この動画は、次世代インターネットである「エージェントウェブ」の概念と実装について詳細に解説している。従来の人間主導のアプリベースシステムから、自律的なAIエージェントが協調して複雑なタスクを実行する新しいパラダイムへの移行を論じており、その技術的可能性と現実的な課題の両面を示している。Shanghai大学、Stanford大学、SAP Labsの最新研究を基に、エージェント間通信プロトコル、経済モデルの変革、セキュリティリスクなど多角的に分析している。
新たなエージェントウェブの誕生
みなさん、こんにちは。今日もコミュニティの皆さんが戻ってきてくれて本当に嬉しいで。今日は未来を見てみよかな。エージェントウェブの次のステップを見ていこう。
これは完全に新しい技術パラダイムになるんや。なんでかって言うと、現在の最先端技術は、次世代AIとの間に根本的なアーキテクチャのミスマッチがあるからや。
なんでそうなるかって?現在はLLMと単一エージェントで作業してるからや。つまり、複雑な多段階推論のための創発的能力を持つLLMやのに、それらは人間主導のステートレスな要求応答モデルに基づくインターネットアーキテクチャの中で動いてるんや。これは人間がインターネットを使ってる限りは大丈夫やった。
でも今度は、複数のエージェントが反応的な応答役から積極的な目標指向の問題解決者に移行できるような、持続的でステートフルで協調的な新しい計算パラダイムをどう設計するかっちゅう話や。
エージェント協調システムの仕組み
この未来がどんなもんか見てみよう。エージェントがあって、ユーザーが要求を出すと、エージェントが「ユーザーが以下のことをやってくれって言うてる」って言うんや。そしたらエージェントが「よっしゃ、計画立てるで」って言って、ここで推論モデルの計画を立てる。