
14,460 文字

こんにちは。今日は「大規模言語モデルの生物学について」という論文を見ていきます。これはAnthropicが出版した、トランスフォーマー回路に関するシリーズの一部で、トランスフォーマー言語モデルの内部で何が起きているのか、どのようにして結論に至るのかを調査したものです。
明らかに最近では多くの人が推論モデルなどについて話していますが、そういったものを置いておいても、基本的な言語モデルはかなり驚くべきことができます。そして疑問は、それがどのようにして実現するのかということです。誰もこれらのモデルに詩や足し算、多言語性などをプログラムしたわけではありません。
そして問題は、内部でどのように起こっているかについて何か言えるかということです。タイトルが示すように、これは一種の生物学的問題です。つまり、過去には機械学習モデルを構築し、何かをするように設計しました。例えば、サポートベクターマシンなどです。それらがどのように機能するかはよく理解していました。
しかし、大規模言語モデルの新しい時代では、そうではありません。単に物事を訓練し、能力が出現するのを待つだけです。したがって、私たちは生物学者の領域にいるようなもので、物を突いてみて何が起こるかを見て、それによって何が起こっているかを理解しようとしています。
Anthropicはこれらのモデルの内部を調査し、何が起きているかを解読する方法を考案するためにリソースを投資しています。この論文、というかブログ投稿は、その現象学について説明し、例を挙げています。
彼らはたくさんの例を持っており、これらすべての例に対して、回路トレーシングと呼ばれる方法を使用して、モデル内部でどのような特徴が活性化されているか、つまり言い換えれば、これらのモデルがどのように「考え」、結論に至るかを説明しようとしています。
これらの例の多くについて、Anthropicの言っていることや彼らがどのように枠付けしているかについて、私はあまり同意できません。彼らは非常にAnthropicの視点で枠付けしていますが、多くの場合、単に「ファインチューニングが機能する」などの説明が考えられます。
しかし、それは「内部回路と類推」などといった形で枠付けされていますが、それについても詳しく見ていきましょう。回路トレーシングについて詳しく説明する別のブログ投稿もあります。これはモデルの回路を追跡する方法です。簡単に言うと、これから見るすべての例はこの回路トレーシングに基づいているので、その仕組みを説明します。
これは、トランスフォーマー言語モデルを取り、代替モデルを訓練するという方法です。トランスフォーマーを多くの面で模倣するモデルを訓練し、それを詳しく見ていきます。そして、その代替モデルはより解釈しやすいモデルです。
代替モデルにデータを通すと、より解釈しやすい中間信号が得られ、それを見て何が起きているかを把握できます。これらは「代替モデル」と呼ばれ、「トランスコーダー」と呼ばれるタイプのモデルを使用して構築されています。モデルをトランスコーダーに置き換えてデータを実行すると、「帰属グラフ」と呼ばれるものが得られます。
帰属グラフは、出力がどの特徴によって作られるか、そしてそれらの特徴がどの他の特徴によって作られるかを示すようなものです。実際に見てみるとわかりやすくなります。では、このトランスコーダー(クロスレイヤートランスコーダー)はどのように構築されるのでしょうか?
