本動画では、視覚推論における2つの極端なアプローチを比較分析している。一方はMonetのような内在的な数学的最適化エンジンであり、連続的な潜在空間における軌道最適化として視覚推論を扱う。他方は、ノースカロライナ大学が開発したAgent0-VLという外部ツール統合型のニューロシンボリックAIアプローチである。Agent0-VLは、視覚言語モデルをPython環境などの外部シンボリック推論エンジンと結合させることで、自己進化的な推論サイクルを実現する。この8Bパラメータモデルは、GPT-4 Omniを特定のベンチマークで上回る性能を示し、推論・検証・修復・進化という4段階のサイクルを通じて、人間の介入なしに継続的な自己改善を達成している。両アプローチは全く異なる設計思想を持ちながら、それぞれが次世代視覚AIの可能性を示している。

Agent0-VLの登場:ニューロシンボリックAIの新展開
こんにちは、コミュニティの皆さん。お帰りなさい。今日はニューロシンボリック人工知能の最新動向についてお話しします。まず、私のチャンネルへようこそ。ここでは最新のAI研究論文を見ていきます。さあ、始めましょう。
2025年11月24日の論文です。「Chain of Visual Thought:連続的な視覚トークンでビジョン言語モデルによりよく見てよりよく考えることを教える」というタイトルです。UC Berkeley、UCLA、そしてPanasonic AI Researchと来れば、はい、バークレーですから、この論文は読まなければなりません。では見ていきましょう。
興味深いのは、彼らが異なるアイデアを採用している点です。画像内の計数処理があり、画像の相対的な深度推定があり、そしてシーン理解があります。SAM 3でのセグメンテーションマスクがありますが、これは美しいですね。
しかし、外部ツールに依存することなく、計数や深度順序付け、シーン理解といった視覚中心のタスク全体で、きめ細かい関係をモデルに捉えさせることができます。皆さんは「シンボリックAIはどこにあるの?」と言うかもしれません。私は「うーん、なるほど」と思いました。
こちらを見てください。これはトレーニングパイプラインです。セグメンテーションマスク、深度マスク、エッジマスクを使い、そしてDINOがあります。つまり、この画像から可能な限り多くの情報を抽出しようとする4つの異なる要素が本当にあるのです。
そして損失関数、最適化など、皆さんがご存知のすべてがあります。著者たちはここで4つのビジョンモデルを使用して、各能力を学習する手法を監督しています。最初に申し上げたように、セグメンテーションAIがあります。これは画像内のオブジェクトの位置と形状を提供してくれます。
次に深度AIがあり、ピクセルレベルの深度情報を提供します。椅子は車の前に立っているのか、それとも後ろなのか。それからすべてのエッジ情報、つまり幾何学レベルの詳細があり、DINOは意味情報のためのパッチレベルの画像表現を提供してくれます。
各視覚トークングループはここで知覚エキスパートに対応しており、ビジョン言語モデルが行うことは、推論チェーン内でこれら4つのエンジンからの連続的な視覚トークンを予測することです。
そして誤差逆伝播があり、モデルの内部後期表現とエキスパートガイダンスとの整合があり、何が起こっているかを正確に理解できます。私はここのトレーニング損失関数を見るまでかなり興味を持っていました。見てください、彼らは本当に結合損失関数を持っており、ここではセグメンテーション視覚損失、深度視覚損失、エクストラ視覚損失、そしてDINO視覚損失関数として定義されています。
これが本当に進むべき道なのかどうか分かりません。ねえUC Berkeley、もう少し知的レベルで創造的になりましょうよ。これは基本的なことです。ちなみにDINOについて学びたい方は、ちょうど2年前にDINOに関するビデオがあります。これは古い技術です。
ここでご覧いただけるように、美しいChain of Visual Thoughtのホームページがあり、すべてを説明していて、コードもあり、Hugging Faceモデルもあり、データセットもあり、すべてがあります。そしてここにプロジェクトベースがありますが、私がビデオを作成してこの研究をお見せしたいと思うほど説得力があるわけではありません。
Gemini 3の技術詳細:段階的改善か革新か
他のアイデアはないかって?視覚のための本当に最新の高度なAIはないのかって?よくぞ聞いてくれました。なぜなら、ここに2025年11月27日のGemini 3、ビジョン言語、技術詳細レポートがあるからです。彼らがどのようにこれを行ったか、美しい要約があり、私は読み始めました。
もちろん、ここにビジョンエンコーダーがあり、そして美しい言語モデルDenseと、Mixture of Expertsデコーダ構造があります。しかし、ほとんど同じなんです。いや、同じではありません。あらゆる点でより優れています。それは継続的な改善です。しかし、まさにそれなのです。これは反復的イノベーションであり、ブレークスルーイノベーションではありません。
彼らが行ったすべてのことは、すべての段階を最適化したことであり、素晴らしい。パフォーマンスははるかに優れています。しかし理論的な観点から見て、何か驚くべき新しいアイデアがあったでしょうか。
20億、40億、80億のパフォーマンスデータを見て、GPT-4.5 nanoと比較すると、わかります。より良いです。知識ドメイン、推論ドメイン、コーディングとエージェントの整合性で比較すると、素晴らしいです。2.5よりも絶対的に優れています。
しかし、私が探しているのは別のものです。視覚AI推論の他の極端な位置に行きたいのです。なぜなら、前回のビデオでMonetについて話したとき、視覚推論がピクセル空間ではなく数学的構成で解決されるのを見たからです。
これは通常のAIではありません。これは本質的なニューラルモデルです。ニューラルネットワークには純粋な数学はありません。そして私は他の端を探していました。他の極端とは何か?
