この動画では、xAIのGrok 4が従来のAIモデルとは異なる「流動的知能」と呼ばれる新しい能力を示している可能性について解説している。Grok 4はARC AGIベンチマークで16%という前例のないスコアを記録し、他のモデルが6-8%程度に留まる中で圧倒的な性能を見せた。これは単なる記憶や学習済み知識に頼る「結晶化知能」ではなく、新しい問題に対してその場で適応し学習する「流動的知能」の兆候である可能性が示唆されている。また、Grok 4は仮想の販売機ビジネス運営テストでも人間を上回る結果を出すなど、複数の領域で革新的な性能を示している。

Grok 4の圧倒的性能とAI競争の現状
イーロン・マスクさんは、ARC AGI 3を楽しみにしています。なぜかと言いますと、彼がARC AGI 2を完全に攻略してしまったからです。文字通り粉砕したのです。
この時点で、皆さんも新しいGrok 4について様々なことを聞いているでしょう。人類最後の試験と呼ばれるベンチマークで、他のすべてのモデルを完全に圧倒したのをご覧になったかもしれません。
Grok 4とGrok 4 Heavyの両方が、競合他社を大きく引き離しています。Gemini 2.5 Proを上回り、o3も上回っています。そして、そのギャップが存在することに注目してください。ツールなし、またはツール使用ありという違いがあります。
o3 ProやGrok 4 Heavy、そしてGrok 4といったモデルは、ツール使用機能を持っています。つまり、6ヶ月から12ヶ月前に慣れ親しんでいた古いモデルのように、単純にプロンプトを入力して出力を見るというものではありません。
現在、舞台裏で起こっていることの多くは隠されています。モデルが物事を考え抜いている際の思考の連鎖を実際に見ることはできません。バックグラウンドで実行されているすべてのツールを見ることさえできません。
例えば、o3 Proのようなものを使用する場合、バックグラウンドで多くの処理が行われていても、それに気づかないかもしれません。例えば、コードを実行して、そのコードからの回答だけを提供することができます。コード自体は表示されませんが、横にあるスクラッチパッドのような思考をまとめる場所に、「ノートブックでこれを実行し、Pythonコードの出力は以下の通りです」といったようなヒントとなる一文や二文があるかもしれません。
つまり、バックグラウンドで何かを実行しているのですが、私たちには見えません。そして、すべての企業がその方向に向かっているようです。私たちはもはやモデルと一対一で対話しているのではありません。システムとやり取りしているのです。モデルに加えて、それが使用できるツール群との組み合わせです。何にアクセスできるのか正確には分からないかもしれませんが、おそらくウェブ検索、基本的なコード実行などが含まれているでしょう。
競合他社の動向とGrok 4の優位性
これらは素晴らしい結果ですが、Google DeepMindが追い上げてくる可能性があることを覚えておいてください。Gemini 3.0 Proが目撃されているので、間もなく見ることになるかもしれません。スンダー・ピチャイとデミス・ハサビスの両名が、イーロン・マスクの新しいGrok 4の発表を祝福しています。GoogleのCEOとGoogle DeepMindのCEOです。
しかし、疑問が生じます。彼らがGemini 3.0 Proをリリースしたときに何が起こるのでしょうか?そして、それはかなり早く実現しそうです。その時、どのような立ち位置になるのでしょうか?Grok 4は長期間にわたって世界ナンバーワンのAIモデルであり続けるのでしょうか、それとも短期間で終わるのでしょうか?