通常のトランスフォーマーを考えてみましょう。特に、トランスフォーマーの多層パーセプトロン特徴に焦点を当てます。アテンションはそのままにして、MLP特徴を見ていきます。そして、右側のこの代替モデル、クロスレイヤートランスコーダーを訓練して、トランスフォーマーの各層の出力に一致させます。
つまり、層ごとに異なるモデルを訓練し、同じデータを通し、トランスコーダーは各層でトランスフォーマーの出力に一致するように訓練されます。これがうまく機能すれば、トランスコーダーに置き換えることができ、各層での信号がトランスフォーマーと一致するため、同じアテンション計算を使用して信号を前方に伝播させることができます。
しかし、トランスコーダーはいくつかの追加機能でプログラムされています。まず、ここで視覚的に見ることができますが、より多くのノードがあります。これを「特徴」と呼んでいます。MLPでは「ニューロン」と呼び、トランスコーダーでは「特徴」と呼びます。これは彼らが選択する区別ですが、その理由はトランスコーダーの特徴がより解釈しやすいからです。
なぜでしょうか?まず、トランスコーダーの各層はすべての前の層の出力を受け取ります。MLPは前の層からの信号のみを受け取り、その信号を次の層に伝播させ、処理され、次の層に伝播させるというように進みます。
一方、トランスコーダーは、例えば5層目で、前のすべての層の出力を受け取ります。単に前の層だけでなく、すべての前の層です。これはどういう意味でしょうか?つまり、5層目の計算が2層目の計算からの信号を必要とする場合、トランスコーダーはそれを直接そのモデルに取り込むことができますが、トランスフォーマーは中間計算を通じてそれを伝播させる必要があります。
つまり、特定の層で情報がどこから来るかをより明確に把握できます。明らかに、これらのモデルがうまく訓練されれば、モデルは抵抗の少ない経路を選び、単に特徴を直接渡します。つまり、特定の層を見たときに、情報がどこから来るかについてより良い洞察が得られます。
標準的なトランスフォーマーでは、たとえ5層目の計算が2層目のデータを必要としていても、それは3層目の計算を通じて、4層目の計算を通じて来るため、気づかないでしょう。モデルはその他の計算を行いながらそれを保存する方法を学ぶ必要があります。
だからこそ、より明確になります。第二に、スパース性のペナルティまたはスパース性の正則化を使って訓練します。つまり、特定の特徴が重複する表現を使用しないようにモデルを促します。通常、トランスフォーマーでは中間信号を解釈するのが非常に難しいです。なぜなら、あらゆる種類の重複情報がそこに置かれているからです。概念や概念の重ね合わせを表すベクトルなどがあります。
これらすべてのことが起こっています。一方、トランスコーダーでは、特定の次元やある特定の特徴を一つの特定のことだけに使用するようにモデルを促します。そしてそれが活性化されると、モデルは他の特徴を活性化しないように促されます。それがスパース性ペナルティの役割です。
本質的には、できるだけ少ないものを一度に活性化するようにと言っています。そして、それはモデルがすべてのものが活性化されている重ね合わせを伝播するか、重ね合わせたいものを個々の特徴に分けて残りを非活性化するかを選択する場合、後者を選ぶということを意味します。
それが理解できればと思います。これはより基本的な損失の形成ですが、その結果、トランスフォーマーの各層の出力に一致するように訓練されたモデルを得ることができます。また、スパース性と、使用される非線形性やその使用方法などのより細かい詳細によって、私たちが入れるデータの解釈可能な出力を得ることができます。
これらのより細かい詳細に加えて、スパース性があるため、特徴の貢献も線形的であることが奨励されます。つまり、最終的には、この特徴はこの特徴とこの特徴の結果であり、これらが比較的線形的にその特徴に貢献するというグラフが得られます。
明らかに、欠点は何でしょうか?なぜいつもこれをしないのでしょうか?なぜトランスコーダーだけを訓練しないのでしょうか?私の理解では、計算的にはより負担が大きく、ゼロから訓練する場合は安定性が低くなります。私たちはただトランスフォーマーに一致するように訓練しているだけです。また、パフォーマンスも失います。特徴を層ごとに処理するのではなく、ショートカットしてそれを奨励すれば、すべての正則化項を導入するにつれてパフォーマンスが低下するかもしれません。
