本動画は、大規模言語モデル(LLM)が多言語自然言語処理の問題を解決したのか、それとも問題を再定義したのかについて論じる技術講演である。ChatGPTの急速な普及から始まり、GPT-4oやo1といった推論モデルの登場、そしてDeepSeekのような新興モデルの台頭まで、AI分野の最新動向を包括的に解説している。特に推論モデルの仕組みやその限界、さらにはスロバキア語のような少数言語におけるNLP研究の現状と課題についても詳細に触れている。
導入と現状認識
皆さん、お越しいただきありがとうございます。私の名前はマレクです。何らかの理由で今日このお話をすることになりました。昨年は多言語自然言語処理について、GPTやその他のモデルがあるので解決されたのかという話をしました。今年は、この1年間に何が起こったのかについて、ある種の復習をしてみようと思い、私たちの研究の一部もお見せできればと思います。
始める前に申し上げておきたいのは、このような場所に招待されると、こんなメールが来るということです。最初の10分間はモチベーショナルで、誰もが理解できるものにすべきで、その後の7分間で接続を試み、90秒のモチベーショナルな内容があります。それから大多数の人が理解できる10分間があり、最後の15分間は私が話したいことを話すという構成になっています。この構造に従おうと思います。まだ120枚のスライドが残っているので、どうなるか見てみましょう。
私について少しお話しします。多くの方は以前に私を見たことがあるかもしれませんが、そうでない場合のために説明します。私はSlido(スライドー)というオーディエンス・インタラクション・プラットフォームで働いており、今日もそれを使う予定です。また、ここで教えており、子供たちや大学教授がロボットでサッカーをするRoboCupというイベントも部分的に主催しています。
しかし、過去3年間、私は基本的にこの分野の占い師のような存在でした。昨年の私の話は、ChatGPTが100万ユーザーに到達したのが奇妙だったということから始まりました。さらに奇妙だったのは、1億ユーザーに到達するまでわずか5ヶ月しかかからなかったことです。
ChatGPTの急速な成長
現在は2025年2月で、オープンソースの情報によると、ChatGPTは基本的に4倍の成長を遂げています。興味深いのは、なぜそうなったのかということです。大規模な、あるいは業界規模での効果的な利用ができることが理由の一つかもしれません。
その一部は、検索機能を開始したことにあるかもしれません。ChatGPTで何かを検索すると、それを検索して一貫した答えを返してくれます。しかし、オープンな数字を見ると、ChatGPTを通じて行われる検索の量はまだ比較的少ないことがわかります。
この図が気に入っている理由は、DuckDuckGoが含まれていることです。私はそこで6年間働いていました。DuckDuckGoが1日1億回クエリされるレベルに達するまで12〜14年かかりました。ChatGPTはまだ数年の段階ですが、ご覧のように、Googleのクエリが圧倒的に多いので、検索が理由ではないでしょう。
AIモデルの発展
それが理由でないなら、他の何かでなければなりません。アンダーソン・ホロウィッツという大手ベンチャーキャピタルファームがこの分野の分析を行っており、彼らの考えでは、2022年11月にChatGPTが初めてローンチされ、2023年2月頃にGPT-4がローンチされた後、月間アクティブユーザー数は少しプラトーに達したとしています。
6月、7月、8月にかなりの落ち込みが見られますが、これは学生層がこれを頻繁に使用していることを示しています。興味深いのは、2024年4月に何かが起こったことです。ちょうど私たちが昨年これについて議論した頃です。その後、高度な音声モードのロールアウトなどがありましたが、時間がないのでそれは省略します。
しかし、確実に議論したいのはo1というもので、これが過去数ヶ月のChatGPTの成長を推進したようです。