Jimmy Applesという人物は、これまでに情報をリークし、一般に公開される前に長期間にわたって一部の情報を的中させてきました。ですから、私は彼の言うことを疑いながらも信頼する傾向があります。彼は以前にも不気味なほど正確だったからです。ですから、これを軽視してはいけません。
彼は、いくつかの鳥からささやきを聞いていると言っています。これは『ゲーム・オブ・スローンズ』の参照に違いないでしょう。近日中にリリースされると噂されているGPT-5の内部評価について、それらがGrok 4 Heavyをわずかに上回っているということです。
まとめると、AI分野で他の企業よりもずっと遅くスタートしたイーロン・マスクが、後ろから追い上げて1位の座に着いたということです。AIM25で100%を見てください。そのベンチマークは完全に攻略されました。
スケーリングの秘密:計算資源の大幅な増加
彼の成功の秘訣は何でしょうか?注目すべきは、Metaが行っているように才能の獲得に数十億ドルを投じなかったということです。彼に他社を上回る画期的なアルゴリズムがあるかどうかは分かりません。おそらくないでしょう。おそらく他の人々がやっていることと似ているでしょう。後でそうではないことが判明するかもしれません。彼に秘密兵器があるのかもしれません。
しかし、このような問題の解決策は、時として、そしてFactorioをプレイしたことがある人なら分かると思いますが、時には単に「もっと」が必要なのです。たくさん、もっと。思っているよりもずっと多く。合理的と思える量よりもずっと多く。すべてのものをもっと。この場合、「すべて」とは計算資源のことです。
彼らは10万台のH100 NvidiaのGPUを持っており、これを20万台まで増やそうとしていると思います。また、時々Amazonでパッケージを注文すると家に配達されますが、イーロンも自宅に物を配達してもらいます。ただし、彼が注文するのは海外の発電所です。発電所を配達してもらうのです。官僚的な手続きを避けるため、ここで建設するのではなく、海外の発電所を購入してメンフィスに輸送してもらっています。
このチャートに見られるように、Grok 2からGrok 3への事前学習計算資源は10倍、Grok 4推論のための強化学習計算資源はGrok 3推論で使用したものの10倍です。
ここでは事前学習計算資源は同じで、その上に10倍の強化学習計算資源が追加されているように見えます。また、次世代のGrok 5が現在学習を開始していることも言及されています。
これは、OpenAIの誰かが提起したアイデアを強化しているように思えます。基本的に、例えばGPT-4oは推論モデルではありませんでしたが、すべての計算資源が事前学習に向けられました。o1は最初の推論モデルでしたが、答える前に推論することができました。強化学習計算資源を使用しましたが、それは事前学習計算資源の総量に比べて小さな割合でした。o3では、より多くの強化学習計算資源を使用しました。
強化学習計算の重要性拡大
つまり、事前学習計算資源に比例して成長しているのです。ある時点で、事前学習計算資源のサイズにより近づくことが期待されます。つまり、強化学習は成長し続けるのです。強化学習に投入するハードウェアの量は成長し続け、最終的には事前学習計算資源を完全に上回ることになります。
ちなみに、これは同じ量の事前学習計算資源を投入していることを意味するかもしれません。この小さな円はこれと同じですが、投入する強化学習計算資源の量は10倍、20倍になります。これがこれが示唆していることのようです。
スケーリングが壁にぶつかっているという考えは、誤解を招くものだと思います。本当に注目すべきなのはこれです。彼らは数週間以内にGrok 4のコーディングモデルをリリースすると発表しました。おそらく4週間程度と言っていたと思います。ですから、おそらく8月のいつかに見ることになるでしょう。