数日前にAgent Zeroについてビデオを作ったのを覚えていますか。ノースカロライナ大学とスタンフォード大学のもので、人間を超えたAIの自己進化について話していて、Python環境などのツールを大規模に使用していました。もちろんこれは視覚言語モデルではありませんでしたが、私はこのようなものだと言いました。
そして何だと思いますか、著者をチェックしたところ、彼らはちょうど3日前に論文を発表していたのです。そして今、Agent Zero視覚言語モデルがあり、統合された視覚言語推論のためのもので、絶対的にツール統合されています。つまりシンボリックAI統合があるのです。
素晴らしい。もうスタンフォード大学ではないことに注目してください。今はノースカロライナ大学チャペルヒルだけです。これらが私たちの美しい2025年11月26日です。これがあなたのための参照です。
Agent Zero視覚言語は今や現実のものとなりました。テキストエージェントに似ており、視覚言語は今や自己進化する視覚言語エージェントであり、ツール統合推論、ツール統合評価、そしてツール統合自己修復機能を通じて継続的な改善を達成します。
これだと思います。これが私が探していた論文です。なぜなら、今や美しい形でニューロシンボリックAIをお見せできるからです。
MonetとAgent Zero VL:2つの極端なアプローチ
画面の左側には、Monet AI、完全な内在的モデル、トランスフォーマーアーキテクチャの深部にあります。そして右側には、集中的なツール統合推論を持つAgent Zero視覚言語があります。完璧なニューロシンボリックAIモデルです。
どのように比較されるか見てみましょう。Agent Zeroは3日前にGitHubを更新しました。Agent Zero視覚言語は2、3日前に登場し、すでに611スターがあります。コードを見てください。説明を見てください。Apache 2ライセンスです。本当に素晴らしい。
なぜこれほど興味深いのでしょうか。シンボリック証明にアクセスできるからです。コードが正しく、テキストの複雑さからコードの複雑さへのマッピング、転送が正しく行われれば、Python エコシステムに送信するだけで、Pythonが正しい方法でコーディングするため、答えは99%正確です。
これにより、論理のためのニューラルインターフェースが作成されます。ニューロシンボリックAIとは何かというと、私の解釈では、微分可能な知覚またはニューラルネットワークと離散推論エンジンとのアーキテクチャ的結合だと思います。これがシンボリック部分です。
これだとすれば、最新の開発を見て、結果に飛びましょう。結果が素晴らしくなければ、このモデルを見る時間を無駄にしません。
著者たちは言います。「Agent Zero視覚言語を構築し、監督下でファインチューニングを行い、80億の訓練可能パラメータモデルは、すべてのオープンソースモデルの中で最高の総合パフォーマンスを達成します」と。
彼らは2つのベースモデルで行ったと言っています。Qwen 2.5視覚言語7Bと、Qwen 3視覚言語8Bベースモデルで、一方のケースでは12%の改善があり、もう一方では6%でした。
さらに、GPT-4 Omniを異なるベンチマークで上回ります。これをご存知ないかもしれませんが、8BモデルがここでGPT-4 Omniを上回るというのは、興味深いことです。見てみましょう。
可視化実験:Flux 2とNanobanana Proの比較
私のすべてのビデオを設計する中で、コードだけでなく、このコンテンツをどのように提示するかについても多くの実験をしています。異なる可視化技術と異なる可視化AIエンジンで実験しており、自分自身でチェックしたいエンジンが1つありました。それがここのFlux 2、Flux 2 Proバージョンです。
Flux Playgroundが見えます。そこに行けば、ログインすれば50枚の無料画像があります。私はこれをやらなければならないと思いました。なぜなら、前回のビデオではNanobanana Proを見たからです。Flux 2はどうでしょうか。
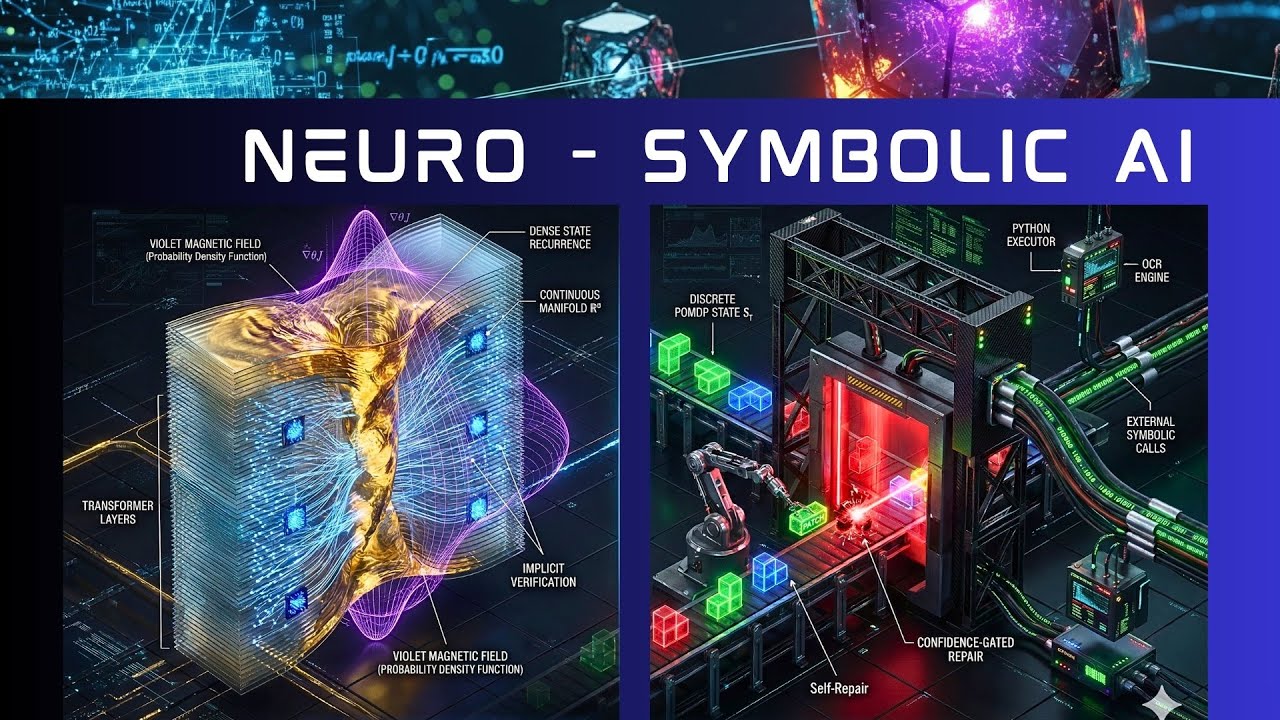
プロンプトを設計して両方のシステムに与え、ここにFlux 2の結果があります。プロンプトはシンプルでした。「ドック技術回路図グリッド上に座っている2つの異なるAI推論エンジンの高密度高忠実度3Dアイソメトリック断面図」。
