
48,428 文字

みなさん、こんにちは。4月17日の木曜日のAIへようこそ。今週は本当にすごい一週間でした。これは私たちの3回目のライブストリームですが、1週間で3回も2時間ずつライブストリームした週は記憶にありません。今日のショーはとても興味深いものになっています。なぜなら、見逃したくない人物とのインタビューがあるからです。トッド・シーゲルとのインタビューは絶対に見逃せません。トッド・シーゲルはGoogleの優れたソフトウェアエンジニアで、スタッフとしてA2Aプロトコルに取り組んでいます。A2Aプロトコルについては以前少し話しましたが、今回はそのプロトコルに実際に取り組んでいる人にインタビューする時が来たと思います。素晴らしいことですね。
もし私たちがMCPについて話すのを聞いたことがあれば、今週のショーでもMCPDについて触れるでしょう。それは誰もが気にしていることですから。GoogleのA2Aプロトコルはエージェント間のプロトコルです。先週簡単に触れましたが、もっと深く掘り下げたいと思います。そして深く掘り下げると、これについていくつかの非常に興味深いことに気づくでしょう。特にMCPと共存できることや、エージェント通信が構築される可能性の高いプロトコルであることなどです。Googleは50のパートナーとともにこれを立ち上げました。Weights and Biasesもそのパートナーの一つです。このインタビューにとても興味があります。皆さんはMCPと同じくらい爆発的に広がる可能性のあるプロトコルについての会話の最前列の席を得ることになるでしょう。素晴らしいことだと思います。
ステージにはヤム・ペレも迎えています。ヤム、こんにちは。元気ですか?今週3回目のライブストリームはどうでしたか?
「3回目のライブストリームですね。かなりオンラインにいましたね。なんて週だったんでしょう、本当にクレイジーでした。」
始める前に、今年の最初の約3ヶ月半か4ヶ月について少し振り返りたいと思います。皆さんは、この状況がクレイジーだと感じますか?それとも普通のペースですか?予想通りですか?皆さんの意見を聞きたいです。私は絶対にクレイジーだと感じています。
「絶対にもっと速いペースです。疑問の余地はありません。毎月同じプレイヤーから次々とモデルが発表されるのを見たことがありません。本当に、彼らは継続的にモデルをトレーニングし、強化して、数週間ごとにチェックポイントをリリースするところまで来たと思います。そして実際にそれを見ることができます。新しいGeminiモデルが既にテスト中で、Geminiを手に入れたのはたった2週間前だと思います。本当にクレイジーです。」
そして、すべてが新しいのです。以前はこのような画像生成はありませんでした。少し良くなっただけではなく、これまでになかったものです。そしてO3についてはまだ話し始めていません。私はそれを使って1日の経験しかありませんが、私の意見では絶対にクレイジーです。恋に落ちました。
ヤム、あなたの言っていることを反映すると、私たちはこれを毎週やっていて、過去2年間行ってきました。GPT4が立ち上げられた週や、0613、もし覚えているなら、GPT4の最初の関数呼び出し機能付きのものが大きかった週を覚えています。ミストラルが秋頃に立ち上がり、その後微調整などのフォローアップがありました。コミュニティからはたくさんのものがありましたが、大手が注目のアリーナで互いに戦っているような、このような狂気のようなアップデートの流れは覚えていません。それはまさにそのように感じます、これは注目のアリーナです。トランスフォーマーのことを考えると本当に面白いのですが、それは私たちの注目であって、モデルの注目ではありません。
メタがLlama 4を土曜日にリリースした理由があるのは明らかです。その理由はおそらくGoogleがGoogle Nextで独自のものを持っていたからで、OpenAIは常に「彼らは何かをリリースしようとしている」と戦っています。彼らは私たちの注目を奪い合っています。私たち、つまり私、ウォルフラム、ヤム、ニストンなど、私たち全員は、このニュースを皆さんにお届けするビジネスに携わっています。また、皆さんにこのニュースをお届けするためには、それらについて知る必要があります。それは一貫して難しくなってきています。先週も言ったように、私はいつも心の女性に対して「今週はどうやってすべてをカバーするのか全く分からない」と不平を言うわけではありませんが、何かを要約した後でそう思います。