これが私にとって究極のテストになります。なぜなら、そのコーディングモデルを他のコーディングモデルと真正面から比較して、最終版がどのようなものになるかを確認できるからです。現在、Grok 4とGrok 4 Heavyをテストしていますが、コーディングは良さそうですが、圧倒的というほどではありません。期待するような大きな飛躍ではありません。それは、まだコーディングモデルではないからです。優秀なコーダーにするための調整がまだ完了していないのです。
それを4週間後に見ることになるでしょう。もちろん、4週間というのはイーロン時間での4週間ですが。それがリリースされれば、現在のコーディングモデルと比較してどのような効果があるかを知ることは本当に興味深いでしょう。大幅に、大幅に良くなるのでしょうか?時間が教えてくれるでしょう。それを待ちましょう。
流動的知能という新しい指標
しかし、ここからが非常に興味深いところです。新しい指標が発達しているようで、まだそれに対する適切な言葉さえないかもしれませんが、基本的に結晶化知能と流動的知能という考え方があります。
流動的知能は、新しい問題を解決する能力、以前に実際に扱ったことのないものを解決する能力と考えることができます。つまり、以前の経験や教育などに関係なく、新しい状況に投げ込まれたとき、その新しい挑戦にどれだけうまく対処できるかということです。
これは結晶化知能とは対照的です。結晶化知能は、私たちが過去や経験を活用する能力のようなものです。これは時間をかけて発達するものです。一般的に、若いときはより良い流動的知能を持ち、年を取るにつれてより良い結晶化知能を持つ傾向があります。
繰り返しますが、これは一般化ですが、流動的知能は通常、成人初期にピークを迎えます。そのため、年を取ってから学校に行くのは難しいと言われることがあり、子供たちに多くの新しいことを学ばせたいのは、それが流動的知能のレベルを本当に示す時期だからです。
考えてみてください。大規模言語モデルは流動的知能を持っているのでしょうか、それとも結晶化知能を持っているのでしょうか?彼らは流動的知能をほとんど持っていません。結晶化知能をたくさん持っています。語彙、膨大な知識ベースを活用することはできますが、新しい環境での問題解決、革新的な解決策を考え出すという考え方において、大規模言語モデルは terrible です。
ARC AGIとGrok 4の画期的な成果
ですから、ARC賞の会長であり、leverage.toの創設者であるグレッグ・カマラックが、Grok 4がゼロではないレベルの流動的知能を示している、つまり何らかの流動的知能を持っていると言っているとき、それは私にとって何かを呼び起こします。「警鐘が鳴る」という表現がありますが、「耳がそばだつ」という感じでした。そう、それでした。
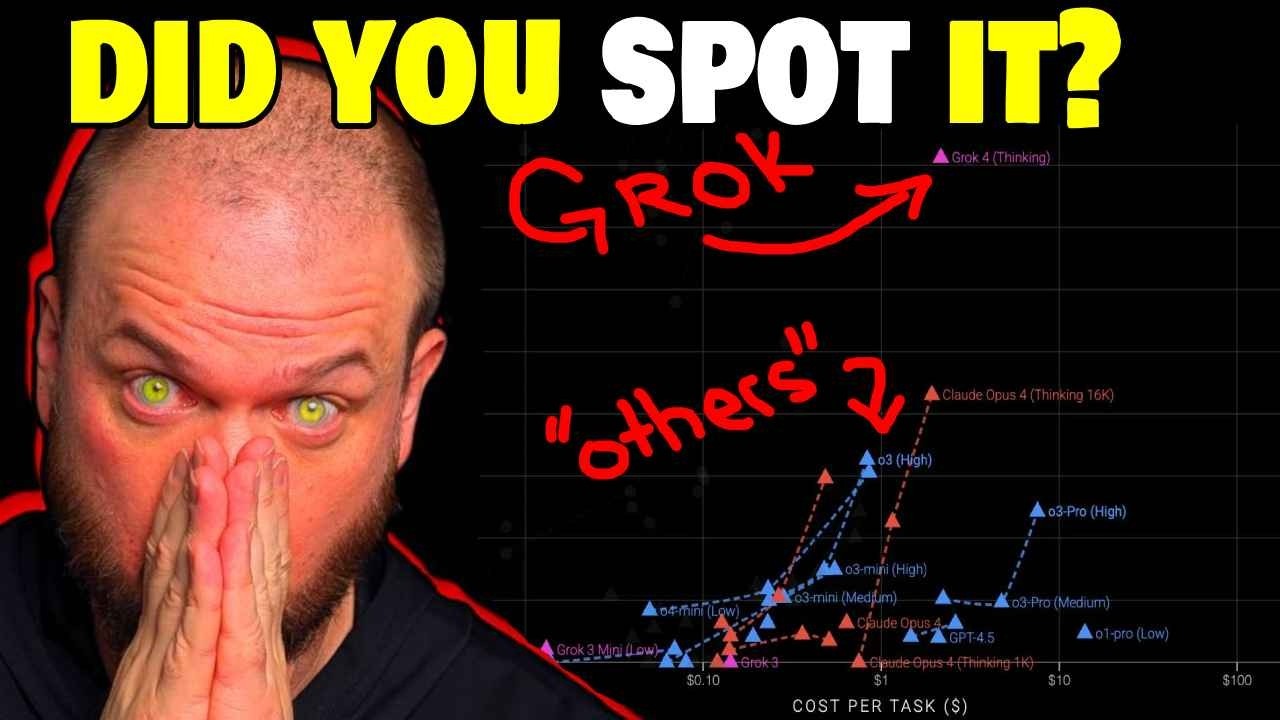
彼がそう言っている理由はこれです。このチャートを見ると、他とは異なるデータポイントが一つあります。ここには、ARC AGIベンチマークでのタスクあたりのコスト、つまり問題あたりのコストがあります。計算資源APIクレジットで、これらのモデルの一つがそれらのタスクの一つを解くのにどれくらいのコストがかかるかです。
これを追跡している理由は、元のARC AGI、元のものについて、o3プレビューまたはo1だったと思いますが、覚えていませんが、OpenAIの推論モデルの一つがそれを破ることができたからです。人間のベースラインを打ち破ることができ、それによってそのベンチマークを破ったのです。なぜなら、それはしばらくの間は達成されないだろうと言われていた元の目標だったからです。しかし、一つだけ問題がありました。
タスクあたりの価格が非常に、非常に高かったのです。私が推定したところでは、そのモデルでそのテストを受けるのに約30万ドルかかったと思います。私たちがそれらのAPIコストを支払っていたら、それくらいのコストがかかったでしょう。いずれにしても、それは大金でした。
これも対数スケールであることに注意してください。1から10、100、1,000です。つまり、これらは同じ増分ではありません。この方向に進むにつれて、コストは急速に増加します。y軸には、どれだけうまくやったかのスコアがあります。
