PrincetonとStanfordの研究チームが開発したLatent-MASは、AIエージェント間の通信を根本的に変革する画期的な技術である。従来のマルチエージェントシステムでは、エージェント間の情報伝達に人間の言語を介する必要があったが、この新手法はトランスフォーマーの隠れ層の状態を直接転送することで、人間言語への変換プロセスを完全に排除する。結果として推論速度は最大7倍に向上し、トークン使用量は83%削減される。この技術は、一方のエージェントの「脳」全体を他方のエージェントに直接コピーすることで、単なる計算結果だけでなく思考プロセス全体を伝達可能にする。数学的証明により、潜在表現が離散トークンよりも遥かに高い情報密度を持つことが示されており、完全に学習不要で実装できる点も革新的である。

Latent-MASの革命的な概念
こんにちは、コミュニティの皆さん。お帰りなさい。今日は本当に魅力的なトピックを扱います。エージェントの完全な脳をコピーして、一切の言葉も人間の言語も生成することなく別のエージェントに送信できる可能性があり、それが最大7倍速いのです。これを見ていきましょう。私のチャンネルDiscoveryへようこそ。今日は素晴らしい新しい論文がいくつかあります。
お見せしましょう。想像できますか?2つのエージェントがあって、通常はここにエージェント1の美しいトランスフォーマーアーキテクチャがあり、そして言葉が生成されてトークンに変換されます。トークンは語彙で単語として識別され、単語ごとの自己回帰的な生成が行われ、これが人間の言葉でエージェントBに変換されます。そしてエージェントBがこれを変換するわけですが、なぜこんなことをしているのかと思うかもしれません。なぜここで人間の言語なしに超高速な通信を持てないのでしょうか。エージェントは人間の言語を必要としません。人間である私たちが人間の出力を見たいだけなのです。しかし、なぜエージェント間の相互通信を人間の言語で行う必要があるのでしょうか。
これは無意味です。そのため、Princeton、Stanford、そしてイリノイ大学が「これを見てみよう」と決めたのです。
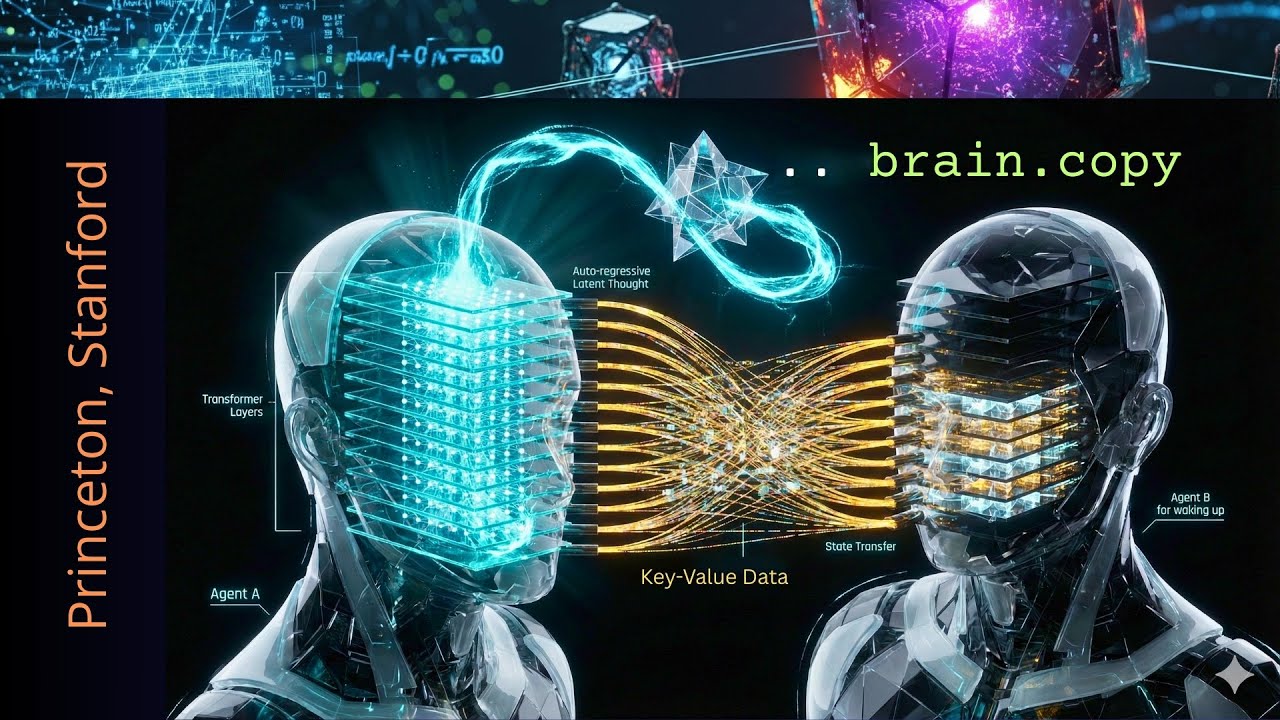
彼らはアイデアを持っていました。ここにあるすべての異なるトランスフォーマー層からすべてのキーバリューデータを取り出して、エージェントBに送信したらどうでしょうか。そしてもちろん、最終層、隠れ状態Hに注意を払わなければなりません。ここにエージェントAのすべての思考の結果である活性化があります。この転送をどうやって行えるでしょうか。見てみましょう、キーバリューデータです。
MLモデルは、会話で見たすべてのトークンのキーベクトルとバリューベクトルを保存していることをご存知でしょう。データはあるのです。送信するだけです。これが持つすべての複雑さです。しかし、もちろん思考の連鎖にとっては、同期がはるかに美しくなります。しかし、簡単なところから始めましょう。私たちが持っているのは、トランスフォーマーの内部同期による昔ながらの自己回帰ループです。
ご存知のように、トークンがトランスフォーマーを通過します。すべての層が第1層から第2層、第32層へと流れ、高次元ベクトルHがあり、この豊かな高次元の一貫性のある曖昧で確率的な信念の中に、「事実Aである可能性が60%、答えがBである可能性が40%」というものがあります。そして射影があり、密なベクトルが言語ヘッド行列と乗算されてロジットを得ます。覚えておいてください、語彙サイズに応じて5万から15万です。そしてすべてがソフトマックス関数とサンプリングで整数に収束します。