どういうわけか、何とかして、私たちはそれをカバーすることができますが、それは一貫してますます多くなっています。私たちのフィルターを通した後でも、私たちはまた情報をフィルタリングしています。誰も皆さんにすべてを届けることはできません。例えば、スタートアップについてはあまり取り上げていません。評価についても、例えばMirror Moratiの20億ドルのサポートされたシードラウンドのような世界最大のものでない限り、ほとんど取り上げていません。売上についてもほとんど取り上げていません。OpenAIとWindsurfについて話すことになるかもしれませんが、AIのその部分には全く焦点を当てていません。
また、ツールについても話していません。特に基盤的な研究所とリリース、今すぐできることについて特に話しています。しかし、毎週立ち上がっている多くのツールもあります。例えば、私はAqua Voiceを使っていて、Aqua Voiceに感謝します。私の新しいテキスト読み上げツールになりました。カバーできないほど多くのものがあり、ストリームは本当にクレイジーです。
ぜひTwitterでフォローしてください。Xでフォローしてください。ウォルフラムをフォロー、私をフォロー、ヤムをフォローしてください。私たちはそれらについてエーテルで話していますが、それがショーに含まれることはありません。そうでなければ、5時間のショーになってしまうからです。ヤム、もし今週のライブストリームを要約するなら、月曜日に1時間半、昨日1時間半で合計3時間、今日はさらに2時間で合計5時間私たちが皆さんと話していることになります。本当に、チューニングしてくれる皆さんに感謝しています。
特にO3のリリースについては、ブレークスルーの連続のように感じます。見るのは素晴らしいことです。加速を感じることができますが、同時に私たちはそれに慣れてきています。それも効果の一つです。素晴らしいモデルを手に入れ、私たちの心は吹き飛ばされますが、今ではある程度慣れてきています。
私は確かに金魚になったと思います。以前の興奮を忘れてしまいます。インドのミームを知っていますか?誰かが誰かの名前を消して「これがあなたの親友です」と書いたもの。私もO3でそうしました。なぜなら、たった1週間前、私たちは4.5で興奮していましたが、それは数週間前のことですね。4.5はOpenAIが今までで最大のモデルで、今はもう使われていません。APIでの4.5、RIPです。
また、私が言いたかったのは、私たちもこれらのモデルで自分自身と能力を加速させているということです。昨日、私はO3を使ってショーの準備をする機会を利用しました。O3はURLや検索について推論する能力を持っています。私が準備するノートに既に標準が見られますが、O3はその多くを手伝ってくれ、素晴らしかったです。私たちもこれらのツールにアクセスできるようになったので追いついています。視聴者の皆さんにも、2年前と同じではないことを認識してもらうことが重要だと思います。情報を処理する能力も向上しています。それは素晴らしいことです。
私がまだ持っていないもので、2025年4月に持っているべきものは、常に実行されていて私のために何かをしてくれるエージェントです。視聴者の皆さんに、常に実行されているエージェントがあるかどうか教えてもらいたいです。WindsorやCursorなど、必要なときにエージェントを使用していますが、実際に必要なのは一時的な継続的なバックグラウンドエージェントで、ニュースをポップアップさせるようなものです。
コミュニティの人々の形ではそれを持っています。例えばLincolnに感謝します。ColleenやRyanなど、私がこの分野で見る人々や、彼らは人間なので自分自身のエージェンダを持っており、投稿したりリンクしたりタグ付けしたりするので、フォローすることができます。しかし、私は特に訓練されたAIエージェントが行って、私のためにいくつかの要約をするなど、木曜日に現れて話すだけでよいようなものが必要です。