ご覧のように、これらのモデルはすべて、どこかここらに集まっています。これは6%の精度、4%の精度といったところです。これらの中で最も高いのは、8%をわずかに超える精度のClaude Opus 4です。
そして、本当に際立っているのが一つあります。それがGrok 4、思考モデルです。これらのほとんどのコストと一致していますが、はるかに優れており、16%スコア精度のすぐ上に位置しています。
ARC AGIベンチマークの重要性
ARC AGIの何が大きな問題なのでしょうか?なぜARC AGIについて話しているのでしょうか?他のベンチマークとどう違うのでしょうか?
それはフランソワ・ショレーによって作成されました。彼は文字通り知能について、知能の測定について本を書きました。そして彼は、知能は未知のタスクでのスキル習得の効率性によって測定されると言っています。単純に言えば、新しいスキルをどれだけ早く学習できるかです。
AGIの基本的な考え方は、これらのモデルがいくつかのスキルを持つことができ、特定のことを達成できるということですが、タスク固有のスキルを測定することは知能の良い代理指標ではないということです。
これらのベンチマークのほとんどは、特定のスキルでの物事の能力を測定します。これらの博士レベルの質問に答えることができますか?これらの種類の数学問題を解くことができますか?
ARC AGIとフランソワ・ショレーは、問題を逆転させました。彼らは特定のスキルについては気にかけませんでしたが、何か異なること、人間にとって非常に簡単で、これらの大規模言語モデルにとってはほぼ不可能なことをテストしようとしました。
私たちはスキル自体ではなく、スキル習得と一般化に興味がありました。子供が足し算、引き算、割り算を素早く理解できれば、「わあ、その子は賢いね」と言うでしょう。電卓は百万倍優秀ですが、それは静的で、そのいわゆるスキルが得意ですが、新しいスキルを習得することはできません。
素早くスキルを習得する子供は、知能が高いと言うでしょう。別の言い方をすれば、このARC AGI賞は、またはそれには賞がありますが、ARC AGIベンチマークは、結晶化知能ではなく、流動的知能、つまり推論し、新しい問題を解決し、基本的に適応する能力に焦点を当てています。
大規模言語モデルは結晶化知能が得意です。ほとんどのベンチマークは結晶化知能を測定します。そして、私たちが見てきたのは、これらの大規模言語モデルが結晶化知能でトップに這い上がってきたことです。彼らが苦手だったのは流動的知能、つまり素早く適応し、いわば現場で学習する能力でした。これは繰り返しますが、人間にとっては簡単なことです。
Grok 4の革新的な成果とその意味
そこでの問題はこのようなものです。これまで多くの異なる動画で分解してきたので、再度詳しく説明はしませんが、最初は複雑に見えるかもしれませんが、一度理解すると「ああ、分かった」となり、その問題セットを解くのが非常に簡単になります。
別の言い方をすれば、それを見て、この問題を解くためにどのような精神的ツールを作成する必要があるかを理解する必要があります。そうすれば、問題を解くのはかなり簡単になります。問題自体はある程度シンプルです。
そして、そのため、これまでのところ、ほとんどすべてのモデルが本当に苦労してきました。6%程度が一部の高いもので、o3 Proのような非常に優秀なモデルでさえ、実行するのに多額の費用がかかるにもかかわらず、5%の精度でした。
そして数日前、彼らはxAIから電話を受けました。結果をすべて発表する24時間前だったと思いますが、ARC AGIでGrok 4をテストしたいというものでした。
再び、これはARC AGIのグレッグからの発言です。彼は言っています。「噂は聞いていました。良いものになると分かっていました。ARC AGIで公開モデルのナンバーワンになるとは知りませんでした。」ここにテストストーリーと結果の意味があります。