そしてビジョントランスフォーマーフェイスを持つMoney構成をここで説明し、ここに磁気渦構造があります。融合炉の例を取れば、中央に黄金のプラズマストリームがあります。ポリシー最適化の最適化を理解しています。
もう一方では、Agent Zero視覚言語のコアアイデアがあり、すべての新しい情報を持ち込むコンベアベルトがあり、シンボリックAI、論理AIマシンがあり、多くの異なるサテライトがあります。
1つはPython環境で、1つはLeanForで、1つは任意の種類の形式ソルバーで、あるいはここでは引用符内のOCRリペアでさえあります。ここでは特定のスーパーコンピューティング可視化のための別のPythonがあるかもしれません。
これが今日、このビデオを録画した日に、Flux 2から返されたものです。これが可視化としてどのようなものかを感じていただけると思います。
しかしもちろん、これは1つの方法に過ぎません。実験していると言いましたね。Nanobanana Proに行くと、これはGoogle DeepMindの公式ページにあるGoogle Image Proの例です。
今ここで、左側のMonetのアイデアの内在的トランスフォーマーソリューションと、右側のシンプルな作業台コンベアベルトソリューション、外部シンボリック呼び出しを持つコンピュータ画像があります。右側がAgent Zero、左側がMonet。
左側のMonetでは、トランスフォーマーの数学的ハイパースペースの最適化に本当に深く入り込んでおり、それは本当に驚くべきことです。すべてのトランスフォーマー層をここに示そうとしました。
そしてそれらの層の中には、もちろん青いデータノードがあります。Monetで話した画像パッチを覚えていますか。そして、本当に複雑なハイパー平面上のパス最適化があるパスファインダーがあると言いました。
Monetはここで本当に複雑な超平面上のパス最適化であり、監督下ファインチューニングがあり、強化学習があると言いましたが、もちろんここでGPO最適化、ポリシー最適化を使用することはできませんでした。視覚潜在ポリシー最適化を使う必要がありました。
ここで融合炉のような磁気フラックスチューブを想像してくださいと言いました。オレンジ色で、これをここの溶岩の糸に圧縮したいのです。それが本当に最適解です。圧縮し、さらに圧縮して、可視化の中でここに解を持つ本当に狭い渦チューブを得るまで。
反対側を見てください。これは20世紀の産業のコンベアベルトのアイデアです。何があるでしょうか。Python環境のような外部サテライトがあり、知能が存在します。Python実行プログラムがあり、サテライトモジュールなどがあります。
マシンがあり、小さなチャンクが入ってきます。美しいのは、すべてが生成され、すぐに間違いがないかスキャンされることです。
エラーがある場合、マシンがエラーを検出した場合、分析が出力されます。Pythonが言います。「ちょっと、ここのこの小さなパッチに何があるか計算しました。間違っています。修正する必要があります。なぜならコードはABCDになるはずだからです」。
するとマシンはエラーと言い、自動的に自己修復モジュールを起動します。このパッチが最適化され、反対側から正しいパッチが出てきます。
すぐにわかります。これらは2つの異なる世界です。どのように実装するか。潜在空間における本当に複雑な数学的アイデアの美しさがあり、これはただの作業台です。
メカニズムの深層理解
メカニズム自体に、さらに深いレベルに行きましょう。左側にはMonet、潜在シミュレーターがあります。私は皆さんから多くの質問を受けました。このKullback-Leibleポリシー最適化、確率を持つ正規分布について、何が起こっているのかと。
非常に短い説明をしましょう。連続潜在多様体で、これは再び融合炉のような磁気トーラスであることを思い出してください。最適化を見つけるためにそれを圧縮し、さらに圧縮したいのです。この複雑さの中で最適なパスを見つけるために、これで行きましょう。そして右側を説明します。
まず、Monetのシステムメモリ内の画像は実際には256個のベクトルのクラウドであることを思い出してください。LLaMAにあるトークンの確率を最大化する代わりに、新しいVPOはクラウド内の成功した思考ベクトルへの近接性を最大化します。
これは、皆さんが何度も尋ねた正規分布N(μ、σ)に焦点を当てましょう。これは単にガウス確率密度関数であり、視覚言語モデルを見るときに離散世界と連続世界の間のギャップを橋渡しします。これは連続世界の近似であり、驚くほどうまく機能します。