このとても素敵な導入と改善のスピードについての興奮で、TLDDRを始めるのに十分な人が集まったと思います。皆さんどう思いますか?始めましょう。
では、TLDDRに行きましょう。基本的に、木曜日に初めての方のために、これから話すことすべて、または少なくとも速報前に知っていることすべてです。木曜日に話すことを知っていることがここにあります。
みなさん、こんにちは。これは4月17日の木曜日のための私のノートです。ショーの一部を見逃した場合は、この10分間のセグメントを簡単に聞いて、「あ、クリングについて聞きたかった」と思い出してショーに戻ってくることができます。ショーはAppleやSpotifyなどのすべてのニュースポッドキャストプラットフォームにも投稿されています。また、ニュースレターはSubstackに投稿されています。Xの場合は特にSubstackに行き、すべてのリンクがそこにあります。何も見逃す必要はありませんし、何かを書き留める必要もありません。私がそれを担当します。ニュースレターを購読してください。6,000人の購読者に近づいていると思います。それはクレイジーです。
そして、非常に重要なことですが、今日の太平洋時間の午前10時、つまり約1時間15分後に、GoogleのTodd Siggleとのチャットを見逃さないでください。これは見逃せません。A2Aプロトコルについてのこのチャットにとても興奮しています。A2Aはすぐに最大のニュースになる予定だからです。これを最初に、または少なくとも最初のインタビューの一つとして聞いてくれることを願っています。
今日のショーのホストはWolfframとYamです。過去2年間の木曜日の著名な共同ホストとして、皆さんにも参加していただけて良かったです。もちろん、今週の主要なニュースから始めます。おそらく今月、過去数ヶ月、おそらく12月に発表された時からの最大のニュースかもしれません。OpenAIからのO3のリリースです。O3は旗艦の推論モデル、最大の推論モデル、テスト時のコンピュータであり、クリスマスの12日間に発表されたすべてのものです。O3は今、私たち全員が利用できるようになりました。また、O4ミニがChatGPTとAPIで利用可能になりました。
これについては昨日1時間半ほど話しましたが、それ以来使ってみました。ほとんど寝ていないと思います。O3について絶対に話すつもりです。いくつかのことをカバーします。ヤムを通じて既にいくつかの速報があります。ヤム、ありがとう。長いコンテキストのパフォーマンスについて、それは絶対に素晴らしいです。O3についての会話を見逃さないでください。
O3の数ヶ月前、基本的にはO3の2日前に、OpenAIもGPT 4.1、4.1ミニ、4.1ナノをリリースしました。覚えていますか?それは今週の月曜日でした。クレイジーですね。1時間半のライブストリームとカバレッジもありました。4.1について話さなければなりません。4.1ミニについて、私はいくつかの評価を持っています。Wolfframもいくつかの評価を持っています。そのモデルは、思考していないという事実に比べて信じられないほど良いです。思考者や推論者にその風を奪われるべきではありません。この4.1ミニとサンドイッチのプロンプトなど、私たちがカバーするすべてのことについて非常に興奮しています。
Mistralは「Classifiers Factory」と呼ばれるものをリリースしました。開発者にとって非常に便利です。これについて少し触れるかもしれません。Anthropicのクラウドは研究機能を追加しました。Deep Researchではありませんが、現在は最大支払い層のみに深い研究を提供しています。実際のところ、単にAnthropicに支払っている人々はこれを得ることができませんでしたが、Googleワークスペースの統合も持っています。Anthropicクラウドは現在、UIを通じてすべてのメールやドキュメントについて推論し、研究のようなことを行うことができます。彼らはこれをディープリサーチと呼んでいませんが、それは効果的です。