GPT-4oとマルチモーダル機能
GPT-4oについて聞いたことがあるでしょうか。時間がもっとあればよいのですが、簡単に言うと、これはオムニモデルになろうとしています。以前のGPTモデルはテキストまたはテキストのトークン化された表現のみを入力として受け取っていましたが、GPT-4oはあらゆるものの表現を入力として受け取り、最終的にあらゆるモダリティを出力として出力することを想定しています。
何に使えるかというと、例えば私が6年間使っているヘッドショット写真を、簡単にカートゥーンに変換したり、3Dカートゥーンにしたりできます。妻はこれをあまり気に入っていませんが。様々な興味深いスタイルも可能で、人形劇スタイルやウォレスとグルミット風、さらにはレゴスタイルも作れます。これは私の甥が最も気に入っているスタイルです。
注目すべきは、Slidoの部分まで概説されていることです。フォントフェイスまで正確に再現されており、これは非常に優秀です。拡散モデルで同じことを試してみてください。これは自己回帰的なようなので、注目を集める可能性のあるユーザーポテンシャルがあるようです。
推論モデルの台頭
私のより大きなポイントは、興味深く見えるかもしれませんが、これまで不可能だったことが今可能になったように見えるかもしれませんが、実際は全く逆だということです。昨年と同じリストを作ろうとしています。ニューラルネットワークによる逐次処理の現在の最前線に先立って起こった事柄のリストです。これは以前はニューラルネットワークと呼ばれていましたが、AIという大きな用語にまとめられました。
今年の興味深い点は、昨年を2つのカテゴリーに分ける必要があることです。GPT-4o部分と、それから推論モデルについてもう少し詳しく話します。おそらく推論モデルの黄金時代に入っていくのではないでしょうか。
推論モデルの仕組み
昨年議論したように、基本的にこれらのモデルへの質問の仕方を知ることが、その価値の多くを占めています。ゲームの名前は「私の訓練セットに何があったかを推測する」ことです。なぜなら、これらのことについて、ブログの周りの実際の冗談は、テストセットで訓練するだけでよいということだからです。その意味で、モデルから何らかの興味深い方法でテストセットを取得する方法を知っていれば、それが本当に必要なことなのです。
標準的なプロンプトは、質問をして正しく答えることを期待するものです。そして多くの問題が生じます。思考の連鎖アプローチでは、推論がある場合、モデルに例として提供すると、この推論を行うことが意味があることを簡単に理解します。つまり、「問題について何を知っているか」や「それをまとめようとする」などを出力し、その過程でより良い答えに到達するということです。
これは確実に役立つことがわかっています。これを半自動で行うことができます。モデルに独自に推論ステップを出力するようプロンプトし、問題を解決するのに関連すると思われることを出力させ、したがって答えを提供するようにします。
昨年議論したのは、何を求めるかが重要だということです。「段階的に考えてみましょう」は最も有名なものの一つでした。昨年、「深呼吸をして、問題に段階的に取り組みましょう」の方がさらに良いことがわかりました。しかし、それが今日の話題ではありません。
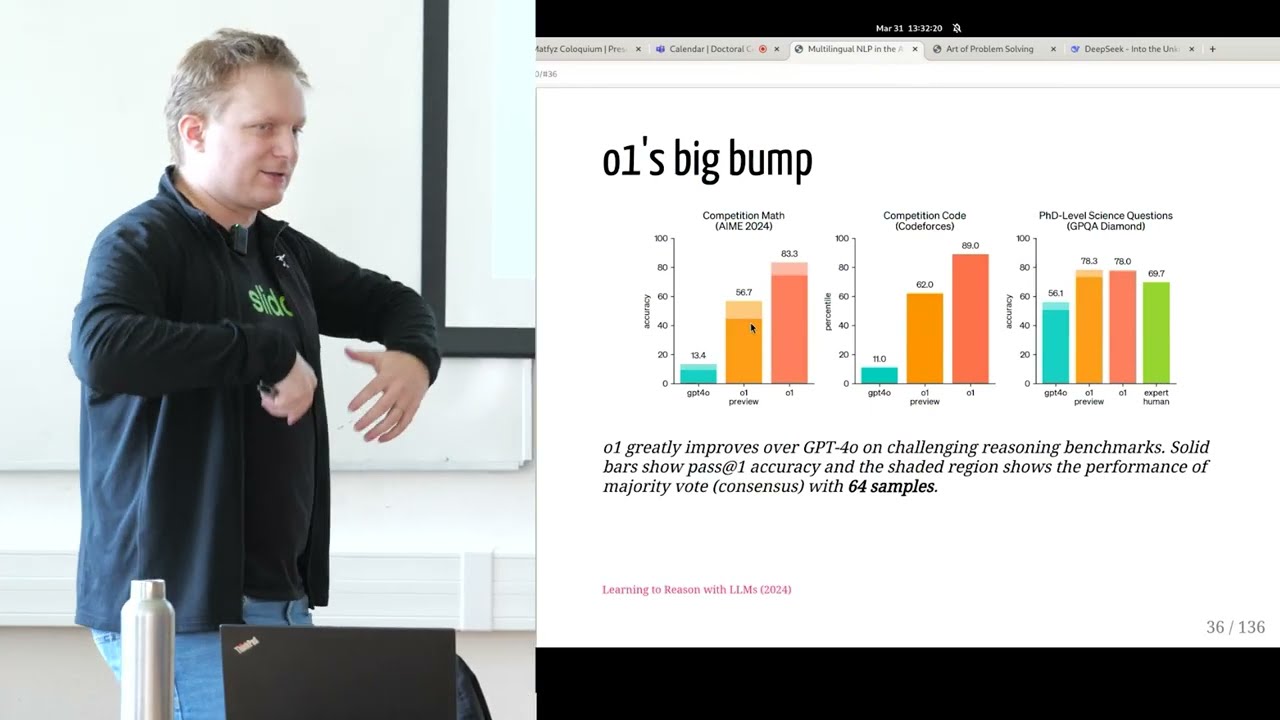
o1モデルの登場と性能
今日の話題は、OpenAIが昨年9月にリリースしたo1です。GPT-4oは興味深い複雑な質問をすることで簡単にプロンプトできるモデルです。しかし、o1モデルは、このような問題やタスクで完全に圧倒しました。つまり、大幅に、大幅に優れているということです。コードスタイルの問題や自然科学の問題でも同様です。
これらのことがどのように機能するかを概念的に視覚化する方法を考えていました。実際にはわかりませんが、少なくとも概念的に理解する方法です。興味深いことの一つは、IMO競技を詳しく見ることです。IMO競技は、アメリカの友人たちが国際数学オリンピックの代表を選ぶために使用するものです。