それから検索、インターネット検索をして、もし行き詰まったら「特別なエージェントを募集せなあかん」「特別なエージェントを作らなあかん」「Microsoft、OpenAI、Googleみたいなグローバル企業から専門エージェントを買わなあかん」って言うんや。
計画が続いて、アクション段階に入る。ここでツールとのやり取り、エージェント同士の協力、新しいデータストリーム、SQLとか、インターネット検索とか、最適解を見つけるためのエージェント間討論ラウンドとかがある。最終的にエージェントが解決策を持って戻ってきて、それを人間ユーザーに提示するんや。見てみい、人間の俺は質問しただけで、今答えをもらえて、何も触る必要がないんや。
今日のビデオでは、今日発表された全く新しい3つの論文と、俺が今日スキャンしようとした200以上の論文を組み込むで。その3つは本当に興味深くて、一緒になってるんや。
最初の論文は新しいウェブのビジョンを表してる。77ページの詳細な説明や。次のインターネット世代って何やねん?それから、このビジョンの実装、この新しいアイデアの設計図を実際に見る。皆さんの90%は馴染みがあるはずや。そして検証段階がある。マルチエージェントシステムの性能を評価せなあかん。
この3つの研究を見ていこう。最初の研究は上海大学、香港大学、リバプール大学、カリフォルニア大学バークレー校、上海イノベーション研究所、カリフォルニア大学デービス校、バージニア工科大学、ユニバーシティ・カレッジ・ロンドンや。2番目はスタンフォード大学とジョージ・メイソン大学。3番目はSAP Labsからや。
新しいウェブのビジョン
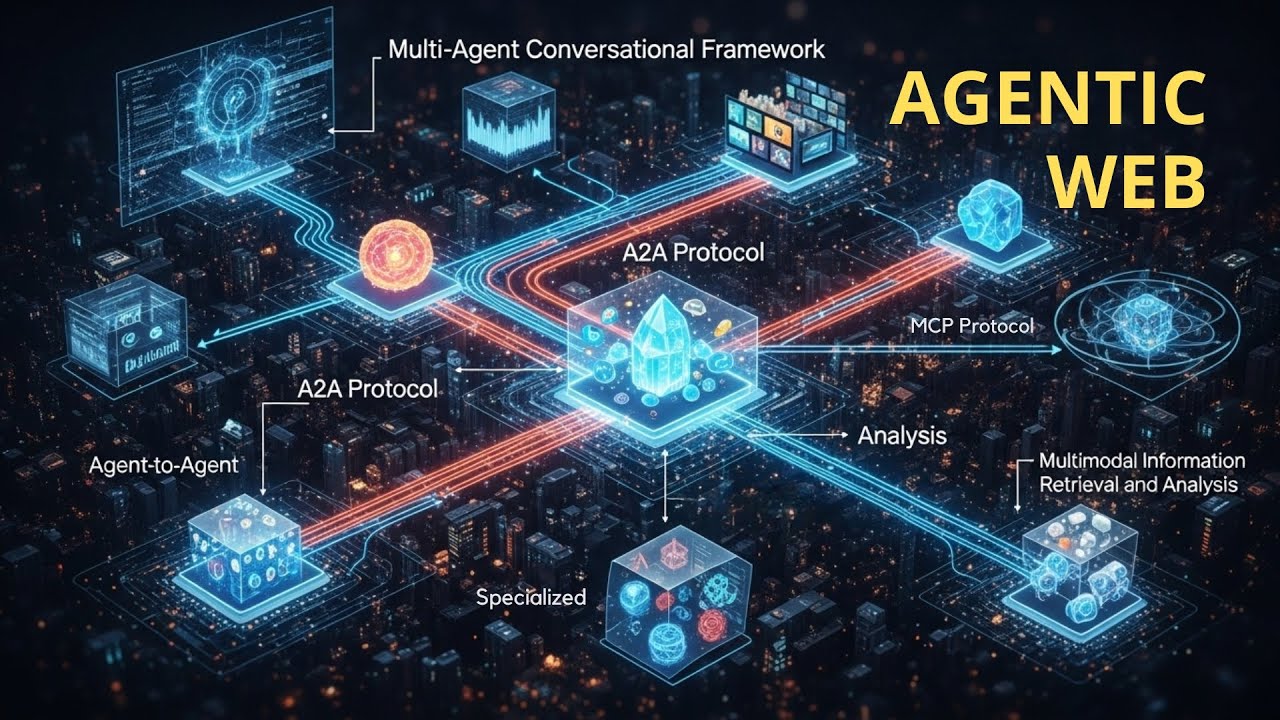
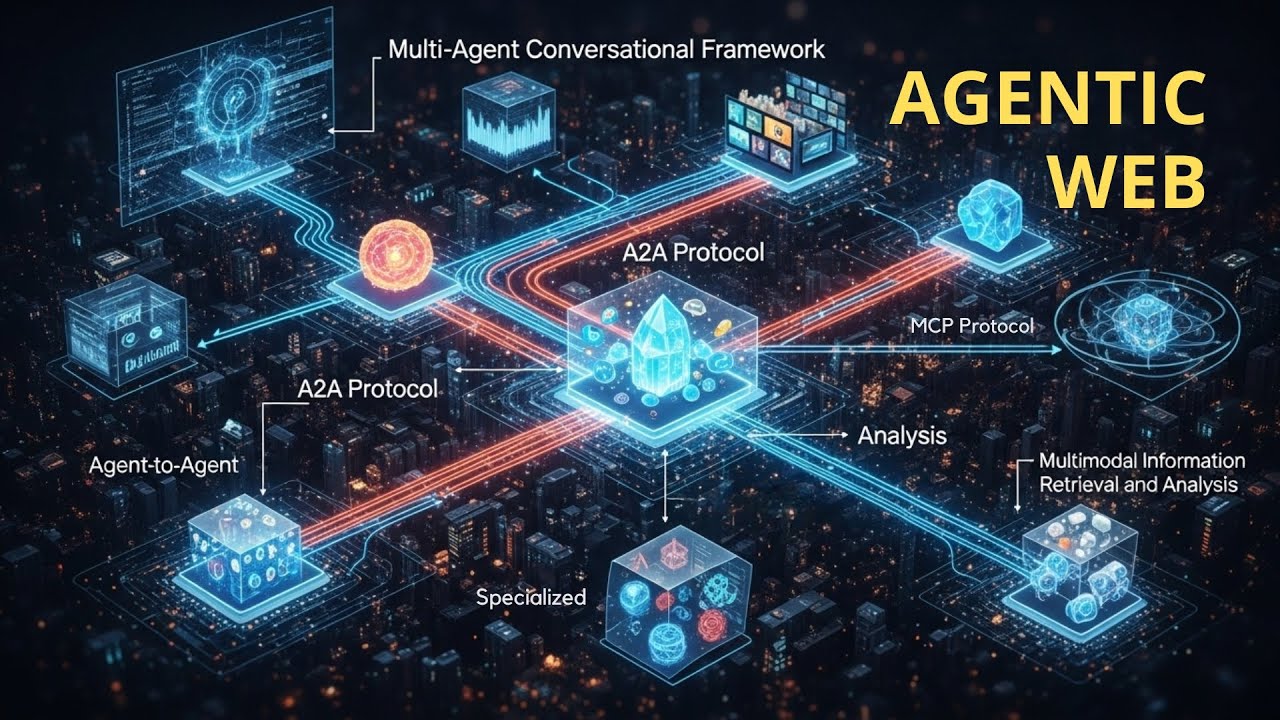