Coherenceは新しい埋め込みモデルをリリースしました。最先端のマルチモーダル埋め込みです。Ginaから、オープンソースでリリースされたマルチモーダル埋め込みについて以前話しました。Coherenceはembed 4をリリースし、今ではマルチモーダルにもなっています。マルチモーダル埋め込みは素晴らしいです。なぜなら、オープンソースのLLMに移行するにつれて、全体的にマルチモーダルを得ているからです。
オープンソースLLMのカテゴリーでは、今週はそれほど興奮することはありませんでした。このカテゴリーで間もなく登場する2つの非常に刺激的なことは、OpenAIが最終的に何かをオープンソース化することです。彼らはサンフランシスコで開発者とオープンソースイベントを行い、私たちを驚かせるような何かをリリースする予定です。それについてだけ話すつもりですが、DeepSeekについても触れる予定です。DeepSeekはどこにいるのでしょうか?AlimとQuinnからしばらく聞いていません。このカテゴリーは近い将来、非常に刺激的になるでしょう。今週はそうではありませんが、今週は大きな研究所についてのすべてです。
ただし、いくつかのことがあります。OpenAIは今週、モデルではなく、長いコンテキストのための新しいベンチマークであるMRCRをオープンソース化しました。彼らは長いコンテキストでブレークスルーを達成し、それについて話すつもりです。マイクロソフトはBitNet 1.5をリリースしました。小さなものですが、言及すべきです。Prime Intellectは、32億パラメータのグローバルに分散された強化学習実験をトレーニングしました。以前Prime Intellectについて話しましたが、これはIntellect 2で、RLであり、推論に焦点を当てています。分散されています。
また、ChatGLMについても言及すべきです。これはGLMモデルをカバーしましたが、Z.AIにリブランドされました。発音の仕方はイギリス人かどうかによって異なりますが、Z.AIと言いましょう。彼らはまた、GLM40414をオープンソース化しました。これは文字通り4月のもので、オープンソースファミリーです。
今週の話題では、MCPとA2Aも加えたいと思います。Weights and Biasesでは、まずTodd SegleとA2Aプロトコルについてのチャットがあることを言及したいと思います。また、最新のGPTモデル用のWeaveプレイグラウンドサポートがあることも言及したいです。これらのモデルを比較するためにプレイグラウンドを使用する方法を示します。プロダクションからトレースを取得し、新しいモデルでこれを再試行して、どのくらいうまく機能するかを確認するなど。これを実際に見せる予定です。ビデオも作成しましたが、本当に素晴らしく便利です。
ビジョンとビデオのカテゴリーも今週上昇しています。GoogleのV2について話しました。V2のビデオを見せましたが、GAにヒットしました。つまり、今では使用可能になっています。Geminiアプリでは無料です。Googleは多くのTPUを持っているため、いくつかのものを無料で提供しています。V2はAI Studioでも無料で、そこに行って画像をアップロードできます。テキストからビデオへ、画像からビデオへ、またテキストからテキストと画像からビデオを組み合わせることもできます。それは現在GAにあり、デムのような他のモデルと一緒に、依然として最高のビデオ生成モデルの一つです。
ある晩遅くまで起きていて、Clingの人々、つまり複数のビデオモデルをリリースした人々がCling 2.0をリリースしました。彼らはまた、他のモデルの上で最先端を主張する画像生成モデルをリリースし、基本的にClingでの創造的なツールの全体的なスイートを作りました。それを見せたいと思います。本当に素晴らしいです。彼らはAI創造のニーズのためにすべてを行う総合的な場所になろうとしています、芸術的な観点から。
また、ByteDanceが7Bの発表について話すべきです。彼らはまだリリースしていないと思いますが、7Bのため、彼らはビデオ生成の基盤モデルであるSeaweed 7Bをリリースすると思います。ビデオにはもう一つあります。1x、AlibabaのビデオモデルはFirst Frame Last Frameモデルもリリースしました。これらのモデルは非常に便利です。なぜなら、最初のフレームと最後のフレームを追加し、別のビデオを取り、その最初のフレームを取って、それらを一緒につなげることができるからです。