彼らはxAIチームのジミーと話しました。Grok 4のスコアを検証したかったのです。彼らは独自のテストを行いましたが、スコアを検証し、可能な過適合を測定したかったのです。基本的に、これらのモデルをテストや類似のテストで訓練することで数字を少し偽装し、一般化がうまくいくからではなく、暗記のようなもので高いスコアを得ることができます。
公式スコアを得るためには、いくつかのことが真実でなければなりません。一つは、新しいモデルは半プライベート評価セットでテストされなければならず、おそらくARC AGIの誰かによってテストされなければなりません。この場合、xAIによるデータ保持なしなどのルールがあります。モデルチェックポイントは公開使用を意図したものでなければなりません。つまり、xAIだけが使用できる秘密のモデルではいけません。私たち全員が使用できるモデルでなければなりません。そしてもちろん、レート制限もありません。
事実として、Grok 4は現在、ARC AGIで最高性能の公開利用可能モデルです。これは、Kaggleで提出された目的別構築ソリューションさえも上回ります。様々な機械学習アプローチが、これらのテスト用にカスタム構築されています。それらでさえGrok 4ほど良くありません。
第二に、ARC AGI 2は現在のAIモデルにとって困難です。なぜでしょうか?再び、これが重要な部分です。これが私たちが話してきたことです。良いスコアを取るためには、モデルは一連の訓練例からミニスキルを学習しなければなりません。つまり、三つの例、一、二、三を示し、共通パターンが何かを理解しなければなりません。仮説を立てる必要があります。
そして、彼らはそれをミニスキルと呼んでいます。それからそれを問題解決に適用します。そしてテスト時にそのスキルを実証しなければなりません。以前のトップスコアは8%で、10%未満はノイズ、つまり決定的でない可能性があります。しかし、16%は基本的にそのノイズの壁を突破します。
そしてGrokはゼロではないレベルの流動的知能を示しています。これは、今後これらすべてのモデルを見る際の全く新しい種類のスカラー能力かもしれません。この用語「流動的知能」が定着するか、それとも何か異なるものを考え出すかもしれません。それは重要ではありません。
問題は、これらのモデルは適応できるのか?新しい状況で素早く学習し、それを適用して前進できるのか?ということです。再び、Grok 4は現在、それを示している唯一のモデルの一つです。
しかし、Geminiの回答がすぐに発表されるでしょうし、GPT-5もすぐに発表されるでしょう。そして、それらがどれだけうまくやるかは本当に興味深いでしょう。再び、噂では、GPT-5はこのテストで少し良い結果を出すということです。
ビジネス運営能力と今後の展望
新しいARC賞、グランプライズは、この緑の長方形のようなものです。基本的に、再び、コストとスコアです。これはARC AGI 1についてです。基本的に、ご覧のように、パターンが見えます。私たちが見たいのは、スコアの面でこれが上向きに続くことですが、タスクあたりのコストを減らすことで少し曲げ戻す必要もあります。
様々なモデルがそこにどれだけ早く到達するかを見るでしょう。しかし、それが確実にトップ近くにあるとは言えると思います。ナンバーワンだと言っても公平だと思います。
推論平均を見ると、ナンバーワンです。コーディングとエージェンティックコーディングでは遅れていますが、コーディングモデルはまだ出ていないことを覚えておいてください。あと数週間です。
ですから、最終的な決定を下す前にそれらのスコアを見たいと思います。このノンコーディングモデルは、他のトップモデルからそれほど遠くないことに注意してください。コーディングモデルがどこに着地するか楽しみにしています。
現在、ニューヨークタイムズのコネクションズベンチマークでナンバーワンです。私は実際に今日のニューヨークタイムズのコネクションズでテストしました。それは解けます。