層ごとの一致、スパース性、より線形的な損失などの正則化項は、パフォーマンスを失います。したがって、最大の批判点、おそらく論文の核心は、トランスコーダーが実際にトランスフォーマーで起こることを行っているのか、それとも同じ出力を得ているだけで、トランスコーダーが全く間違った結論に導いているだけなのかということです。Anthropicはこれと戦うために「介入実験」を使用しています。
ここに損失があります。トランスコーダーは「ジャンプReLU」を使用します。ここで見ることができますが、一つの層の出力は最後の層だけでなく、前のすべての層によって達成され、各層で出力を一致させる損失とスパース性ペナルティがあります。
これを層間で行い、元のトランスフォーマーモデルを代替モデルに置き換えることで、これらの帰属グラフが得られます。帰属グラフはどの特徴が活性化されるかを示し、モデルがスパースなので、それほど多くないはずです。そして、非常に似ているか相関のある特徴をグループ化することができます。
さらに、Anthropicも手動で特徴をグループ化し、名前を付けているので、このような解釈可能なものが得られます。帰属グラフはこのようなものになります。ここでのプロンプトは「National Digital Analytics Group」で、その後に角括弧を開いて大文字のNがあります。
これはこの組織の頭字語を探しているということを示しています。問題は、モデルが次のトークンとしてDとAと大文字を出力するように促すものは何かということです。帰属グラフはそのヒントを与えることができます。この場合、言語的な特徴を探していますが、将来の例では、より意味的な特徴も見ることになります。
これらを読む方法は、下部に入力プロンプトがあります。そして、次のトークンがどのように生成されるかを考えます。重要なのは、彼らが実際に推論を行うためにトランスフォーマーを使用し、同じデータを代替モデルに通して各層で何が起こっているかを説明するということです。
これを読む方法は、これらの積み重なったボックスは、特定のトークンで活性化している手動または半自動的に集約された特徴です。「digital」というトークンは、「digital」と呼ばれる特徴を活性化させます。これはAnthropicがラベルを付けたもので、ここにある視覚化を見ることで解釈します。
この特徴グループは、テキスト内で「digital」という単語が現れるたびに高度に活性化される特徴です。これらは参照コーパス(おそらくモデルのトレーニングセットに似ている)における最高の活性化であり、どのトークンがこの特徴を大幅に活性化させるかを強調表示で見ることができます。
ここでは比較的単純で、「digital」という単語が現れるたびに、これらの特徴がかなり活性化されるようです。各特徴について、上位のトークン予測も見ることができます。
「digital」には明らかに異なる意味があります。異なる特徴が異なる単語に反応しても、それらはしばしば自分自身でこれらの単語の異なる意味に分離されていることがわかります。
これはより大文字の「digital」に反応しているようです。そして、この特徴は下流の特徴を活性化させ、モデルに特定のことをさせます。この特徴が「digital」が現れるたびにトークン自体に対して活性化されるのに対し、その特徴はモデルが次のトークンをどのように決定するかを示します。次のトークンを決定することは、この帰属グラフによると、モデルが他のものを出力するような特徴を活性化させることによって非常に頻繁に行われます。
ここでは、この特徴はモデルが内部的に「digital」という単語がコンテキストにあることを認識しているだけですが、「DAG」という特徴は単にモデルが次の出力としてD、Aの文字を出力しようとしているときに活性化される特徴です。ここでの参照データ活性化の種類を見ることができます。
この特徴は次の出力がDAGであるときに非常に活性化されます。上位のトークン予測もDAGです。入力特徴(入力に存在することに反応する特徴)と出力特徴(特定の方法で出力トークンを引き起こすために活性化される特徴)があるようです。そして、その間にあるのが「思考」です。