音声とオーディオで最も信じられないニュースの一つとして、Googleがドルフィン・ジェマをリリースしました。ドルフィン・ジェマについては少なくとも少し話さなければなりません。なぜなら、彼らはこれを4月1日にリリースしなかったからです。彼らは実際の世界のドルフィンデーか何かの後に少しリリースしました。Googleはイルカの通信に取り組んでいます。もしこの知性の時代が、イルカのような他の知性と話すことを可能にするなら、それは信じられないことだと思います。ウォルフラムと話したのですが、1分間だけイルカの音を出して、何が起こるか見てみたいと思っています。ですので、ドルフィン・ジェマについても話すつもりです。
AIアートとディフュージョンでは、ByteDanceが少なくとも画像生成モデルの人工分析のカテゴリーを引き継ぎました。SoraからのSora generationさえも打ち負かしています。これからは、ChatGPTのネイティブな画像機能をSora imageと呼ぶことにします。なぜなら、Soraでもアクセスできるからです。ChatGPTのネイティブな画像生成と言い続けたくないので、これはDallEではありません。彼らはこれにブランド名を付けていません。私にとってはSora imagesです。それらは依然として信じられないほど素晴らしいですが、いくつかの人工分析のリーダーボードによると、ByteDanceのCream 3、バイリンガル画像ディフュージョンは現在、世界中で最高のAIアートとディフュージョンモデルです。それはクレイジーです。
ツールセクションでは、OpenAIが「すべて」と一緒にCodexをデビューさせました。CodexはCLIで、以前言及したクラウドコードに非常に似ています。CodexはかつてOpenAIのコードを行うモデルでした。それらの機能はメインモデルに組み込まれました。彼らはCodexブランド名を復活させ、私はそれについて非常に嬉しいです。今週使用したCLIです。かなり良いです。それについて話すつもりです。ここで唯一持っているのはCodexがクラウドコードのようだということですが、実際はそうではありません。また、O3、おそらくO4ミニ、4.1、Windsurfの使用は次の1週間は無料です。Windsurfを言及しないわけにはいきません。WindsorfのVarunが4.1イベントに現れたのを見て、それは非常に興味深いと思いました。彼らはかつてCursorと友好的でしたが、今はWindsurfになりました。
OpenAIがWindsorfを約30億ドルの評価額で買収するという噂があります。これは非常に素晴らしいことです。KodiumまたはWindsurfについても噂があります。WindsorfのKevinがショーに出て、なぜWindsorfが素晴らしいのかについて話したことを思い出してください。それ以来、私は主にWindsorfを使用しています。Cursorに支払っているにもかかわらず、Windsorfにも支払いをしました。それも非常に楽しんでいます。
これがすべてをカバーするものだと思います。なぜなら、Todd SeggleとA2Aについて少なくとも20分間のインタビューがあるからです。ホストパネルの皆さん、私たちの話を聞いている皆さん、今週の他に大きなことで、私が見逃したものはありますか?絶対にカバーしなければならないものはありますか?なければ始めることができます。
「ここで話せることはたくさんあります。ここのトピックはそれぞれ1時間くらいかかります。フルタイムで実行されているエージェントや、CursorとWindsurfの比較など、ペースは絶対にクレイジーです。素晴らしいですが、絶対にクレイジーです。」
ペースについて言えば、このショーもペースを保ちましょう。大企業のAPIから始めましょう。残念ながら、大企業のAPIへの移行はありませんが、これをやることにします。
