。
ですから、チャンネルを見ていた方なら、私が予測を立てたことをご存知でしょう。1〜3年で、コンピュータの問題空間全体が解決されるだろうと。問題空間全体、つまりコーディングだけでなく、人間がコンピュータ上で行うすべてのこと、1〜3年が私の予測です。
そして、私たちがこのようなものを見始めているからだと思います。以前にも述べましたが、コンピュータが非常に適応的な方法で自分自身とインターフェースしている問題空間内で応用される強化学習です。そして非常に近い将来、私たちはヒューマノイドロボティクスでこれを見始めるでしょう。AIが世界とインターフェースしているロボットの身体とインターフェースしている問題空間内で、適応的な方法で強化学習を適用しているところを。
そして、多くの異なるものを飽和させるために継続学習は本当に必要ありません。大量のエネルギーと計算能力とデータが必要なだけで、そのデータは生成されています。私たちは今後5年以内に宇宙にコンピュータクラスターを配置しており、エネルギーはそこで簡単に捕捉されます。なぜなら、大規模なソーラーパネル製造があるからです。
ですから、このようなものが急速に発展することは非常に明白に思えます。そうでないと言う人は、ある意味頭を穴に突っ込んでいます。他に何と言えばいいかわかりません。
とはいえ、ここで動画を締めくくります。これが洞察に満ちたものであったり、価値があったりすることを願っています。これが、このようなものが実際にどのように機能するかについてのメンタルモデルを構築するのに役立ったことを願っています。次回お会いしましょう。


コメント