この種の考え方は、これらは博士レベルの学生にとって比較的簡単であるべきタスクだということです。高校生にとっては比較的挑戦的ですが、解決可能であるべきです。同時に、答えは常に0から1,000までの間(両端を含む)なので、比較的良い方法で解決可能性を確保できます。
数学問題の例と推論
以下はこれらのタスクに含まれる問題の一例です。「xとyが両方とも1より大きい実数で、log_x(y^x) = log_y(x^(4y)) = 10 のとき、x×yを求めよ」といった問題です。
このような問題では、解答が概説するように、おそらく第一原理から推論し、この種の問題を解決するために使用できる対数の属性を試すでしょう。このウェブサイトには、おそらく関連する6つか8つの解答が直接掲載されています。
このような推論を行うよう訓練されたモデルが何を教えてくれるか見てみましょう。残念ながら時間がありませんが、より大きなポイントは、これらのモデルがGPT-4oからo1レベルにジャンプする方法は、段階的に考えるようプロンプトされることなく、この複雑な「深呼吸して」などに誘導されることなく、推論の多くを効果的に独自に概説することによってです。彼らはまっすぐに考えるでしょう。
そして、私たちが呼ぶところの思考を少し行った後でのみ、実際に答えを得るでしょう。ここでの問題は、彼らが報告するこれらの陰影のある領域が、64サンプルでの多数決のコンセンサスのパフォーマンスだということです。64サンプルを取ると、実際には言語モデルは必要ないと思います。
これが基本的に行うことは、ランダムな選択で、全体の80%を獲得することです。私がここで言おうとしているのは、これらは0から1,000の数字を推測しなければならないのに対し、ここでは4つから8つの選択肢の一つだということです。言い換えれば、十分な回数試行し、多数決を取れば、純粋な偶然によっていつかは勝つということです。
推論モデルの実装
とはいえ、何かがあります。主に推論モデルの動作方法が、出力でより多くのトークンを持つほど、単一パスでもより高い精度を得られるようだからです。言い換えれば、モデルにより大きな計算量と訓練を与える、つまり基本的にインターネット全体を見て、それを利用できるので、より長く訓練できるなら、それは少し役立ちます。しかし、大幅に役立つのは、テスト時にモデルをより長く、より長く考えさせることです。これは比較的重要になるでしょう。
どのようにしてそのようなことを実現するのでしょうか。誰も知りません。OpenAIはもはやオープンではありませんし、それが本当にAIかどうかもわかりません。しかし、確実にそれを成し遂げたいという欲求があります。実は、DeepSeekという場所から、非常に予想外の場所から、ある種の再現が来ることがわかります。
DeepSeekの登場とo3の発表
それを行う前に、OpenAIが9月にo1をリリースしたが、12月にo3という別のリリースがあったことを強調したいと思います。それでは、観客との交流会社で働いているので、交流が必要です。スライドー.comをデバイスに入力して、クイズを行いましょう。
参加を促すために、3冊の本を用意しています。「The Little Book of Deep Learning」、「Why Greatness Cannot Be Planned」(強化学習の結果で人生にも適用可能な非常に良い本です)、または「Turn the Ship Around」という最高のリーダーシップ本です。これらのうち1冊があなたのものになります。
最初の質問です。o1の次のOpenAIモデルがo2ではなくo3と呼ばれたのはなぜでしょうか?実際にo3と呼ばれました。
正解は、o2は既に商標登録されていたからです。OpenAIは数千億ドルの大きな提案をしても、電話会社の複合企業を買収することを望まなかったようで、o3をリリースしました。これはo1とそれほど大きく異なるモデルではありませんが、蒸留のようです。