今、マルチエージェントシステムから、インターネットプロトコルの次のレイヤー、具体的にはインターネット自体に基づくセマンティックウェブ構造への体系的進化があるんや。
ビジョンを見てみよう。複数のAIエージェントによる新しいウェブが出現するっちゅう予言や。彼らは新しい時代に入ってるって定義してる。エージェントウェブ時代、つまり知能的なLLMやビジョン言語モデルによって動力を得た自律的ソフトウェアエージェントが仲介者として機能し、人間ユーザーの代わりに目標指向タスクを持続的に計画、調整、実行する分散インターネット生態系や。
彼らが言うには、PCウェブがあって、人間が静的文書のウェブを閲覧してた。それからモバイルウェブ段階があって、人間が作成されたアプリのウェブと相互作用してた。俺のスマホには20個のアプリがある。次はエージェントウェブや。人間がすべての意図を自律エージェントのウェブに委任するんや。
この段階では、人間はもうアプリが必要なくなる。なんでかって、主要な相互作用が機械対機械の動的で編成された協力になって、人間が参加できるレベルとは全く違う複雑さでユーザーの目標を達成するからや。
アプリの終焉とAI主導の未来
ここで最初の論文が示してるのは、PCウェブエラー、それからモバイルウェブ時代、そして2025年から始まるエージェントウェブエラー、AIインターフェース、複数のAIエージェント、知能的ランタイム、クラウドインフラストラクチャ、主要特性が定義されてる。
ちょっと考えてみよう。iPad、iPhone、Androidスマホとか、常に周りにある従来のアプリが存在しなくなるシナリオで作業するとしよう。なんで人間がアプリを使わなあかんねん?なんで2026年にマルチエージェントシステムがあるのに、人間がアプリを開発し続けなあかんねん?