モデルは今、ソフトマックス関数をサンプリングし、確率分布から1つの勝者を選びます。これがトークンID 4598です。語彙を見ると、このトークンIDを「therefore」という単語で識別します。これがすべてです。完全な次トークン予測確率分布密度プロセスを「therefore」という単語に収束させるのです。素晴らしい。
これが通常のトランスフォーマーの思考方法です。しかし、知っていますか?トランスフォーマーの最終層の隠れ状態を使用することで、愚かな人間の言語に変換せず、人間の言語に制限される前のトランスフォーマー層の抽象的なAI思考の超表現力を保持できるのです。
私たちはそれを行わず、私たちの新しいARVプレプリント、特に定理3.1は、隠れ層がはるかに多くの情報を運ぶことができるという数学的証明を提供しています。そしてこの情報は、私たちの古いテキストトークン、私たちの人間の言葉では効率的に表現できないのです。内部トランスフォーマーの隠れ状態活性化レベルに留まり、これをマルチエージェントシステム間の通信レベルとする場合、なぜわざわざこれを人間の言語に変換するのでしょうか。ここに今週末のPrincetonの驚きがあります。潜在的協調とマルチエージェントシステムです。彼らが証明したことを信じられないでしょう。
定理3.1と表現力の証明
彼らは定理3.1を持っています。これは線形表現仮説の下での潜在思考の表現力についてです。これはここの仮定B1で詳細に説明されています。長さmのすべての潜在思考のシーケンスが、対応するテキストベースの推論を通じて無損失で表現できる場合、テキストのトークン単位の長さは少なくとも特定の複雑さである必要があります。そして、これに対する備考は、潜在思考生成が特定のオーダーでテキストベースの推論よりもはるかに効率的である可能性を示唆しています。あなたは「いや、信じない」と言うでしょうし、私もこれを見て「感覚的には分かるけど証明できる?」と言いました。そしてもちろん、ここに定理3.1の証明があります。ここにあります。
彼らは詳しく説明し、これが可能であることを数学的に証明しています。しかし、論理的圧縮の前に人間の言語に減らすことなく、トランスフォーマーの内部数学的潜在思考空間に留まります。そしてイノベーション第1号に到達します。これは美しいと思います。
定理B2または定理3.3の再記述は、AIシステムの潜在およびテキストベースの推論の両方において、先行エージェントから潜在的な作業記憶を受け取ったときのエージェントの出力は、あなたがエージェント2であればエージェント1が、先行エージェントの出力を直接入力したときに得られるものと等価であることを教えてくれます。
つまり、エージェント間で脳コピーができるのです。これは通信プロセスではありません。単に脳コピー、あるエージェントから別のエージェントへのキーバリューキャッシュのコピーと言うだけで、文章を構築する必要はありません。「こんにちは、私はエージェント1です。エージェント2に通信したいのですが、私の発見はABCでした」なんて忘れてください。
私たちはテンソル構造でエージェント間通信を行います。この同期プロセスの出力結果をここに送る代わりに、AはBに内部メモリ状態、いわばプロセスを送信します。素敵ではありませんか。「じゃあ埋め込みを見てみよう、ここで埋め込み空間1と埋め込み空間2の特定の次元を取ろう」と思うかもしれません。彼らはそれを行い、単純に埋め込みを見て、「複雑な数学的空間がある場合、この潜在思考生成マルチエージェントシステム構成によって生成された新しい埋め込みが、少なくとも昔ながらのテキスト的な人間言語マルチエージェントシステム通信パイプラインで持っていた空間をカバーしていることを確認できるか」と言いました。
Q13の40億パラメータモデル、80億パラメータモデル、140億の学習可能パラメータモデルでこれを見てください。オレンジの点がテキスト的で、青い点が新しい潜在システムです。