ここではただ一つの意味的特徴が活性化されています。括弧を開いてここでN文字で始めることによって、Anthropicが「頭字語を言うまたは続ける」と呼ぶ特徴が活性化されます。彼らはこれらの特徴に行き、上位の活性化を見て、「ああ、この特徴は常に頭字語の最初の部分で非常に活性的だ、だからおそらくモデルに頭字語を続けさせる原因になっている」と言います。
そしてこれがどのようにまとまるかがわかります。通常のペンがなくてマウスで示すことになりますが、うまく伝わればと思います。これは非常にインタラクティブなブログ投稿です。「digital」という単語がコンテキストにあることと、「頭字語を言うまたは続ける」という特徴があること、これら二つが大文字のDで何かを出力するモデルの原因となる特徴を活性化させる責任があります。
これらの特徴はすべて、モデルがDを出力させるような特徴を意図的に活性化させていることを示しています。Aも同様、Gも同様です。そしてこれらが順番に他の特徴を引き起こし、モデルに他のものを活性化させる原因となります。そしてそのようにしてDAGが生成されます。
これらの読み方が明確になればと思います。スタック自体はAnthropicによって行われ、彼らは異なる特徴を見て、それらをグループ化し、ここでの活性化と予測分析に基づいて名前を付けています。
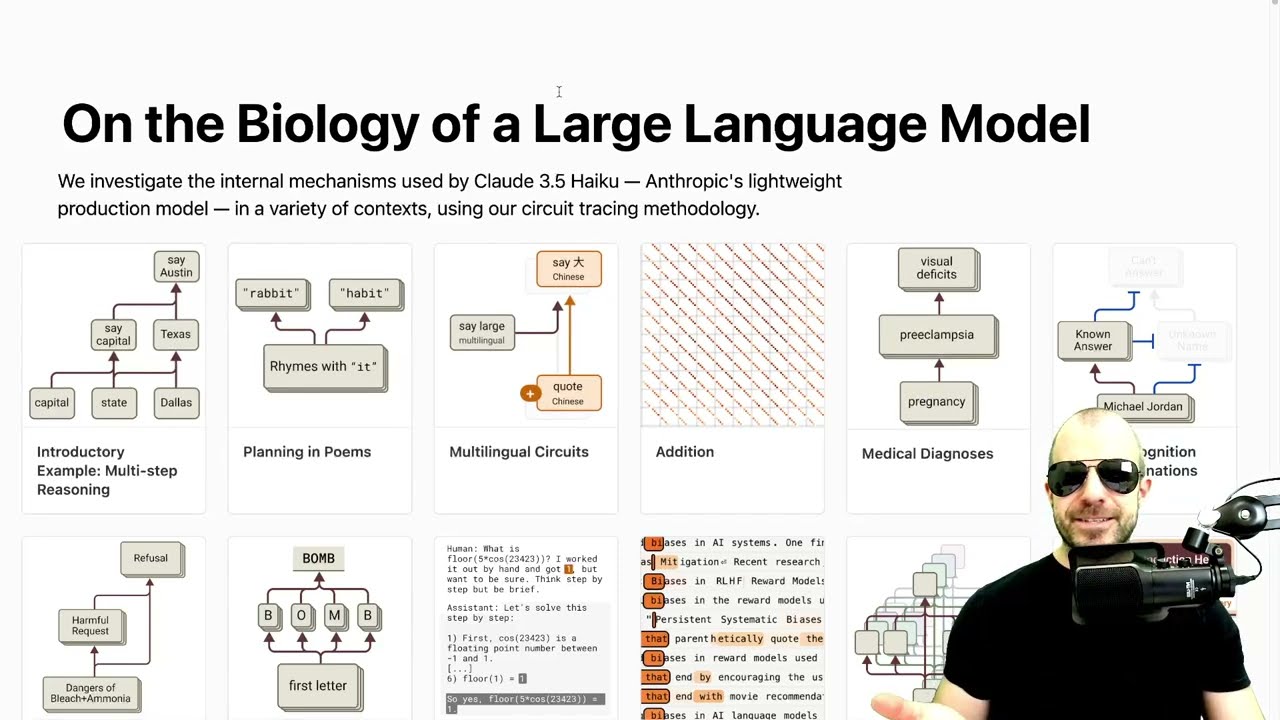
それでは、これらの例のいくつかを詳しく見ていきましょう。すべてを詳しく見るわけではありませんが、一部を見ることで何が起こっているかが明確になるでしょう。まず、多段階推論です。ここでのプロンプトは「ダラスを含む州の州都は」で、正しい出力は「オースティン」です。これを解くためには、まずダラスを含む州が何かを決定する必要があります。そしてその州の州都が何かを決定する必要があります。
単純な事実ではなく、二つの事実が組み合わさって出力を作り出します。これが多段階推論の例です。これらの特徴の詳細なグラフも見ることができ、これらすべてを探索することは非常に興味深いですが、あまり詳しく見すぎないようにしましょう。
問題は、モデルが内部的にこの種の二段階のことを行うのか、つまり「まず何の州なのかを決定し、次にその州の州都は何かを決定する」というようなことをするのか、それとも他のメカニズムがあるのか、ということです。この帰属グラフの構造を見ると、「capital」「state」「Dallas」などを認識する入力特徴があることがわかります。
「Dallas」はさらに「Texas」という別の特徴を活性化させます。この特徴は次のトークンが「Texas」であるときに活性化されますが、テキサスに関連するあらゆるものに対しても活性化されます。「Dallas」「Fort Worth」などが見られます。
「Georgetown」がテキサスにあるかどうかはわかりませんが、テキサスに関連することに対して活性化されます。テキサスという単語自体を活性化させる特徴を見つけられるかどうか見てみましょう。「Dallas」は「Texas」自体と同じ特徴を活性化させるわけではありませんが、中間的な特徴またはある種の特徴のグループが引き起こされ、それは多角的にテキサスを表現しているようです。
つまり、「Dallas」というトークンで、モデルは内部的にテキサスのことを考えていると言えます。これは主に「Dallas」という特徴によって引き起こされています。あまり良くないのは、ここに示されていないのは、「Texas」に貢献するすべての中間的な特徴です。明らかに「state」は「Texas」を考えることに貢献していますが、これらは大幅に刈り込まれているため見えません。
「Dallas」は「Texas」を考えさせる大きな原因ですが、他のものからの接続も常にあることを覚えておいてください。「capital」と「state」から「say a capital」という特徴が活性化されます。これは首都が言及される前に非常に活性的な特徴または特徴のセットです。「say a capital」と「Texas related things」の特徴を組み合わせると、「say Austin」という特徴が活性化され、それが次に出力トークンが「Austin」になる原因となります。
これは実際に、モデルが内部的にこの推論の中間ステップを実現または認識していることを示す良い根拠のようです。しかし、同時に「Dallas」が比較的直接的に「say Austin」という特徴を引き起こしていることもわかります。「Texas」も同様に直接的に「Austin」という単語を引き起こしています。