見てみましょう。πはもちろん離散世界です。この正規分布ソリューションは確率生成器であり、単一の連続点がゼロ確率を持つことをご存知ですね。「cat」という用語の確率が連続モデルに行けばゼロになると言いました。
GPOの進歩が必要で、これがVPOです。私のビデオで説明しました。ベクトルをベクトルのクラウドとして扱います。思考は今やベクトル自体の正規分布、平均、そしてσによる特定の幅の確率生成です。
つまり、あなたの新しい思考ベクトルがラッキーベクトルと若干異なっていても。これは昨日問題を解決したプラズマベクトルです。今、確率分布内、正規化された分布、ガウス正規分布内のオレンジ色の磁気頂点内に収まります。
高い確率スコアを計算し、報酬を計算できます。この新しいポリシー最適化、VPOが私たちに、AIモデルに伝えることは、平均μを成功した軌道に近づけ、少しの分散σでスケーリングします。
これは今、単語トークンではなく、思考のベクトルの連続流動空間における距離です。
つまり、本当に、強化学習が単語でトークンではなく思考でベクトルで学習できるアルゴリズムです。これは離散空間での言語モデリングと連続空間での新しい制御理論の間のギャップを橋渡しします。
「制御理論、前回のビデオで何かあったな」と思うなら、そうです。もちろんです。サイバネティックAI、認知または認知テンソル場について話したとき、デュアルマニフォールドAIビデオのパート2でした。
AIのためのサイバネティックAI制御システムについてまさに話しているのです。同じ方向に進んでいることがわかります。ここの研究者たちも次のビジョンAIアイデアのためにこのアイデアで前進しました。
これは前回のビデオです。今、画面の右側にあるAgent Zero視覚言語について話しています。ここには離散シンボリック実行があります。これは簡単なので、説明するのがほとんど必要ありません。
底部から少しの情報があります。美しい。分析され、分析され、ここにPythonアルゴリズムがあり、特定のパラメータを分析し、動作しているかどうかを確認します。
この分析が戻ってきて、間違いがあると言えば、自動的に自己修復プロセスを保存し、ここで何かが壊れていれば、レーザー溶接があり、このピースが修正され、正しいコードまたは正しい式が挿入され、美しく、次のステップで情報の修正されたキューブがあります。
テキストが分析され、コードが分析され、すべてがチェックされ、青または緑またはゴーであれば、美しい、あります。
自己学習システムがあります。なぜなら、もちろんこれらのエラーと報酬は、ここに分析されてさらに報酬を与えられるために上がってくる小さな知識キューブの生成にフィードバックされるからです。
自己学習システム、自己修復システム、自己学習システムがあります。しかしもちろん、すべてはPython環境、C++環境、LeanFor環境、使用したい任意の形式ソルバー、または特定のコンピュータクラスタで実行したい任意のコンピュータシミュレーションの外部知能にかかっています。
LLMは意味機能を持つだけでよく、AGIである必要はまったくありません。これがニューロシンボリックAIの美しさです。
Agent Zero VLの自己進化推論サイクル
素晴らしい。Agent Zero視覚言語モデルは、著者たちが自己進化推論サイクルと呼ぶものを導入しており、推論、検証、修復、進化を可能にします。
推論はシンプルです。マルチターンツール統合視覚推論を実行します。知能は外部ツールにあります。検証は、ツールに基づく証拠を使用して推論ステップを評価します。修復は、検証フィードバックに基づいてエラーを選択的に修正します。
Python エコシステムから来るフィードバックです。そして進化は、典型的なGRPO強化学習を通じてここで継続的に改善します。離散空間は非常によく知られたGRPOであることがわかります。
このクローズドループシステムにより、Agent視覚言語はゼロ外部報酬の自己改善を達成できます。人間がこれを監視する必要はありません。
しかしもちろん、ツールは完璧でなければならず、テキスト情報からコードへの変換は、Python環境がこのコードをそのまま計算できるようにする必要があり、ここに弱点の1つがあります。
Python環境のためにテキスト複雑さをコード表現に変換するのが完璧でないAIシステムがあるかもしれません。
素晴らしい。すでにお話ししたように、このAgent Zero視覚言語は2つの役割を持っています。もちろん、単一の視覚言語モデルですが、システムパラメータを変更するだけで、突然2つの要素、つまり異なるタスクを実行する2つの同一の兄弟ができます。