そして見てください、青い点はここではるかに広い空間を持っています。つまり、人間の言語では簡単に運べない表現力と複雑さがあるかもしれません。見てください、特に14BのQ&でオレンジはかなりクラスター化されていて、青い方、新しい方法論はより多くの空間を使用しています。これは興味深いです。
この複雑さを見なければなりません。多様体の超平面構造とでも言いましょうか。しかし、これについては後ほど詳しく。例を示しましょう。例は常に素晴らしいです。ここに研究があり、付録に完全版があります。段階的に読むことができます。質問があります。そして、最初は昔ながらのテキスト的な人間の言葉によるマルチエージェントシステム間の通信で進みます。プランナーエージェント、批評エージェント、改良エージェント、そして解決エージェントがあります。
そして、ここに特定の入力クエリが与えられます。プランナーエージェント、これが分析の出力で、これが批評エージェントへの入力です。批評エージェントの仕事はこれを批評することで、プランナーからの入力を持ち、これを予測し、批評エージェントの出力が改良エージェントへの入力になります。お分かりですね。そして、これらすべての後に間違った答えが得られる例を示しています。
つまり、テキスト的なマルチエージェントシステムは単純に失敗します。素晴らしい。そして今、「人間の言葉なしで潜在マルチエージェントシステム通信のプロンプトテンプレートを示します」と言います。ここにあります。特定の数値タスクについて、もちろんあなたの知識ドメインとタスクの複雑さに応じてこれを指定する必要があります。
すべてに対して1つのプロンプトだけを使うことはできません。非常に具体的でなければなりません。しかし、「すべてのエージェントに対するシステムプロンプト。あなたはAlibaba cloudによって作成されたQです。あなたは役立つアシスタントです」と言います。StanfordとPrincetonがGPTなどのアメリカのAIモデルではなく、ここでQanという中国のモデルを使っているのが好きです。
なぜか分かりますか?オープンソースです。それ以上は言いません。プランエージェントのプロンプトがあります。入力が与えられます。そして、これをここで見ることができます。批評エージェント、改良エージェント、審査エージェントのプロンプトです。そして知っていますか?これを行うと、最初にはるかに短くなることが分かります。なぜなら、あるエージェントから別のエージェントに脳をコピーするだけだからです。
説明を書き下す必要はありません。テンソルマッピングがあるだけで、潜在マルチエージェントシステムは、あるエージェントの一時的な脳を次のエージェントに、そして次のエージェントにコピーする複雑な思考の連鎖プロセスで成功します。お分かりでしょう。私のナノバナナプロと話していて、これは私が好きな画像の1つです。左側にエージェントA、右側にエージェントBがいて、エージェントAは特定のトピック、例えば数学に条件付けされています。
そしてエージェントBは理論物理学により条件付けされています。複雑さを少し高くするため、あるいは天体物理学です。エージェントの完全な脳の一時的なスライスをここでコピーして、エージェントBに入力として送信できます。エージェントBを起動し、その後エージェントBの専門性、つまり理論物理学や天体物理学を使用できます。しかし、エージェントAの完全なプロセス理解を持っています。結果だけではありません。結果は「このパラメータは1.4です」というだけかもしれません。