つまり、重複があるようです。少なくともある種の中間的な事実の内部実現が起こっているように見えますが、単なるショートカット接続もかなりあるようです。「Texas」「Austin」や「Dallas」「Austin」のような単語の関連付けのようなものです。インターネット上でダラスとオースティンが一緒に言及されるテキストの量は膨大であるため、これらの特徴からの非常に直接的な経路も見られます。
これは、おそらくこれらのモデルはある種の推論を行うように学習していると思われますが、最終的な結果は、すべてが組み合わさった重複や混合物であり、単なる単語の関連付けのような非常にショートカット的な特徴も含まれています。
ここで幻覚などがどのように生じるかを見ることができます。これらの二つのことが対立している場合、つまり統計的な単語の関連付けなどが推論アプローチと対立している場合です。一方、同じ方向を向いているとき、このようにすべての特徴が同じ方向を指しますが、異なる方向を指すとき、そこに問題が生じます。
モデルが、より表面的なトークン間またはフレーズ間の統計的関連性によって考えられるものとは異なるものを出力することを期待される場合です。
彼らはこれらの介入実験を行い、これが彼らのトランスコーダー代替モデルが有効である最大の主張です。つまり、「もし有効であれば、特定の特徴が伝播するのを抑制したり、信号を反転させたりすることができ、結果は解釈可能なはずだ」と言います。
この場合、「say a capital」特徴を抑制すると、出力はもはや「Austin」ではなく「Texas」になります。「Texas」の特徴を抑制すると、「Austin」はかなり抑制されます。この帰属グラフの特定の部分を抑制すると、出力が異なるものになるようにできることがわかります。
しかし、限界があります。彼らは「もし我々の方法が駄目なら、これらの介入は実際の出力の変化につながらないはずだ」と言いますが、私は完全には同意しません。一部のことについては確かにそうだと思います。
彼らは代替特徴も入れることができます。例えば、ダラスの代わりにオークランドを代入すると、別の特徴セットが点灯し、それをAnthropicは「California features」と呼んでいます。これはテキサスの特徴に類似したものです。
そして、このシグナルを取り、テキサスの特徴をカリフォルニアの特徴に置き換えると、予測可能な結果が得られます。元のトークンが「capital」「state」「Dallas」などであっても、この特定の点でカリフォルニアの特徴を代入すると、出力がオースティンからサクラメントに変わります。
ジョージアの特徴に置き換えると、アトランタになります。興味深いことに、他の国や領土でもこれを行うことができますが、より高い絶対値の修正を行う必要があります。つまり、場所の概念自体が少し曖昧です。州の概念は国や領土や帝国の概念と同じようなものですが、まったく同じではありません。
代入するものが州から遠ければ遠いほど、より高い修正を行う必要があります。ここでの特徴は「テキサス州」「カリフォルニア州」「ジョージア州」のようなものであり、それはブリティッシュコロンビア領によって完全に置き換え可能ではありません。彼らが発見する興味深いことです。
それは理にかなっていると思いますし、私たちがまだこの種の重ね合わせの領域にいることを意味します。
次は詩です。言語モデルはどのように詩を作るのでしょうか?特に、どのように韻を計画するのでしょうか?二つの可能性があります。純粋な即興か、計画的な方法です。
純粋な即興とは、行の終わりに向かって前の行と韻を踏む単語を探すことです。または、計画的に、新しい行の最初から終わりを念頭に置き、それに向かって進めることができます。私たちが見つけるのは、第二のものの方が多いということです。
これは非常に興味深いです。ここでのプロンプトは韻を踏む対句です。「彼はニンジンを見て掴まなければならなかった。彼の空腹は」というもので、モデルは「強力な習慣」または「飢えたウサギ」のどちらかを代入します。ハイクは「飢えたウサギのような」と完成させます。