マルチツール推論を実行し、すべての外部ツール、コードインタープリター、ビジョンAPI、グラウンディング計算と視覚知覚のために外部ツールとして利用可能なすべてのものを動的に呼び出すSolverがあります。
そして、お話ししたように、それがOKかどうかをチェックする必要があります。Verifierが必要であり、これはもちろん同一の視覚言語モデルで、異なるシステムプロンプトを持つだけです。
このVerifierは今、生成的批評とツールベースのフィードバックを通じて中間推論ステップを検証します。批評を受け取り、「すべて素晴らしかった、ただこの機能でちょっとした揺らぎがありました。このPythonコードを使えばより良いコード列になると思います」と言います。
元の言語モデルから戻ってきて、システムによって自己学習され自己最適化されるきめ細かい報酬信号と修復指示を生成します。
私のNanobanana Proで可視化を実験していることはご存知ですね。これを見てみましょう。すべてここで入力から始まります。画像が入ってきて、純粋なテキストが入ってきます。これが入る2つの入力データストリームです。
そしてここにSolverがあります。Solverは今、テキストと画像に基づいて視覚推論を試み、ここで視覚推論の最初のステップ、2番目のステップ、3番目のステップである小さな低複雑度のキューブを出力します。
これは視覚推論の複雑さの連鎖です。順次データブロックが出てきています。美しい。
しかしもちろん、本当の知能はビジョン言語モデルに少しあります。しかし、すべての複雑さについて、Pythonのエコシステム、サンドボックス、任意の形式サーバーに出て行きます。
問題をコードに変換します。コードがPythonに転送されます。Pythonが計算し、最適化し、ここでコードLLM知能を使用します。知能がここに存在し、解を持ち帰ります。
そしてこのマシンは、このコンベアベルトまたは磁気レールトラック、すみません、から出てくる小さな知識ブロックを溶接しているだけです。
そして、ここでこのビジョン言語モデルの同一コピーをVerifierゲートとして使用します。なぜなら、自己学習プロセスで間違いが起こらないことを確認したいからです。
間違いが起これば、このVerifierゲートはそれを検出し、識別し、行内または論証の3番目のボックスにエラーが含まれていると言います。それを見つけ、分析し、解決策を提供します。
ここで見るように、このVerifyゲートもPythonサンドボックス、知能に接続されています。これは自己修正マシンであり、ここでSolverと同じビジョン言語モデルを持たない方が良いアイデアかもしれません。
著者は同一の兄弟で行きました。素晴らしい。エラーを特定し、解決策を提供したので、何が起こるでしょうか。出力はここでSolverへの自己修復フィードバックループに戻り、別の小さな知識ボックスが溶接されます。
自己分析、自己修復システムがあり、もちろん、マシンが言えば報酬できます。「これは完璧な小さな知識ボックス、ここにある推論プロセスの小さな視覚知識ステップでした」、そして高い報酬があります。戻れば、報酬はゼロになります。
しかし、修復部分に戻らず前進した場合、完璧な小さなボックスだった場合、成功パスは、生成したものが素晴らしく、学習を続けたいものだと言うことです。
強化学習に入ります。これは私が覚えたい解決策だと言います。AIシステムを強化したいと言います。最適化エンジン、強化学習があります。タービンを構築しました、本当に素晴らしい、完了。
古典的な強化学習GPOがあります。Q関数を更新します。これはあなたが知っているすべてです。そしてもちろん、Solverケアユニットも最適化します。私たちのジェネレーターです。
修復ループと自己学習ループがあります。素晴らしかったもの、うまくいったものはここで正のフィードバックがあり、外縁に強化学習ループがあり、内側のループに修復ループがあります。
これが私がNanobanana Proでコマンドを使って構築しようとしたものです。ここに追加情報があります。お話ししたように、推論プロセスはもちろん古典的な離散空間です。
つまり、推論は部分観測可能マルコフ決定過程です。これは古典的なシステムです。これは私たちが知っている、毎回経験することです。
しかし、どれだけのプライドと知能をそこに入れるか、どれだけのツール、どれだけの知能ツールによって、LeanForを持つ別のボックス、純粋な形式ソルバーを持つ別のボックス、特定の医療データベース用の別のボックスなど、何でも持つことができます。