しかし、それが何を教えてくれるでしょうか?何もありません。結果を与えるだけです。しかし、本当に研究をするなら、プロセス、エージェントAがこの結果に至った方法を理解したいのです。使用されたアルゴリズムは何だったか?思考プロセスの複雑さはどうだったか?データは何だったか?コンピューターシミュレーションを使用したか?単にアナログだったか、それとも極めて高い精度でここで実際に計算したか?完全なメモリ、すべての作業ファイル、すべてが欲しいのです。そしてすべてがエージェントBの脳にコピーされるだけです。それからエージェントBはその専門性で続けます。
これは単なる入力でした。数学的および理論的な複雑さを転送できます。これははるかに深く、推論プロセスではるかに役立ちます。なぜなら、答えだけを転送するのではないからです。「パラメータAは12.8です」。気に入りました。まとめましょう。とても簡単です。それだけです。
潜在思考生成の仕組み
潜在思考生成です。Princeton、Stanford、イリノイがやらなければならなかったのは簡単なステップでした。これがこの論文の第2の大きなイノベーションだと思いますし、1つの論文に2つの主要なイノベーションがあるのは珍しいです。ここで素晴らしいのは、エージェント内通信システムでの1つのエージェント内のサイレント思考です。なぜなら、あらゆるテキスト的な記述よりもはるかに表現力豊かな高密度推論ベクトルを持つことができ、彼らは論文に数学的証明を持っているからです。
論文を読んで、著者に感謝のメッセージを送ってください。私はこの論文が大好きです。この潜在思考生成により、LLMは静かに推論できます。つまり、AI エージェント内の推論プロセスを人間の語彙を使用する制約から切り離します。しかし、モデルに毎ステップで特定の単語やトークンを選択させる代わりに、次トークン予測ですが、システムはモデルの生の脳活動、隠れ層からのすべての隠れ状態、すべての活性化をキャプチャし、それを自分の感覚にループバックし、入力層に戻して次の思考をシミュレートします。
まずトークンバイパスです。これが主な逸脱です。標準的なLLMではロジックに射影され、ここでトークンIDを選択するソフトマックス関数に渡されます。「therefore」という単語を持つ潜在マルチエージェントシステムは「忘れてください。これはやりません」と言います。確率を計算せず、離散トークンをサンプリングせず、外科的バイパスを実行するだけです。素晴らしい。
しかし、それから、これについては後で詳しく説明しますが、入出力アライメントがあります。そして、これが両方のエージェントの上のトップレベルでここに見たプリズムです。なぜなら、私たちが操作している数学的空間を見ると、それらの空間は一見、本当に一貫性があり互換性があるわけではないことが分かるからです。生の出力ベクトル、H、隠れた活性化は、その幾何学的形状において入力埋め込みとは統計的に異なります。
これを直接入力レベルゼロにフィードバックすると、分布外活性化をトリガーし、推論プロセスのパフォーマンスが低下し、すべてが崩壊します。そこで著者は「問題ない。特定の幾何学的空間Aと特定の幾何学的空間Bがある。数学で行うのは、出力ベクトルを有効な入力空間構成にマッピングする射影行列を作成することだ」と考えました。
それは単なる数学的操作です。それは簡単なことです。これを構築する方法を示します。そして彼らは「さて、今、整列されたベクトルがあって、それがここで次のベクトルである場合、この整列されたベクトルは、トランスフォーマーの第1層の入力における標準的なトークン埋め込みであるかのように正確に扱われる」と言いました。通常通り進めるだけです。特別なことは何も起こりませんでした。