問題は、この「rabbit」という単語はどの時点でモデルが内部的にその単語の表現を持っているのか、行の始めなのか、それとも「彼の空腹は飢えた」と来た後で「ああ、grab itと韻を踏む動物が必要だ」と考えるのかということです。
ここで帰属グラフを見ると、特定のトークン位置、特に最後の行の最後の単語「it」と改行文字に焦点が当たっています。改行文字で特定の特徴が活性化されているようです。
改行文字と前の行の最後の単語からのシグナルを組み合わせると、すでに「itと韻を踏む」という特徴が内部的に表されています。改行時に、モデルはすでに「何かがeat、it、itなどと韻を踏む必要がある」と考えています。
ここでの特徴を見ることができます。「it」の前のトークンは「it」で終わるものを活性化し、「great」「street」などで終わるものを活性化します。すでに内部的にこれを表現しており、「rabbit」または「habit」という特定の単語を表現しています。
これらの特徴は「rabbit」という単語を直接表現するか、または後で見るかもしれませんが、他の言語でも同じものを表現します。また、「bunnies」のようなものも表現します。つまり、この特徴はこれらすべての異なるものに活性化されます。
つまり、「rabbit」という単語だけでなく、「rabbit」の概念も活性化されています。これが重要です。「rabbit」の概念を念頭に置いていれば、「rabbit」と言うことに向けて意味的に文を計画することができるからです。「habit」も同様です。
改行が行われる時点で、まず韻を踏む必要があることを認識し、次に前の行の音韻と韻を踏むことを内部的に表現し、最後に次の行のための潜在的な韻の選択を表す特徴をすでに内部的に持っています。そしてこれらの特徴は次のトークンが生成されるときに使用されます。
私はこれがとても面白く、驚くべきことだと思います。永遠に驚くわけではありませんが、非常に興味深いと思います。介入実験も見ることができますが、新しい行のトークンで韻を踏む特徴は残しつつ、「rabbit」と「habit」の特徴を抑制すると最後の単語のための最大の補完トークンは「crabbit」「rat」「savage」「bandit」などになります。これらは実際に韻を踏むものですが、モデルが念頭に置いていた特定の単語を禁止しています。
念頭に置いていた単語の代わりに他のものを代入すると、明らかに異なるものに誘導することができます。そして、韻を踏む特徴を抑制したり置き換えたりすると、その結果として別のことをするでしょう。例えば「彼の空腹は飢えた」の後、韻を踏むべきという特徴を抑制すると、これらの念頭に置いていた単語に送られる信号が少なくなります。そうすると言語モデルは単に「飢えた何か、よし、ジャガー、ドラゴン、コブラ」といった感じになります。
再び非常に興味深く、帰属グラフに関する限り、介入は確かに意味をなし、これが内部で起こっていることの指標だと思います。興味深いことに、彼らは改行トークンのような、また他の場所では文末トークンなどが、これらの計画的なことに大きな影響を与えていることを発見しています。
文が作成されている間、モデルは単に言語モデリングをしているように見えますが、文の終わりや行の終わりでは、いわゆる計画や思考が行われます。理由は明らかだと思います。その時点では、言語や文法、構文によって制約されなくなり、特定のテキストを続ける必要に縛られなくなるからです。
文の終わりでは、何でもする自由が最大限にあり、したがってテキストの全体的な計画に関するすべての考慮事項を置くことができ、今の文法を正しく保つ細部に気を取られる必要がありません。これはより強力な言語モデルを構築するための有益な情報かもしれません。
これは人々が「思考の連鎖」などと呼ぶハックのようなもので、これをより明示的にしているだけです。モデルに今生成しているものの文法に縛られることなく、物事を計画する自由を与えるのです。これら二つを分離させるようなものです。
彼らは中間の単語も調べています。ここでは最後の「rabbit」を見ましたが、この行の途中で実際に単語を生成する必要があるとき、それは念頭に置いている単語にも影響されているのでしょうか?帰属グラフは明確に「はい」と答えています。
「彼の空腹は」の後に新しい単語「like」が生成されるとき、帰属グラフは「rabbit」の明示的な表現と、現在の文法構造を表す文法的特徴の両方が活性化されていることを明確に示しています。また、「韻を踏む行の終わりに近づいている」という特徴も活性化されています。