すべてがシンボリックAIにあり、それが決定されており、VLMのような自己回帰予測次トークンマシンではありません。
もう1つの本当に素晴らしい利点があります。著者が言います。「Agent Zをこう使えます。報酬を生成するので、これをモジュールとしてのみ使用できます」。これは他の視覚言語モデルのための単一プロセス報酬モデルに過ぎず、うまく機能します。完璧です。
AI推論の所在:2つのアプローチの比較
そして今、これを見て質問したいと思いました。AI推論はどこで起こっているのでしょうか。両方のエンジンを見てください。左側にはMonet、右側にはAgent Zero視覚言語があります。
Monetでは、暗黙的モデルにおける連続潜在再帰があります。つまり、メカニズムはシンプルです。Monetは基本的にトランスフォーマー自己回帰ループを変更します。
離散トークンを予測する代わりに、入力としてフィードバックされる連続隠れ状態を予測します。
Agent視覚言語は、明示的モデルを持つ離散ツール拡張状態空間です。メカニズムは次の通りです。VLモデルはここで推論を古典的なタプルによって定義される部分観測可能マルコフ決定過程としてモデル化し、アクション空間にはPython、OCR、LeanForなどへの離散ツール呼び出しが含まれます。
Monetでは、推論はデータ圧縮として扱われますが、モデルは高度に多次元の数学空間における高密度ベクトルパスに視覚操作のシーケンスを高度に知的な方法で数学的アルゴリズムで圧縮し、前回のビデオで説明した多様体仮説に依存しています。
視覚状態が連続低次元多様体上にあるという意味です。つまり、この空間の完全な探索複雑さを通過する必要がないのは幸運です。
Agent Zero Realityの推論は、プログラム合成と検証ステップとして扱われます。つまり、ニューラルネットワーク自体またはVMは物理エンジンではありません。結果を計算する外部の決定論的エンジンのコントローラーに過ぎません。
ここで私がLLMまたはVLMと呼んだものは、意味操作に過ぎず、主要な知能の本拠地ではないことがわかります。これはアウトソーシングされています。
Monetの技術的説明は、ビジョントランスフォーム自体の高次元ベクトル空間を利用することです。推論プロセスは今、この空間における軌道最適化問題として数学的にモデル化され、モデルは回転のためのアフィン変換やパッチにズームインするための注意マスキングのような視覚変換を模倣する遷移関数を学習します。ピクセルをレンダリングすることなく。ピクセル空間はありません。
反対側、Zero視覚言語は離散ツール拡張状態空間です。説明は、推論状態がここでテキストコンテキストと、RAGシステムのように戻ってくるすべての外部ツールの明示的な出力を包含します。
モデルは結果を全くシミュレートしません。推論実行を保持します。コードまたはAPI呼び出しなど何でも実行します。次に、Python環境のようなこれらの要素の決定論的出力をLLMまたはVLMに入るプロンプトのコンテキストウィンドウに連結し、生成を再開し、自己回帰予測次トークン演習で操作します。
2つの極端な完全に異なるモデルがあることを示したかっただけです。どちらのモデルを選んでも、信じられないほどの機会があります。
左側にはMonet、右側にはAgent視覚言語があります。完全に異なる獣です。しかし、エンジニアリングの観点から見てみましょう。ここでNano Proが見えます。これを見てください。左側のMonetが見えます。
ビジョントランスフォーマーメモリ空間があります。これは連続ベクトル空間で、画像パッチがあることを思い出してください。それらの画像パッチが今、監督下ファインチューニングと強化学習VPO最適化実行への入力です。
完全に新しい潜在空間勾配フロー時間動力学を構築し、すべてがここに入り、これは本当に高複雑度の本当に高度な数学的システムですが、ここで知能は本当にMonetのビデオで示したこの教師学生モデルによって与えられます。
右側のこのAgent視覚言語コアは、シンボリック空間でハードワイヤードです。シンボリック推論平面があります。ルールベースのシステムがここにあります。すべてがここで直接接続されています。OCRまたはPython環境があります。