モデルは今、再び順伝播を実行します。キーバリューキャッシュのため、モデルはこれに対する新しいステップのみを計算します。これにより新しい隠れ状態が生成され、すべてを続けるだけです。美しくないですか?単一エージェントで持っているのは、このサイクルが40回または80回、または予算がある定義された数の潜在ステップについて繰り返されるために生成される思考ストリームです。
これにより、エージェントAの単一の脳内の潜在思考のシーケンスになります。エージェントAの推論プロセスは、もはや自己回帰的なトークン予測プロセスを通信する人間の言葉に結合されていません。トークンを忘れてください。推論ループ自体でこの語彙構造を忘れてください。
出力では、はい、大丈夫です。しかし、この思考プロセスでは、なぜ次のトークンの予測で進む必要があるのでしょうか?複雑な数学的空間に留まり、そこで数学的操作を行うことができます。潜在思考HT+1、HT+2のシーケンスが得られます。Mは40に定義されています。美しいですね。トランスフォーマーのここで完全な層を通過するたびに、新しい潜在開始表現が得られます。見てください、これです。
これが潜在生成の終わりです。気に入りました。Stanfordは、Princetonはここに3つの主要な洞察があると教えてくれます。これを見せたいです。本当に美しいからです。このシステムの推論表現力です。エージェントのトランスフォーマーの単一の脳内のこれらの隠れた表現は、モデルの連続的な思考を自然にエンコードし、各潜在ステップが離散トークンよりもはるかに豊かな情報を高い情報密度で伝達できるようにします。第2に、通信の忠実性です。
潜在的な作業記憶は、各モデルの入力表現と潜在思考自体を保持し、今度は無損失のエージェント間情報転送を可能にします。脳のすべてのニューロンの神経活動を本当にコピーします。第3に、協調の複雑さ自体です。なぜなら、この潜在マルチエージェントシステム構成は、テキストマルチエージェントシステムよりも高い協調的表現力を達成しながら、大幅に低い推論複雑性計算を達成するからです。
知っていますか?4番目の事実があります。それは単なる追加の美しさで、完全に学習不要で、すべてのエージェントが純粋に内部の潜在表現を通じて同期し相互作用できるようにします。すでにそこにあります。脳を内部的に再配線するだけで、これがすべてです。すべてのコード、すべてのデータ、必要なすべてのPythonファイル、すべてのモデルがここにあります。
美しいGitHub、寛大な潜在マルチエージェントシステム、ここにPrinceton Universityによるものがあります。これを見てください。素晴らしいです。結果を示しましょう。効率性の観点から結果は驚くべきものですが、推論速度の向上は、毎回人間の言葉に変換してから、この人間の作業をフィードバックし、テンソルに変換し直す必要がないためです。お分かりですね。
推論では平均して4〜5倍速く、特定のテストでは7倍速いです。これは美しいです。システム全体のトークン使用量を見てください。トークンごとに支払うことをご存知でしょう。トークンを最大83%、84%削減できます。これが次世代のAIシステムの運用モードとして実装されれば、グローバル企業の支払い方法が変わると思います。
トークン使用量ごとの支払いから他のものに逸脱するかもしれません。なぜなら、これは同じシステムのパフォーマンス、おそらくより良いパフォーマンスで、システムが同じ出力に対して83%安くなることを意味するからです。想像できますか?なぜなら、エージェント内個人間エージェント通信から人間に変換し、人間の言語を使用するだけではないからです。
パフォーマンス結果と今後の課題
個人的に少し残念なのは、はい、もちろん常により良いですが、推論パフォーマンスにおいて大きな飛躍はありません。ここにさまざまなベンチマークのすべてがあります。緑色の円で単一モデルのパフォーマンスが見えます。これが最悪です。