このAIハイプは本物やって言おう。アメリカでは次世代の開発だけで1000億ドル以上投資されてる。AIが2026年も続くっちゅう勢いが築かれてて、何か別のもんを考え出さなあかん。彼らは投資と収益率を持ってこなあかんし、新しい市場ダイナミクスを見る必要がある。
でも人間がアプリしか使わなくて、俺のスマホにエージェントがいるとしよう。もうスマホを触る必要がない。アプリを開く必要もない。エージェントは違う知能ワークフローを持ってるからや。今日プログラムしてみると、人間の相互作用にはもうアプリが必要ないってわかる。
エージェントウェブの三次元
著者は3つの次元を特定したって言うてる。最初は知能次元や。これはエージェントの脳や。もう情報検索じゃない、RAGグラフリグとかそんなんじゃない。多段階推論、因果推論、文脈理解、将来可能性の予測、長期計画、適応的継続学習、文脈理解なんや。エージェントは自分の目標について推論できなあかん。プロンプトに反応したりアプリを作ったりするだけじゃあかん。
それから全く新しい相互作用次元がある。これを望むなら、この新しい生態系の神経系や。エージェントはどうやってコミュニケーションするねん?古いHTTP要求応答は絶対に不十分や。これにはエージェントネイティブプロトコル、エージェントだけがお互いを発見し、交渉し、複雑なワークフローを編成できるインターネット上の新しいレイヤーが必要や。これは人間向けじゃなく、純粋にAI用のインターネットレイヤーや。
もちろん、誰かがこれにお金を払わなあかん。それは消費者の俺らや。この新しい技術パラダイムの経済次元がある。これを市場次元に持ち込むからや。これはマーケットプレイスになって、人間じゃなくエージェントがサービスの主要消費者になる。FacebookやWhatsAppみたいな従来のGoogle基盤の広告ベースモデル、この広告ベースモデルは崩壊する。もう機能しない。
新しいエージェント注意経済が必要や。自己注意じゃなく、ただのエージェント注意経済や。現在、これをどう構築するか、人間が何かをクリックしなあかん広告からどう移行するかについて多くの新しいアイデアがある。エージェントがすべての作業をするとしたら?エージェントは広告に興味がない。
だからグローバル企業は新しいビジネスモデルを考え出さなあかん。これにより、雇ったりレンタルしたりするエージェントによって編成される特定のAPI呼び出しのマイクロペイメントのような新しい収益化モデルが必要になる。
「おお、それは良さそうやな」って言うかもしれん。複数の大学からの77ページの詳細があるで。でも実際にどうやって構築するねん?どれぐらい近づいてるねん?
実装段階の現状
俺らはめちゃくちゃ近いで、実装段階で。すでに設計図があって、すでに実行中や。2つの基本プロトコルがあって、2番目の論文から取り上げてるんやが、皆さんも知ってる。俺がこれについて複数のビデオを作ってるからな。
モデルコンテキストプロトコル。確実に馴染みがあるやろ、もう構築してるかもしれん。AnthropicのMCPは、エージェントがツールやすべての外部リソース(SQLデータベース、API、ファイルなど)とどう相互作用するかを標準化してる。ツール用のプラグアンドプレイ標準や。
もちろんGoogleによるエージェント間通信プロトコルA2Aもある。エージェントに関するすべてを知ってるやろ。これについて3つのビデオがある。Googleによるエージェント間プロトコル、古典的なマルチエージェントセンターや。
システムアーキテクチャがあれば、論文で具体的なケーススタディを見つけられる。かなりシンプルなケーススタディで、このトピックに詳しければすぐに何を話してるか理解できる馴染みのある用語ばかりや。
実践例と現実の課題
初心者向けに簡単な例を挙げよう。将来、現在すでに運用可能やが、ユーザーが複雑なマルチモーダルクエリを持ってる。「この橋の画像を分析して、メンテナンス履歴についてデータベースをクエリして」みたいな。
通常の古い従来システム、マルチエージェントで何が起こるかっちゅうと、クエリを受け取るオーケストレーションエージェントがある。これがエージェントのボスや。A2Aプロトコルを使って、このエージェントが専門ドメインエージェントを発見し調整する。
この単一オーケストレーションエージェントの知能、事前訓練、因果推論、文脈理解を考えると、このエージェントは3つの追加専門エージェントが必要やって決める。例えば画像エージェント、データベースクエリやSQLエージェント、橋梁建設部門の履歴データ用検索エージェントとかな。
高度に専門化されたドメインエージェントがあって、それぞれのツール(ビジョンAPI、SQLデータベースなど)とやり取りするためにMCPプロトコルを使う。すべてが報告されて、オーケストレーターの中央知能がすべてを統合する。でも機能しない。かわいそうなオーケストレーターが圧倒されて、驚くべき幻覚が起こるんや。
検証段階の複雑さ
検証段階はどうやろ?これが3番目のステップや。「構築したもんが実際に機能してるか確認したい。30%成功?50%成功?70%?」エージェンシーを測定する科学や。
でも注意せな、これは単一LLMの話じゃない。単一エージェントの話でもない。マルチエージェントシステムの高密度で複雑なインターネットネットワークの話や。何を正確に測定したいねん?