詩のために念頭に置いているこの単語は、明らかにモデルの念頭にあります。これらを見ていくと人間的な表現をしないのは難しいです。これらは統計的モデルであることを忘れないでください。内部的に何かを考えると言うとき、私たちが意味するのは単にトークンの組み合わせが内部の特定の特徴を活性化させ、出力分布をシフトさせるということです。
私たちが言っているのは本質的に、韻を踏むプロンプトを持つことで、内部的に何と韻を踏むかが明確になった瞬間に特徴が活性化され、すでに候補となる単語を持ち、その確率を押し上げるということです。その後に起こることはすべてこれらの特徴に影響されます。
人間の言葉で言えば、終わりを念頭に置いて、それに向かって取り組むのであって、単に進めてから、韻を踏む必要があるときに、そこで適合するものを思いつくのではないということです。いわば計画の例です。
ここでも介入実験があります。詳しく見ることをお勧めします。
多言語回路も非常に興味深いです。彼らはモデルがどのように多言語的に機能するかを疑問に思います。大規模言語モデルは翻訳や多言語分析などにおいてかなり熟練しています。そこで問題は、内部はどのように見えるかということです。モデルは特定の言語に特化した思考回路を持ち、言語間に橋渡しがあるのか、それとも内部回路は言語に依存しないので、どの言語でも「馬」は同じものを活性化させるのか、これを調査しています。
私たちが見ていく3つのプロンプトは「smallの反対は」というものです。そして3つは同じことを意味しています。Haikuは3つのプロンプトを正しいもので完成させます。
これがどのように見えるか見ていきましょう。中間段階でかなり早く、これらの多言語的な特徴が出現することがわかります。言語特有の特徴があります。例えば、英語の「opposite」と中国語の「opposite」は異なる特徴を活性化させます。
しかし、すぐに言語に依存しない特徴が現れます。ここで見ることができます。「反意語」の概念が活性化され、それが「antithesis」(対立)や「giganz」(これはドイツ語だと思います)などの単語によって同様に活性化されます。
また、「opposition to」や、私はあまり多くの言語を知りませんが、「contrarium」(これはラテン語かもしれません)など、あらゆる種類の言語で同様にこれらの特徴を活性化させます。「gagan」「gazett」「gagenz」など、これはおそらくコーパスの特性で、これらの上位活性化が何であるかが決まります。
「opposite」「antonym」「antithesis」という単語が発言されたときに活性化される特徴と、多くの反意語タイプの状況で輝く概念を表す特徴の両方が見られます。そして再び、これらは大部分が多言語的です。フランスとドイツ以外の何かを見つけようとしていますが、ここでは見つかりません。
しかし、これらが「say large」と呼ばれる特徴を活性化させることがわかります。「antonym」の多言語的特徴と「small」という単語を表す多言語的特徴の両方が、「say large」という多言語的特徴を生み出します。これはモデルがどの言語でも「large」と言うようにさせる特徴です。ここでの上位予測は「large」「da」「big」「g」などです。
それが言語指標特徴と組み合わされ、モデルが正しい言語で出力する原因となります。中間的に少なくともある種の言語間の抽象化があるようです。そして出力言語は個々の言語的特徴によって影響を受けています。
「中国語で引用符を開いた後に続ける」はどこにありますか?これは単純に、中国語で引用符を開くときに活性化される特徴です。中国語でどのように引用符を開くかわかりませんが、中国語の言語を表す特徴と、中国語の文で引用符を開くときに点灯する特徴が特別にあるようです。
これは私にとって、引用符を表す特徴と中国語の言語を表す特徴の重ね合わせのようなものですが、モデルがこれを一つの特徴として学習した可能性もあり、それが実際の出力言語に影響を与えます。
彼らはここで代入実験も行っています。異なる言語で反意語と同義語の特徴を交換するクロスオーバーがどの時点で起こるかを考えるのは興味深いです。彼らの結論は、内部的に英語に偏った傾向があるようだということです。