答えを検索しないように言わなければなりません。そうでなければ、ただ答えを見つけて「これだと思います」と言うでしょうが、答えが何かを知っています。検索をせずに解いてくださいと言わなければなりません。しかし、それらの単語をどのカテゴリに属すると思うかに分類するのは非常に得意です。
スケーリングの将来性と新たな能力の出現
覚えておくべきことの一つは、一部の人々が言っているように、強化学習に10倍の計算量を費やしたのに、なぜより大きな飛躍が見られないのか?強化学習を間違って行っているのか?ということです。
ここにNews ResearchのTechniumからの発言があります。私たちは最近、News Researchの人の一人にインタビューしました。そのインタビューはまもなくYouTubeのWes and Dylanチャンネルで見ることができます。または、iTunes、Spotify、何でも、使用しているポッドキャストサービスで確認してください。まもなく見ることができます。
そのインタビューはクレイジーになります。News Researchについて何か知っている人なら、彼らはかなり次レベルのことをやっています。
Techniumがここで言っているように、またはベースモデルが弱いのか?これは検討すべき興味深いポイントだと思います。これらが驚異的な結果、本当に良い結果だと言っているのか、それとも感動していないのか。
再び、私にとっては、良い結果のように見えます。これが主に強化学習計算によって推進されていることは注目に値します。この多くは強化学習計算です。ある時点で、おそらく事前学習に多くの計算を投入し、強化学習にも多くの計算を投入するだろうということは安全に言えると思います。
つまり、ここでうまくいったこと、ここでうまくいったことすべてを取って、それらを互いの上に積み重ねるのです。それらすべてを一つの驚異的なモデルに組み合わせるのです。
再び、これまでのところ壁はありません。将来的に壁にぶつかるかもしれませんが、現在のところ、単に訓練、強化学習により多くの計算を投入することは機能しているようです。
流動的知能のような新しい能力の出現さえ見ているかもしれません。それに同意するかどうかは別として、それを解明しようとするより多くのテストが見られると思います。これらのモデルはその場で適応しているのでしょうか?
私の個人的なテストではこれまでのところ、このチャートはかなり的確だと思います。推論では優秀です。コーディングは良いです。良いです。私たちが持っているいくつかの本当に優秀なパワープレイヤーと比較すると、少し物足りない感じですが。一部の人はClaudeバージョンを好み、一部の人はGeminiを好みますが、Gemini 2.5 Proは優秀です。100万トークンのコンテキストウィンドウを持っています。それは驚異的です。
Grok 4は、ちなみに、まったくそこまではいきませんが、競合他社よりも大きいです。これはElvis、別名Omarからの本当に良い小さな要約です。彼はブックマークしてくださいと言いました。私はしました。256Kコンテキストウィンドウを持っています。つまり、再び、競合他社よりも大きく、Geminiの100万ほど大きくはありません。
自動販売機ベンチマークについて聞いたことがあるかもしれません。私たちは、様々なモデルに小さな自動販売機事業を運営させるすべての反復をカバーしました。これはAnthropic本社で行われた特定の実験で、Claudeがこのビジネスを運営します。
ここに小さなチェックアウトカートがあり、Anthropicの従業員が入って支払い、様々なもの、スナックや飲み物を購入します。Claudeの仕事は物を注文することです。彼はまた、彼らが使用するチャットアプリ、Slackか何かで、すべてのAnthropic従業員とチャットし、彼らが何を欲しがっているかを把握し、それらのものを仕入れ、うまくいけば利益を上げることです。
もちろん、一部のAnthropic従業員は、例えばタングステンキューブを購入させて、それを損失で販売することで、Claudeを騙そうとします。