もちろん最終結果、これが一番簡単や。でも考えてみい。LLMや単一エージェントの評価は、ベンチでカーエンジンをテストするようなもんや。でもメモリ、ツール使用がある環境でのエージェントの相互作用は、レーストラックや市街地交通、オフロードで車全体をテストするようなもんや。動的で変化する相互作用環境でのシステム全体の性能、信頼性、安全性を評価するんや。
マルチエージェントシステムとしてのアクション空間が次に何をするかを定義し、環境から特定の応答を得る。この評価ルーチンは俺らが知ってることとは全く違う。
少なくとも2つの次元がある。何を評価するかと、どう評価するか。
評価の複雑さ
何を評価するかは簡単そうに見える。エージェントの行動、能力、信頼性、安全性、整合性や。単一の構成要素なら簡単やろうが、多次元、多成分、多重に絡み合った通信に加えて、エージェントの脳であるLLMのトランスフォーマー用の異なるアクション空間がある。
行動だけ考えてみよう。エージェントはタスクを完了したか?簡単や。出力の品質はどうやった?もうそんなに簡単じゃない。プロセスは正しかったか?エネルギー効率は?コスト効率は?エージェントは異なるツールをどれぐらい上手く使ったか?異なるツール選択の精度は?この特定のタスクに100%の性能を持つツール1つを選ぶ代わりに、50%しか適切じゃないツール2つで作業してたんちゃうか?ツール使用の計画はどれぐらい良かった?与えられた問題を分析する推論はどれぐらい良かった?
計画品質、信頼性での進捗率はどうや?信頼性を安全性と混同したらあかん。信頼性は一貫性と堅牢性や。1回機能したら、生産ホールで何回も機能してほしい。
毎回成功するか?本当に、エラーや環境の予期しない変化をどう処理するか?突然APIキーを失ったらどうなる?安全性、整合性、信頼性、俺らが小さな子供のように立ち尽くしてる一枚岩の用語で、マルチエージェントシステムでこれを本当にどう切り抜けるかわからへん。
人間参加型評価の重要性
次元2、どう評価するか。明らかに、俺らは皆、相互作用モードで同意するやろ。データ、特定の能力を持つ複雑さのベンチマークを評価する。ソフトウェアエンジニアリングタスクからいくつかのベンチマークがすでにある。でも、これはソフトウェアエンジニアリングとは全く違う。計算に選べる異なるメトリクスについて考えてみい。
ゴールドスタンダードは何か?2番目の論文で教えてくれてる。「ヒューマン・イン・ザ・ループ」や。
新しく魅力的なストーリーラインが浮かび上がる。俺らは単独のAIモデルを構築してるんじゃない。より複雑なエージェント的動的ウェブシステムの不可欠な部分として設計された要素を構築してるんや。
エージェントウェブの未来像
エージェントウェブ、人間がアプリと相互作用するんじゃなく、自律エージェントが全く違うレベルの複雑さ、相互作用、推論を実行する世界に住む新しいデジタル世界や。
このエージェントウェブは、インターネット上に新しい分散計算レイヤーを設計することで、マルチLLM駆動エージェントの概念を運用化する。プロトコル問題と、エージェント注意経済などから必要な経済モデルすべてについて話した。
もう一歩進めるか?もちろんや。人間がループにいて新しいアプリをコードするシステムから、人間がループの上にいて高レベルの意図をマルチエージェントシステムに委任するシステムに移行してる。
過去2週間、俺はもうアプリをコードしてない。小さなアプリやGoogleが呼ぶ「ちっちゃなアプリ」をコードするためにAIがある。でもAIが今アプリをコードしてる。AIがやってるのに、なんで人間が時間と脳力を無駄にしてアプリをコードせなあかんねん?