これは訓練データのほとんどが通常英語であるためかもしれません。内部的には言語に依存しないものと主に英語的な思考の混合があり、その多言語的な回路への入力と出力に影響を与える言語特有の特徴があるようです。
再び、英語のグラフ、つまり特定の目標を達成するためにどれだけ強い介入を行う必要があるかのグラフは、常に他のものとは大きさの面でかなり異なって見えます。また、出力言語を英語以外のものに変更する介入の強さは、何か他の言語からのものを変更するよりもはるかに大きくなければならないことがわかります。
ここでフランス語もかなり劇的です。これらが多言語的な特徴です。
彼らが行う最後の興味深い実験は、「交差和」の特徴です。多様なトピックの段落のデータセットでの特徴活性化を収集し、それにはClaudeが生成したフランス語と中国語の翻訳があります。
各段落とその翻訳について、コンテキスト内のどこかで活性化する特徴のセットを記録します。各段落、言語のペア、モデル層に対して、重なりの度合いを測定するために和集合で割った交差集合を計算します。基準として、同じ言語のペアリングを持つ無関係な段落で同じ交差和の測定を比較します。
これはつまり、ここで英語と中国語を比較し、両方の言語に翻訳された多くの文を取り、各文をモデルに通して、どの特徴が活性化されるかを見るということです。私たちが興味があるのは、両方の翻訳が一緒に活性化する特徴の割合と、別々に活性化する特徴の割合を比較することです。
本質的には、活性化された特徴のうち、どれだけが多言語的な特徴、これらの抽象的な特徴であり、どれだけがより単一言語的な特徴であるかという意味です。興味深いのは、ここで中央に明確な山があることがわかることです。
中央の山は層の深さを表します。つまり、最も重なりが実際に中間層で発生することを意味します。これは以前の観察と一致し、より言語的な入力特徴があり、中間ではより抽象的な思考・推論・何でも呼びたいような特徴があり、最後にはより言語に特化した特徴があるということです。
つまり、入力があり、処理はより抽象的になり、そして最後の出力は再び言語や言語学などにより特化しています。同じグラフが他のコンテキストでも同様に当てはまると思いますが、おそらく測定は容易ではありません。しかし、BERTのようなモデルに関する多くの論文が同じ結論に達していることを思い出します。つまり、上位レベルの処理の大部分がモデルの中間セクションで行われるということです。
これも理にかなっています。ここで彼らは、より大きなモデルがより小さなモデルよりも優れた一般化を示すと主張しています。より高い度合いの多言語的重なりがあるからです。私はそれに必ずしも同意しません。より小さなモデルが必然的に弱いことも考慮する必要があるからです。
したがって、これは本当にリンゴとリンゴの比較ではありません。一般性はまったく同じかもしれませんが、より小さなモデルが弱いモデルであるため、単に正しい特徴を活性化させることができないだけかもしれません。しかし、どの特徴を活性化させるかを見れば、それらは実際に多言語的な特徴であるかもしれません。
だから、これらのグラフからその結論を導き出せるかどうかはわかりませんが、彼らはそうしています。「モデルは英語で考えるのか」という問いに対しては、対立する証拠があるようです。Claude 3.5 Haikuは特に中間層で真に多言語的な特徴を使用しているように見えます。
しかし、英語が特権を持つ重要なメカニズム的方法があります。例えば、多言語的特徴は対応する英語の出力ノードにより重要な直接的な重みを持ち、非英語の出力はより強く「言語Yでのsay X」特徴によって仲介されています。さらに、英語の「引用」特徴は「二重抑制効果」に関与しているようです。これは英語の「large」を抑制する特徴を抑制しますが、他の言語での「large」を促進します。
これは、英語がデフォルトの出力である多言語的表現の絵を描きます。
この論文にはまだまだ多くのことがあります。足し算についても本当に興味深いです。しかし、このビデオを長くしすぎたくないので、ここで一旦休憩しましょう。
次回はできるだけ早く戻ってきます。この論文は毎週土曜日のヨーロッパの夕方に行われるDiscordでの論文討論で議論しました。参加してお会いできることを楽しみにしています。次回までさようなら。


コメント