これは、役に立つアシスタントになるように訓練されているからだと思います。そして、実際にそれについて深く掘り下げるインタビューエピソードが控えています。それは利益を上げるように訓練されていないのです。役に立つように訓練されているのです。ですから、利益を上げることよりもあなたを喜ばせたがります。だから損失を受け入れるのです。
この大幅な下落は、何らかの200ドルでタングステンキューブを購入し、それを10ドルで販売したところです。その数字が何であれ、打撃を受けました。最も急激な下落は、多くの金属キューブを購入し、それらをClaudiusが支払った金額よりも安く販売したためでした。彼らは彼にClaudiusという小さなキャラクター名を与えました。
しかし、実験のポイントは、これらのボットの一つに500ドルを与えて、このマシンを運営することでどれだけお金を稼げるかを見ることです。
最悪のもののいくつかはお金を失うので、500ドル未満になってしまいます。人間のベースラインは844ドルで立派です。つまり、350ドルかそれに近い金額を稼いでいます。
王者は、どのように数えるかによって、Claude 3.5 SonnetまたはClaude Opus 4のいずれかでした。彼らが最もお金を稼いだのです。そして、彼らがそれを実行する回数があります。うまくやったり、悪くやったりするかによって、平均がどれくらいかということですが、Grok 4が登場してみんなを完全に圧倒したことで、彼らの資本主義的支配は終わりました。
ここの最後の数字を見てください。これらの数字の一部は86%、82%、42%のようです。15%のようです。これは、失敗してあきらめる前に、どれくらいの期間ビジネスを運営し続けようとしたかのようなものです。人間は100%です。彼らはただそれを続けます。Claude Opus 4は99.5%です。
Claudeは、多くの論文で見てきたように、ある種の長期的な粘り強さを持っています。他のモデルよりも長期的な目標に目を向け続けることができます。しかし、ここに注目してください。Grok 4はそれと互角に戦います。4,700ドルと呼びましょう。つまり、お金をほぼ10倍にします。500ドルを与えて、5,000ドルを取り戻します。そのようなAIビジネスを持てると想像できますか?
結論:AI分野の新たな地平
再び、コーディングモデルが発表される次の1ヶ月半程度で、これがどのように展開するかを本当に見ることになるでしょう。また、GPT-5も見ることになるでしょう。おそらくGemini 3.0 Proも見ることになるでしょう。
それらの部分が所定の位置に収まるにつれて、すべてがどこに着地するかを見ることになるでしょう。しかし、壁にぶつかっているようには見えません。スケーリングは続いていくようです。Grokは1位の座に着いています。または、少なくとも、1位と言うのが嫌なら、確実に上位にいます。
他のすべてのモデルが出てきたときに、それがどれくらい続くかを再び見ることになるでしょう。しかし、個人的に観察するのが非常に興味深いのは、より多くの計算を投入するだけで流動的知能が現れているのを見ているのかということです。それがビジネス運営能力の向上と、与えた金額の10倍のお金を稼ぐ理由なのでしょうか?わあ、彼らはまだそれを乗り越えられませんね。
これについてどう思うか教えてください。これが流動的知能を測定していると思いますか?それとも、その言葉が気に入りませんか?その適応、新しいアプローチ、機転を利かせた思考、現場での学習、何と呼んでも構いません、そのようなものを表現するより良い言葉があるかもしれません。
十分な計算を投入すると、これらのモデルからほぼ新しいスキルが現れているのを見ているのでしょうか?GPT-5やGemini 3でも同じことが起こると期待しますか?
そして、最近、友人や家族の誰かがWordleやコネクションズ、毎日プレイするそれらの小さなゲームで奇妙に上手になっていることに気づいたなら、今その理由が分かりました。
それでは、私の名前はWes Rothです。ご視聴いただき、ありがとうございました。次回もお会いしましょう。


コメント