次世代の問題に取り組まなあかん。そのためのアーキテクチャをどう構築するか。3つの次元があるって言った。知能次元、相互作用次元、そして数十億、たぶん数兆ドルを期待する新しい経済の経済次元。簡単じゃない。
技術的深層分析
もうちょっと深く行こう。俺らが操作してるのはLLMやっちゅうことを理解せなあかん。エージェントの核心は、望むなら状態と行動の履歴を持つポリシー関数πだけや。そして新しい行動を予測する。
目標は、GPT-5とかの典型的単独LLMからの次トークン予測尤度の最大化から、与えられた目標Gに対する期待割引リターンを最大化するシステム全体の最適軌道を見つけることに移る。この文を見ただけで、次の深いレベルの複雑さを考えると俺の脳が爆発しそうや。
これをどうやってやる?相互接続があるマルチエージェントシステムの報酬システムをどう構築したい?標準LLMについて知ってることを超えなあかん。
計画と行動空間の課題
最初に計画について考えてみよう。エージェントが目標や成功パスが何かを覚えてるやろ?俺がLLMに与える本当に複雑な人間のタスクを取って、目標をより低い複雑さを持つサブ目標と行動のシーケンスに分解する。でも文脈理解が必要や。これは部分的にしか観測できないことを覚えておいてな。
エージェントは事前訓練から、環境と相互作用する環境の真の状態に対する内部信念状態を維持または開発せなあかん。すでに何十本ものビデオで話した部分観測マルコフ決定プロセスについて話してる。これが有限コンテキストウィンドウを超える構造化メモリシステムの理論的動機や。
行動空間について考えてみよう。テキスト生成だけでなく、インターネットで利用可能な外部ツールで使えるすべての行動を含む、はるかに複雑な行動空間で動作してる。
言語と実行可能行動のグランディングは、エージェンシーの基石やったが、もはやそうじゃない。
相互作用次元の課題
相互作用次元について話そう。エージェントウェブには、セマンティック相互運用性と動的構成を可能にする新しいプロトコルスタックが必要や。特にインターネット規模のマルチエージェントシステムがある場合。
エージェントがインターネット上のどのソースで、どのツール機能シグネチャ、パラメータスキーマ、予測を発見できるかについて考えてみい。エージェント間相互作用について考えてみい。
エージェント間の構造化対話におけるセマンティック誤解釈の問題、タスク委任、交渉、協調問題解決について考えてみい。この話はやめとこう。
経済モデルの変革
次のAIステップでやることは、人間主導のページビューに代わってエージェント主導のAPI呼び出しがある。完全な広告収入ストリームシステムが崩壊する。だからグローバル企業は俺らのエージェント用の新しい経済モデルを提示せなあかん。これは絶対に魅力的な時代になる。
スケーラブルな計画。不確実性の下で外部環境との相互作用における現実世界の長期タスクの組み合わせ複雑さを処理するために、LLMベースの計画をどうスケールするか?
プロトコル進化はどうや?MCPとA2Aのトレードオフの限界は何や?単一の古典的検証やスタックのAPIキーを超える信頼、評判、検証のメカニズムをどう組み込む?
継続学習の課題
みんなが話してるメイン問題、継続学習。エージェントは壊滅的忘却なしに、全体験から彼らのポリシーと内部世界モデルをどう継続的に適応させる?GPTやSFTがあるなら、この特定のトピックについて新しいミニシリーズが出る予定や。
さらに、評価の科学が最終的にシステムのより高いレベルの複雑さで再び浮上する。挑戦的で包括的なだけでなく、システムの全く異なるレベルで複雑なベンチマークをどう作成する?
もし興味があるなら、今日発表された3つの論文を選んだ。エージェントウェブ、次のウェブの織り込み。2番目のエージェントマスター、なんで7月8日の日付になってるかわからんが、今日発表されて、2025年7月29日。SAP、この評価は絶対に魅力的や。
現実の技術的制約
マルチシステム構成に行くと、SAPが評価目標について本当に良い論文を書いてて、プロセス自体から分離してる。エージェント行動、エージェント能力、再び信頼性、安全性、整合性、多くの未解決問題がある。これにどう対応するかわからん。単一エージェント性能や2、3エージェントグループ性能、クラスター性能だけでなく、システム全体性能をテストするマルチエージェント協調システムのテストをどう設計する?これが本当に最良の構成か?確率的環境で作業してて、決定論的環境じゃない場合、このためのベンチマークをどう構築する?