木曜日だけの速報ニュースをお伝えします。速報ボタンを使用する理由は、今この瞬間に速報があるからではなく、この1週間ずっと速報があったからです。速報を追っていて、事前に知らなかったライブストリームにジャンプしました。Nは疲れているように見えます。私たちは寝ていなかったからです。OpenAIからのリリースを追っていました。小さいものから始めて、より大きなものをカバーしましょう。それが私には公平な方法のように感じます。
簡単に言及したような、大企業のクラウドの小さなじゃがいもについて。基本的に、クラウドは現在検索を行います。クラウドは歴史的に、検索をUIやツールなどに採用するのが非常に遅かったです。アーティファクトは素晴らしく、彼らはそれに先駆けましたが、クラウドAIがそのサービスに支払っている場合、現在は研究を行います。Deep Researchとは呼ばれていませんが、複数のリンクにわたる推論を行い、かなり良いです。それだけでなく、彼らはこれと一緒にワークスペース統合を追加しました。特にGoogleワークスペース用です。あなたのドキュメント、リンクなどについて推論することができます。彼らはこれについて非常に喜んでいます。
非常に興味深いことに、彼らはOpenAIがディープリサーチの評価をリリースした週と一緒にこれをリリースしました。まだ比較を見ていませんし、まだアクセスもありません。これはAPIではなく、UIの機能です。ドキュメントを含む、さまざまなものについて推論することができます。クラウドマックスを使用している場合、彼らの月額200ドルの層では、これはかなり良いです。接続されたアプリのスタッフは見ていますが、Gmailの検索とカレンダーの検索は見ていますが、研究は見ていません。機能の半分にアクセスできました。
研究は現在、米国、日本、ブラジルのマックスとチームおよびエンタープライズプランの早期ベータとして利用可能です。マックスではないのかもしれませんが、プラスの購読者だと思います。カナダ人なので、彼らはリリースしていませんでした。なぜか分かりません。とにかく、Anthropicは常に限られた開発者操作を持っていました。彼らからは常に限られたリリースでした。彼らは苦労しています。
このことについて簡単に述べましょう。Mistral Classifiers Factoryについて。Mistralは、彼らのサービス上で実行される独自の分類器を構築できる素晴らしいものをリリースしました。モデレーション、意図検出、感情分析、データクラスタリングのための分類器を構築できます。これらはLLMではなく、Mistralがホストする非常に小さなモデルです。しかし、CSV形式で非常に限られた量のデータをアップロードでき、彼らがこれをトレーニングして構築します。例えば、金融部門での不正検出などがあります。
もし絶対に超高速で高速な分類器が必要な会社であれば、Mistral Classifiersはあなたのためのものです。これは非常に興味深いステップで、LLMではなく、ガードレールをサポートする世界への一歩です。それはかなり素晴らしいです。また、ある程度Weights and Biasesもサポートしていると思います。このサービスが必要な企業にとって、Mistral Classifiersは最適です。
Coherenceについて簡単に話しました。彼らが意味することを示しましょう。embed 4はビジネス向けのマルチモーダル検索です。分類器と、RAG用のマルチモーダル埋め込みが必要な場合、Coherは分類器と、Coherの組み合わせです。多面的なドキュメント、PDFなどを正確かつ迅速に検索できる独自の能力があります。以前、Nomic AIのZach Newsbombと話しました。Zachはなぜマルチモーダル埋め込みが重要なのかについて話しました。なぜなら、基本的にテキストと画像とPDFを別々に埋め込むと、それらを一緒に組み合わせるために多くの検索を行う必要があるからです。マルチモーダル埋め込みは、これを一つの埋め込み空間にもたらし、関連するチャンクを引き出すことができます。一部のPDFは画像のみなので、それは素晴らしいです。Coherenceのembed 4に感謝します。
これらすべてを片付けたところで、今週の最も重要なニュースは絶対にGPT 4.1、4.1ミニ、4.1ナノでした。これはAPIのみで、月曜日に開発者向けにリリースされ、その後O3とO4ミニがどこでもリリースされました。このニュースから始めましょう。GPT 4.1と4.1ミニについて、このパネルの皆さんに質問したいと思います。なぜGPT 4.1はGPT 4.5より優れているのでしょうか?誰かこの質問に答えてください。