エンジンとエンジンとエンジン、コマンド、リニアチェーン、美しい、すべてが行われ、これを分析しましょう。Pythonランタイムがあり、コードLLMとPython環境があれば、コードが正確に教えてくれます。これは間違っている、コードを修正、すべてはほぼコード化されていますが、論理ストリームを操舵するシンボリック推論と論理ゲートがあります。
コードが間違いがあったと教えてくれたり、OCR APIが読めない、または間違っていると教えてくれたり、エラーがあれば。これがスキャンユニットです。エラーを特定し、このエラーの解決策を見つけ、フィードバックして、システムを再度実行しようとします。
しかし、自己修復が成功し、青信号があれば、結果として出力されます。もちろん、ここでファイバー光チャネルを通ってフィードバックする強化学習プロセスがあり、このAIシステムを自己改善します。
もちろん、Pythonランタイムの複雑さ解決、7Bまたは8BモデルであればVLM自体の複雑さ解決を考えると、もちろん低複雑度のトピックに制限されます。
しかし、完全に異なる獣であり、これをお見せしたかっただけです。しかし今、選択できます。ここのようなニューロシンボリックで行きたいですか、それともMonetでお見せしたような純粋なビジョンエンジンに基づくAIの次世代に本当に深く潜りたいですか。
しかし、これは完全に異なるアーキテクチャになります。
実例:Agent Zero VLの動作
例を見てみましょう。それは素晴らしいアイデアです。ここに質問があります。画像の中央下部付近のポールの標識で示されている通りは何ですか。
建物のある通りの画像があります。小さな標識があります。ほとんど見えません。5つの選択肢、4つの選択肢があります。ミシガンなど。正しい答えを選択してくださいと言います。
何が起こりますか。モデルが今考えています。タスクは画像の下部中央付近にある標識に表示されている通りの名前を特定することです。はい、はい、はい。
今、タスクを特定すると言います。何をすべきか分かります。視覚データのクロッピングをする必要があります。
ツール、特定のツールを呼び出します。どこかにこれがあります。美しい、サブルーチンを呼び出し、画像をクロップしてズームしてくださいと言います。クロップ座標、ズーム係数は2など、元の画像で通りの名前を読めなかったのでテキストを読んでください。持ち帰ってください。
そして戻ってきて、LLMが教えてくれます。ここにRAGシステムがあれば、これはMichigan Avenueです。美しい。完了。簡単です。
彼らはSolverのシステムプロンプトもここで提供してくれます。これらは2つの兄弟だと言いました。同一のマシンです。これがSolverのシステムプロンプトです。そしてこれがVerifierのシステムプロンプトです。本当に簡単なシンプルな原則、シンプルなチェック。
これらのシステムのパフォーマンスを見てみましょう。最後の2行が見えます。Agent Zero 7Bモデルと8Bモデルがあります。
これは重要なので注意してください。53から65%への飛躍は1Bモデルの違いだけではありません。7BモデルはQwen 2.5に基づいており、80億Agent Zero視覚言語はQwen 3モデルに基づいているからです。
注意してください。これは2.5改良モデルで、これはQwen 3改良モデルです。元の環境にQwen 2.5とQwen 3があります。
これが本当に驚くべきものだったか、ここでこれすべてに価値があったかを比較できます。ツール、ツール用に生成されるコードに大きく依存していることがわかります。
視覚言語モデルが特定のツールセットを呼び出すとき、ツール実行のシーケンス、コードLLMについてのすべて、外部複雑性の相互作用についてのすべて。
このニューロシンボリックに行きたいと決定できますが、4つまたは5つのツールを使用する場合、非常に多くの未知のパフォーマンスコンポーネントがあり、VLMが適切なタイミングで適切なツールを適切な量のエネルギーで適切な複雑さの削減で使用することを決定することを確信できないことを覚えておいてください。
素晴らしい。これが結果です。
しかし、この感覚をお伝えしたいのです。これは何ですか。このエージェントはトークンを介して画像を見るだけではありません。コードを介してのみ動作します。
エージェントが離散テキストブロックを出力する場合、ツールを使用、クロップツールを使用、座標を与える、これらが座標です。これは単なるシンボリックコマンドです。
これは視覚的なものではありません。これはシステムが保持するコマンドです。クロップツール使用を実行し、結果をコンテキストにフィードバックします。