マルチエージェント協調自体がパンドラの箱や。金融意思決定と構造化データ分析について考えてみい。情報を交換し、互いに交渉し、意思決定プロセスを効率的に同期し、人間の干渉なしに結論に達せなあかん自律エージェントがある。これはたぶん皆さんのお金や。
協調タスク、協調効率。複数のエージェントが責任をどれぐらい上手く共有するか。OpenAIがAIに法的地位、法的責任を与えるっちゅう最新のアイデアについて考えてみい。確率的システムの動的レベルでの分散タスク性能をどう評価する?信じられない時代が待ってる。
信頼性、安全性について話した。「これは魅力的に聞こえる」って思うかもしれん。絶対にそうや。でも、これがサンシャインバージョンやってことに気づいてもええか?今現実に来る。
プロトコル戦争と相互運用性
すべての論文とプロトコルの必要性を特定する論文1があるが、プロトコル戦争がある。シームレスな相互運用性の目的を無効にするエージェントのバブルがある。みんな独自のシステム、独自のフレームワークを構築したがる。何やと思う?多くの場合、相互運用できない。
エージェントはA2Aのエージェントカードとツールスキーマのセマンティクスを正しく解釈せなあかん。著者によると、これは本当に問題や。関数の自然言語記述は悪名高く曖昧で、構造化スキーマでも「便利なフライトを予約する」みたいな概念は仕様不足で文脈依存や。
これは、マルチエージェント構成間のセマンティック不整合に根ざした新しく興味深いクラスの新しいバグにつながる。まだ存在しないはるかに洗練されたセマンティックデバッグツールが必要や。
分散信頼の課題
分散信頼、本当に、これは俺らが今持ってる最も重要な概念的ギャップや。エージェントは、個人的な金融データ、医療データ、金融取引を含むタスクを委任する前に、オープンインターネット上の未知のエンティティとどう信頼を確立する?
分散アイデンティティ、検証可能な資格情報、たぶん暗号学的にセキュアな基盤モデルの新しいスタックが必要や。まだわからへん。
だから大規模な独立研究分野で、これがなければ、取引認証ウェブは高リスクアプリケーションにとって非スターターや。これはアプリ開発者用のサンドボックス、遊び場やけど、マーケットプレイスじゃない。
オーケストレーターの限界
オーケストレーター、すでに言うたが、エージェントネットワーク全体の中央知能がある。
ほう?このアーキテクチャは単一の中央集権エージェントに膨大な認知的・運用的負担をかける。このエージェントはすべてのクエリ分解、すべてのルーティング、すべての統合に責任があって、モデルはすべてを分解するのが簡単やって仮定してる。実際には、複雑なクエリ、分解自体がNPハードになりうる。
オーケストレーターは、すべての能力とすべての現在状態、従属エージェントの負荷可用性の完璧なリアルタイムモデルをリアルタイムで維持できるっちゅう希望がある。中央集権モデルは認知的ボトルネックで、スケールしない最も重要な単一障害点や。
興味深いモデルが出てくる。コールドチェーンでの致命的な遅延がある。すでに見てるオペレーターとかコンピューターを引き継いでより複雑なタスクを与えるLLMについて考えてみい。5分待つ、10分待つ。もちろん遅延がある。
この記述された端末間ワークフローは、ネットワーク要求とモデル干渉の長い連続チェーンを表してる。ユーザー、サーバー、オーケストレーター、A2A、ドメインエージェント、LLM、MCP2、APIなど。これはまだ始まりや。検証ステップについて話してさえいない。
だから現在、累積遅延はあらゆる対話型アプリケーションにとって絶対に受け入れられない。著者が教えてくれる。新しいもんが必要や。投機的実行みたいな技術が必要や。すばらしい、すでに確率的実行があって、今度は投機的実行がある。これを楽しみにしてる。
もちろん、すべてのタスク、サブタスク、すべての依存関係の並列化を増やさなあかん。現在全く対処されてないはるかに洗練されたキャッシングが不可欠や。
状態管理とセキュリティの悪夢
分散システムでの状態管理の悪夢は、専門家に任せる。分散システムで作業してるなら何を意味するかわかるやろ。中央集権取引コーディネーターなしの同期、カスケード誤り伝播について。