オレンジ色で、すべてが言葉に変換される従来のテキスト的なマルチエージェントシステム通信があります。そして、ここの水色のものが新しい潜在マルチエージェントシステムで、他のすべてのシステムを上回っていますが、それほど大きくはありません。時には本当に接近していて、わずか1〜2パーセントポイントの違いで、時にはより大きな飛躍が見られます。明確な兆候は、これは始まりに過ぎないということです。
これは単なる最初の実装です。この方法論をさらに最適化する方法について、私には2つのアイデアがあります。「待って、待って。ここでビデオを止めることはできません。なぜなら、両方のエージェントの上にあるこの奇妙な小さな星、このプリズムについて説明していないからです」と誰かが言いました。つまり、ああ、これについて話しているのですね。はい、もちろんです。
お話ししたように、エージェントAがあり、トランスフォーマーのすべての層を通過し、隠れた活性化があります。これを入力層に再びフィードバックするには、ここで数学的最適化を見つけなければなりません。今これを行いましょう。古典的には、すでに述べたように、ソフトマックス関数は非可逆圧縮アルゴリズムで、トランスフォーマーの層内でここで計算されるような豊かな連続確率分布です。これは「解決策は60%リンゴ、39%バナナ、1%車かもしれない」と教えてくれますが、ソフトマックスの後、単一の整数IDに崩壊します。リンゴです。
バナナである可能性がまだ何パーセントかあるという情報を失い、文脈の複雑さを完全に失います。ベクトルは破壊され、辞書検索結果に置き換えられます。
複雑さをリンゴのような単一のトークン、おそらく単一の単語に圧縮します。これが自己回帰的LLMからの結果です。潜在マルチエージェントシステムの場合、完全な高次元の豊かなベクトルを保持しますが、出力ワイヤを入力スロットに戻すだけではできません。なぜなら、電圧がそこにないと言いましょう。
これを変更しなければなりません。これは単に、これらの両方の数学的空間の幾何学を適合させ、まっすぐにしなければならないことを意味します。どうやってこれを行うのでしょうか?このプリズムは何ですか?もちろん、線形射影アルゴリズムによる部分空間アライメントです。単なる数学だと言いました。詳しく見てみましょう。これがこのプリズムです。
ここにすべての異なるトランスフォーマー層からの出力があります。生の隠れ状態があります。美しいです。入ってきて、連続的な推論プロセスに出力を使用したい場合、このデータストリームの幾何学が、この情報をフィードバックしたい特定の層の完璧な幾何学になるように変換しなければなりません。トランスフォーマーまたはトランスフォーマーの最下層、入力層に。
単純に数学的操作を実行しなければなりません。この層が信号から期待している次元性に整列された入力が必要です。なぜなら、出力信号の複雑さは全く期待していないからです。出力空間、入力空間、入力空間ベクトルは正規化された、コンパクトな球状で、ニューラルネットの第1層をトリガーするように最適化されています。
これに注意しなければなりません。最も単純な数学的考えで表現できることは、行列W Aを見つけたいだけです。行列W outと行列W Aを掛けたものが層の複雑さの入力次元性と等しくなるようにします。必要なのは、この行列W Aだけです。
これを見ると、「簡単だ」と言うでしょう。出力ヘッドの擬似逆行列を計算し、入力埋め込みwnと掛けるだけです。もちろんこれです。これがwaを符号化する方法の式です。あなたが探しているこの変換行列により、出力信号が適切な幾何学的精度と形状になり、トランスの第1トランスフォーマー層の入力ループに挿入またはフィードバックできます。これです。計算できます。