12月20日にo3がリリースされ、12月25日にDeepSeekが登場します。DeepSeekは何でもないように見えて、実際には多くのベンチマークで非常に良い数字を出しています。6350億パラメータのモデルで、リードミーもほとんどなくHugging Faceにリリースされました。基本的には重みだけですが、非常によく機能します。Mixture of Expertsモデルなどです。
さらに興味深いのは、1月20日に起こったことです。1ヶ月も経たないうちに、DeepSeekがR1をリリースしました。これははるかに小さなモデルですが、少なくとも同等の能力があり、場合によってはそれ以上です。
DeepSeekの市場への影響
それが行ったことの一つは、1月25日金曜日(リリース後の時間または既に土曜日)のNvidiaの株価でした。月曜日にはこのような株価の様子でした。これが時価総額の下落です。6000億ドルです。これはGDPでスロバキア3つ分だと思います。
次の質問は、DeepSeek R1のようなものを開発する推定総コストはいくらかということです。より大きなモデルのコストの95%削減について見出しを見たことがあるかもしれません。
業界アナリストが論文と論文で概説されたGPU時間数から、実際には最先端モデルであり実際に論文を持っている(これは確実に過去1年間の新しいことです)、市場でのレンタルコストを計算すると、約600万ドルでした。しかし、それは最終的な微調整のみであることがわかりました。総コストは非常に高い可能性があります。16億ドルを選んだ人は、少なくとも私と同意見でしょう。
DeepSeekの技術的詳細
論文自体は読む価値のある興味深いものです。o1の性能に非常に近づく方法を示しています。これらが何をするかは、思考トークンを出力することです。通常、このような質問をすると、文字通り自分自身に考えているように見えます。「では、積を見つける必要がある」から始まり、「これらの性質を適用できる」、「これらの性質を使って方程式を簡略化できるかもしれない」などと続きます。
これは、賢明でない人が実際に内部モノローグを行っているかのようです。多くの人が実装方法を尋ねました。お見せしましょう。絶対に簡単です。文字通りプロンプトの一部です。「推論プロセスと答えは、それぞれthinkとend think、answerとend answerタグ内に囲まれます。think:推論プロセスここ、answer:答えここ」ありがとうございます。それが問題です。
ある意味では、これはせいぜいハックであり、それより悪いかもしれません。実際に興味深いのは、それに対する強化学習の方法です。彼らが使用する精度報酬は、効果的に、すべてのテストケースに合格するまで、コーディング問題を完全に解決したかどうかです。
強化学習とグループ最適化
言い換えれば、現在のソリューションの価値を誰かが評価する方法という標準的な問題は、評価するすべてのテストケースがあるため、ほとんど解決されます。言い換えれば、この種の推論は、コーディングタスクを解決するよう最適化することによって、モデルに誘導できるということです。
訓練中の様子は以下のようになります。本当にo1の壁を破ることができ、これがその論文の最も重要なミームです。彼らが訓練してきたバージョンの「ああ」の瞬間を示しています。問題を解決し始め、「内側の平方根項を分離するために並べ替える」などと進み、考えて考えて、そして「待って待って待って待って」と言います。それは私がここでフラグを立てられる「ああ」の瞬間です。
これが私たちが得ているものです。皆さん、私たちはモデルに「ああ」の瞬間を持ってもらうことを期待しています。その意味で、以前に理解していたと思っていたなら、私たちはますます理解しなくなっています。しかし、これらのようなことで、私たちがグループで全体的に行うところでは、実際の強化学習方法はGPOと呼ばれています。彼らはこれをグループで行い、非常に小さなモデルでも実際に機能するようです。自分で試すことができます。