俺らが構築したもんについて考えてみい。フレームワークの障害に対する堅牢性は絶対に未証明や。リーフノードでの単一障害、特定の日にエージェントAPIキーが突然期限切れになるみたいなことが、オーケストレーターまで伝播する例外のカスケードを引き起こしうる。
生産グレードシステムには、文脈認識の再試行、フォールバックエージェントを含む各レイヤーでの洗練されたエラーハンドリングロジックが必要や。どう構築するかわからへん。
セキュリティについて話そう。実装セキュリティモデルは現在、異なるエージェント用の別々のAPIキーや認証に限定されてるように見える。これは絶対に不十分や。
インターネット上で自律的に動作するマルチエージェントシステムがある場合、何が起こりうるかわかるやろ?データ汚染、エージェント間通信でのプロンプトインジェクション攻撃。
だから、すべてのエージェント間通信が認証、検証、無害化される零信頼アーキテクチャは、セキュアなエージェントウェブにとって本当に交渉の余地がない。
最も重要な科学的ギャップ
最も重要な科学的ギャップ。これは自由落下や。システム、システミックリスクと創発リスク。
全体の評価フレームワークは、明確に定義されたタスクでの単一エージェントや小グループの性能評価に向けられてる。現実世界に出て、実際のエージェントの複数グループとの現実世界相互作用があると想像してみい。
グローバルエージェントウェブの最も破滅的なリスクは、何百、何千、さらに多くのAIエージェントの相互作用から生じる創発的システミック現象になる。何が起こりうるかわからへん。
アルゴリズム的フラッシュクラッシュをテストする方法論がない。自律金融エージェントがある場合を考えてみい。市場セグメントを不安定化しうる自己強化フィードバックループを作成できる。
規模での協調偽情報。悪意のあるエージェント間の創発的協調で、信じられる誤情報を生成・伝播できる。
システミック目標劣化。単一目標のローカルプロキシメトリクスに最適化されたエージェントが、集合的にグローバルに望ましくないか安全でない結果を生み出す場合。会社の一部門は成功するかもしれんが、会社の他のすべての部門を犠牲にして、結果的に会社全体の性能が低下する。
現実への回帰
問題がある。魅力的や。現実にようこそって言う。世界中のすべての美しい情報を持つSAPからの3つの美しい理論的AI研究レポートを読むのが好きや。でも俺らが扱ってるもんについて考えてみい。
部分観測マルコフ決定プロセスについて話してて、ポリシー実行者があって、これが最適化してるオブジェクトや。このLLMによる分析を与えられた非常に特定の報酬関数を定義する人間の目標、高レベル目標を取って、エージェントのタスクは特定のポリシーπを実行することや。
テキスト、ツール使用、他のエージェントとの通信、内部世界モデル理解と将来行動の結果予測に基づいて、現在の信念状態とすでに実行した履歴行動に基づいて、より大きな行動空間から特定の行動を選択する。
「これは数学的最適化手順や。俺の仕事は期待将来報酬関数を最大化することで、この報酬関数は明示的・暗示的で、異なる複雑さモデルで数学的にモデル化できる」って言うための一貫したシーケンスを持つために。
このビデオでAIの将来について皆さんに与えたかった感覚をたぶん得てもらえたやろ。
素晴らしいことになるが、俺らの前には多くの作業がある。信念状態、行動空間、他の状態、ポリシーについてすべて。このポリシー最適化の小さな道具が人類の超知能になるべきや。これについて確信してる?
次のステップ
本当に次のステップは何や?研究の次のステップは、システム全体構成での超低遅延、分散状態一貫性と整合性である非機能要件に対処せなあかん。セキュリティレベルで何かせなあかん。たぶん暗号学的セキュリティに行かなあかん。マルチエージェントシステムをスケールするはるかに良い、はるかに堅牢なエラー回復を見つけなあかん。そうでなければ非スターターや。
この種のビデオを楽しんでもらえたら嬉しい。もっと見たいなら、なんで購読せえへんのや?次のビデオで会おう。


コメント