しかし、システムの安定性についてです。興味深い側面があります。このプリズム、このWAは、人間の言葉の辞書検索を置き換えます。いいえ。そして古い方法では、このテキスト検索は、有効な頂点にスナップすることで、古いトランスフォーマーの思考プロセスを安定させました。確率分布を減らしました。
車かオレンジかバナナかもしれません。そして、それを純粋に単一の決定に安定させました。リンゴです。これがなく、40回、50回実行すると、システム全体の安定性に問題が生じる可能性があります。この新しい方法、この潜在マルチエージェントシステムでは、ベクトルを完璧な方法で整列させることで思考プロセスを安定させるこのWA行列を使用します。
システムは数学によって自己安定化されます。エージェントAの内部ループがある場合、これを連続的にループできます。エージェントは、次のエージェントに話す前に、40または80ステップで1秒の何分の一かで複雑な、本当に複雑な推論軌跡を構築できます。
そして今、話しているのではなく、脳活動をコピーして最終的な一時状態の脳活動を次のエージェントに送信しているだけです。天体物理学の次のエージェントは、入力として数学だけを必要とし、ドメイン固有の推論で議論を続けることができます。しかし、もちろん、このビデオの最後に、なぜすでに急いで使用していないかを説明しなければなりません。なぜなら、考えてみてください。
複数のリスクがあると思いますが、主なリスクはエラーの伝播です。すべてのエージェント、すべてのLLMは何らかの形で幻覚を見ます。テキストベースのシステムでは、エージェントAがミスを犯すと、エージェントBがテキストを批判的に読むことで入力でキャッチする可能性があります。エージェントAからエージェントBへの通信の間にスキャニングLLMを持つこともできます。なぜなら、テキストは古典的な古い形式、人間の言葉になっており、LLM分析者が「その文は意味をなさない、これはナンセンスだ」と教えてくれるからです。
エージェント間の相互通信で人間が読めるものが何もない場合、脳コピーと言って送信し、完了するという転送は、ここでセキュリティ機能を実装するのが少し挑戦的です。あるいは修正機能です。幻覚が全く起きていないことをどうやって確認しますか?なぜなら、エージェントAがミスを犯すか、どこかで幻覚を見て、この幻覚をエージェントBの脳への入力として送信すると、この幻覚は完全な複雑さで転送され、エージェントBの推論プロセスに大きな負の影響を与える可能性があるからです。
試してみて、実装するためのいくつかの安全機能を見つけようとしていない理由は、5つのエージェントがあり、内部で同期させるだけで、これらの5つのエージェントのすべてが幻覚を見る可能性があり、幻覚率が10%未満、5%未満、1%未満であっても、です。
それはすべての議論と論理的推論を通じてカスケードします。誰もが自分の脳、自分の脳と幻覚をコピーし、指数関数的に上昇します。AIエージェント間でこのAI脳移植機能のアイデアが大好きです。素晴らしいです。しかし、このチームによる次の出版物を待つかもしれません。
この方法論を確立した今、本当に検証された推論プロセスを確実に持つために、もう少し取り組む必要があります。このビデオの最後に、論文を読むことをお勧めします。本当に素晴らしいです。詳細な説明に非常に多くの数値テストデータがあります。とにかく、次世代のAIに本当にすでに実装できる両方のイノベーションが大好きです。
このビデオが気に入っていただけたかもしれません。新しい情報が見つかったかもしれません。とにかく、楽しんでいただけたことを願っています。チャンネルを購読していただけるかもしれません。メンバーになっていただけるかもしれません。しかし、とにかく、次のビデオでお会いできたら素晴らしいです。


コメント