しかし、私たちがこの「待って待って待って」の領域に終わることは興味深いです。この種のことには、待つことが重要になります。
思考トークンとスケーリング
DeepSeekは興味深いですが、少なくともバニラ版では、OpenAIが持っていたこれらのことを再現できません。より多くの思考トークンを与えるほど、より良い思考プロセス、つまりあるタスクでのより高いパフォーマンスが得られます。そのためには、現在スタンフォードにいるニコラスによる非常にシンプルで素晴らしい論文が必要です。
これを示す唯一の理由は、この種の分野での最先端がどのようなものかということです。最先端は次のようになります。OpenAIは線形にスケールできるようですが、オープンウェイトは線形にスケールしていないようです。私たちも線形にスケールできるように、ハックを1つか2つまとめることはできるでしょうか?明らかにできます。だからこそこれは誘導質問なのです。
言語モデルの基本原理
そのためには、過去に議論したいくつかの背景を素早く通過する必要があります。絶対的に高いレベルでは、この全体の言語モデルというものは、効果的にインターネット全体で訓練されたオートコンプリートです。そして興味深いことは、次の単語をどのように選ぶかです。言語モデルは何らかの方法でその選択をしなければなりません。
複数の方法があり、一部は非常に退屈で、一部はやや良く、通常使用される最良のものはnucleus samplingと呼ばれ、トークンの確率の狭い分布と非常に広い分布の両方があるという事実のバランスを取ろうとします。
これを行うとき、ある時点でこの思考プロセスを終了し、この全体の思考は、実際にはどのくらい時間がかかるかを制御しません。ここで見ているのは、例えばGoogleの別の非常に強力なモデルであるGeminiが取るトークン数です。Geminiは三浦ワルコが取り組んでいるモデルの一つです。
Geminiは答えを出力するために使用するトークン数を圧縮しようとする傾向がありますが、このDeepSeek R1モデルは、この種の内部モノローグ議論を行うために、簡単に喜んで長い長い長さまで行きます。利用可能なトークン数でスケールしようとしている場合、これは重要になります。
バジェットフォーシング技術
実際に興味深いハックは次のとおりです。「ラズベリーにはいくつのrがありますか」のような質問を受けると、これがモデルが答えるであろうものです。「はい、単語ごとに進んで数えてみます」といった具合に。
サンプリングメカニズムは、モデルウェイトにアクセスできる場合、私たち自身が選択するものです。言い換えれば、モデルが基本的に「完了した」と言うどこかに到達できる場合、彼らがバジェットフォーシングと呼ぶことを行うことができます。これは、「答えの終わり」と言う代わりに、そのトークンを完全に削除し、「待って」を行い、さらに考えさせることです。
言い換えれば、これが行うことは、まだ利用できるトークンがある場合はいつでも、モデルにこれらのより多くの出力を強制し、最良を期待することです。実際に最良は比較的大幅に役立ちます。ご覧のように、o1モデルは、どれだけの例で訓練されたかわからないが、効果的に、これらの小さなモデルとタスクによっては同等です。これらは非常に特定の例の1000個で訓練されており、このバジェットフォーシングを使用して、非常に類似したパフォーマンスを再現できます。
最終的な評価
全体として、この種の推論は確実に役立つようです。この部分を終えるために、クイズの最後の質問があります。最後の質問は、一体どうしてこのDeepSeekがこれらの大規模ラボを資金調達の面で打ち負かすことができたのかということです。
実は、ヘッジファンドが実際にこのDeepSeekモデルを行った会社の親会社だったことがわかりました。私の個人的な見解では、もしヘッジファンドで、株式市場でお金を稼ぐ方法を知っているなら、このようなモデルを持っていたら最初にすることはNvidiaをショートすることでしょう。もしかしたら、それが彼らがしたことかもしれません。