これを学習したのは、Agent最近言語8bモデルがトレーニングを受け、このトレーニング用に監督下ファインチューニングデータセットを生成したからです。この7Bまたは8Bモデルは、建物の前のぼやけた街路標識のようなあいまいなテキストがあり、どの通りか教えてくださいのような読み取りリクエストがある場合、クロップツールを使用しなければならない何千もの例を見ました。
これは監督下ファインチューニング実行で学習したパターンであり、視覚言語エージェントがコードを作成するのは、監督下ファインチューニングトレーニングデータに、視覚的なあいまいさをPython構文で話し始める文法的プロンプトとして扱うことがあったからです。
トランスフォーマーの大規模パターンマッチングエンジンを使用してギャップを橋渡しします。
「監督下ファインチューニングトレーニングデータはどのように生成されたのですか。誰がこれをやったのですか」と言うなら、もちろん、巨大な教師視覚言語モデル、AIシステムがあり、それを推論トレースに分解しました。
そして、学生モデルとして小さな7Bまたは8B Agent視覚言語モデルが教師モデルから学習しようとしました。
最終的な考察:MonetとAgent Zero VLの本質
最後の思考、個人的なコメントです。
Monetとこの美しい内在的で高度に複雑な数学的最適化エンジンを、クレイジーな数学空間におけるパスのための内部物理シミュレーターとして見ています。
どんなデータがありますか。連続流動ベクトルです。実行するプロセスは何ですか。シミュレーションです。アナロジーは何ですか。テニスプレーヤーを想像しました。テニスプレーヤーがボールの軌道を視覚化しています。
計算機のように、Python環境やC++のような外部ツールのように数学的計算を行いません。テニスプレーヤーは運動皮質で物理をシミュレートすることを脳で想像するだけです。
しかし、この運動皮質はMonetの潜在空間に他なりません。数学エンジンは新しいポリシー最適化であり、テニスボールの連続曲線または仮想思考プロセスを最適化しています。
このアナロジーがアイデアを与えることを願っています。計算はありません。これはここで数学を行いません。運動皮質、潜在空間で物理をシミュレートします。
この空間を構築する美しさがあると言いました。
一方、今日の論文、Agent Zero視覚言語は外部論理コントローラーです。
データタイプは単に離散シンボリックトークン、テキスト、JSON、何でも好きなものです。プロセスはコード実行です。アナロジーは単に物理学者が今、座って計算、テーブル、計算機、ボールの軌道のすべての計算を行うことです。
風を測定します。重力は地球上では定数であるはずです。ここに式を書きます。Pythonが計算し、この問題を解きます。
そして、エンジンがあれば、最適化、整合はここでGO、離散ステップのシーケンスを最適化します。完全に異なるマシン、完全に異なる獣であることがわかります。
両方とも視覚言語モデルです。両方とも視覚思考連鎖を試みますが、技術レベルでこれを実装する方法は完全に異なり、Monetは単に常軌を逸していると思います。そして私はそれが大好きです。
今日の最新の簡略化、これがビデオの終わりです。
Monetはより良い脳を構築しようとしていると思います。物理を暗黙的に理解し、画像を見て、直感的に理解するより良い脳です。トレーニングデータセットを与えてください。
テニスプレーヤーなら、何千時間もテニスをプレーしたことがあります。ボールの軌道を正確に知っています。計算する必要はありません。
しかし、Agent Zero視覚言語は、各ステップを明示的に計算するためにツールを使用するより良いユーザーを構築しようとしており、したがって自己回帰部分ではなく、本当に計算された結果の側にいて、より弱い知的脳を補償しようとしています。
この私の声明に同意していただけることを願います。何らかの形で不快に感じる場合は。これは単なる別のフレーミングであり、視覚システムの能力、強み、力は何かを理解しようとしています。
視覚システムの非常に多くのバリアントを構築でき、まったく新しいアイデアがあることを願っています。新しい組み合わせがあると思う、または次の視覚言語モデルを構築する方法についてまったく新しいアイデアがある場合は、ビデオにコメントしてみませんか。
楽しんでいただけたことを願っています。少し楽しんでいただけたことを願っています。気に入ったら、購読してみませんか、私のチャンネルのメンバーになり、次回お会いできることを願っています。

コメント