多言語NLPの現状と課題
マーティン・H、おめでとうございます。後で本を選んでください。これで終わらせようと思います。7分で70枚のスライドがあるようですから。
それで、インターメディアを行おうと思っていましたが、それはスキップして、私たちが取り組んできた新しい研究をいくつかお見せしようと思います。ここで言おうとしていたことの多くは、既に公開されているか、間もなく公開される予定です。
過去の多言語NLP、特にスロバキア語での大きな問題の一つは、スロバキア語が大きなベンチマークの一部になったことがなかったことです。様々な理由で完全に無視されていました。チェコ語に非常に近いというのは理解できる理由ですが、より重要なのは、利用できるデータセットがあまりなかったことです。
新しいベンチマークとデータセット
幸い、これは変わりつつあります。例の一つはMTEBマッシブ多言語テキスト埋め込みベンチマークで、スロバキア語がいくつかのタスクで含まれました。私は偶然にも著者リストに載ることになりました。これは同じ会議に受け入れられました。ババ博士と将来のマツコ博士の論文も受け入れられました。70人中の1人なので、ここで功績を主張しようとしているわけではありませんが、これが起こったのは比較的大きなことだと言えます。
そこからの単一の結果として、多言語の場合、訓練する多くの言語がある場合、500パラメータ程度の小さなモデルでも、同じタスクで70億パラメータのモデルを打ち負かすことができることがわかりました。この種の大きなベンチマークが起こらなければ、この種の結果を得ることは不可能でした。
現在査読中で、リバッタルゲームをうまくプレイできればACL会議にも受け入れられるかもしれない別のものは、CLaPS:スロバキア語一般言語理解ベンチマークです。これは、スロバキア語を私たちの周りの言語と同等にしようとする私たちの試みです。特にエンコーダーモデルが、どの程度それを行うかを自動的にテストできるようにするためです。
翻訳とモデル評価
私たちはかなりの数のデータセットを収集しました。標準的な9つです。これは標準的なGLUEベンチマークに似ています。これらのいくつかは自分たちで再作成する必要があり、いくつかは翻訳する必要がありました。翻訳が必要なものについては、翻訳研究を行いました。これは、スロバキア語テキストの非常に正確な翻訳が必要な場合に取り上げることができるものです。
英語からスロバキア語への非常に正確な翻訳について、市場で見つけた最良のものはDeepLですが、「これをスロバキア語に翻訳してください」という非常にシンプルなプロンプトを使ったGPT-4oも同様によく機能し、価格は10分の1です。ですから、ぜひ試してみることをお勧めします。
これらすべてで14のモデルをベンチマークしました。非常に大規模なハイパーパラメータスイープが行われました。残念ながら、全体的に示されたのは、現在4年経っているスロバキア語と比較して、ある程度大幅に優れているモデルはXLM-Rの大型版のみだということです。ここではサイズが役立ったようです。
相対的改善を見ると、mDeBERTa(Microsoftモデルの最新多言語版)は絶対値では72.6でかなりよく機能しますが、まだ大幅な改善の余地があります。
まとめと今後の展望
要約として、私たちはまだ完了には程遠い状況です。スロバキア語のような言語にとって状況は幸い変化しています。多くの興味深いことが結集していますが、インターネット以外では、データが依然として制限要因です。インターネットデータを使い果たしたと思うので、他の場所を探さなければなりません。次回お話しするときには、提示するモデルがいくつかあることを願っています。
ということで、エネルギー、時間、選択肢、すべてを使い果たしたと思います。次のアジェンダは3分後の学科会議だと思います。時間を割いていただき、再度ありがとうございました。


コメント