「より長くトレーニングしただけだと思います。GPT 4.5はおそらく世界最大のものであり、その主張がありますが、トレーニングにはより多くの時間がかかります。各ステップはより多くの費用がかかるので、それほど長くトレーニングしなかったと思います。GPT 4.1はGPT4にかなり近いように聞こえます。おそらく同じモデルで、より長いコンテキストでより長く、より焦点を当てたデータセットでトレーニングされたものです。現在、モデルの振る舞いから、データセットが改善されているのが分かります。データセット、評価、彼らがバックグラウンドで行っていることは、モデルの振る舞いから見ると、彼らは人々と一緒に座り、モデルは必要なことについてますます鋭くなっています。これが起こっていることだと思います。より良いデータとフロップス、多くのフロップスです。」
Wolfframさん、GPT4.5には何か魔法があり、それが単なるサイズだけかどうかはわかりません。他のモデルができないことをそれはできます。しかし、スケールが必要なものすべてなのかもしれません。
「スケールは少なくとも必要なものの一部です。あなたの指摘に対して、GPT4.5は私たちが大きなモデルの香りと呼ぶものを持っています。魔法は説明できないものです。私たちはモデルと長い間話してきて、一部の人はすでにそれを理解できています。それが大きなモデルであることを知っています。OpenAIが基本的にAPIを非推奨にし、GPT4.5がAPIで終わりに近づいていると言ったからです。悲しいことですが、巨大なモデルのため、実行するのに非常に多くのコストがかかりました。まだ蒸留されていません。」
Wolfframさん、4.1が何であるか、なぜリリースされたのか、そして4.1、4.1ナノ、4.1ミニの評価について簡単にまとめましょう。
「4.1、ミニ、ナノ、私は3つ全てをテストしました。興味深いことに、ナノはそれほど良くなかったですが、それでも多くのモデルよりは優れています。ミニと4.1は非常に近いので、予算を気にする人は、ミニを多く使うと思います。なぜなら、はるかに安くて近いからです。最高の品質が必要な場合は、O3を使うでしょう。O3は推論モデルです。O3ミニ、O4ミニなど、本当に多くのモデルがあるので、どれを使いたいかを考える必要があります。インターフェースを使用している場合、通常は最高のものを使います。追加のコストはかかりません。しかし、APIを使用する場合は、何が必要か考え、評価を行って、モデルが特定のユースケースに十分かどうかを知り、過剰に支払わないようにする必要があります。」
OpenAIの命名は明らかに馬鹿げています。特に、私たちほど密接に追跡していない人にとっては、モデルを下げるのはおかしいです。それで冗談から始めました。なぜ4.5は4.1より悪いのでしょうか?モデルの命名は4.6などになるべきではないでしょうか?ヤムさん、あなたの言うとおり、モデルのサイズのせいです。ますます。5リリースは10倍のジャンプを意味し、完全なリリースは100倍のジャンプを意味します。それが従来の命名でした。しかし、4.1は0.1のジャンプではありません。
命名の擁護をしますと、O4と40について話すことで混乱しました。Oで始まるモデル、つまりO1、O3、現在のO4ミニは推論モデルです。4は40から来ました。英語ではOと呼ぶだけですが、40は基本的に40です。GPT 3.5やGPT4のように。それから… いや、完全に混乱しています。Oはオムニのことですね。
命名は非常に混乱するものです。APIでも本当に混乱したのは、現在O4ミニと40ミニがあることです。40ミニはAPIにまだ存在していますが、4.1に向けて非推奨になっています。もはや40やオムニなどと言う必要はありません。なぜなら、基本的に今週リリースされたのは、多くの人にとって以前の40および40ミニモデルの代替品だからです。
「3は1の後に来ました。O2はないからです。非常に混乱します。O2についてはSamがある時点で言及しましたが、ロンドンのO2アリーナがあるため、法的な戦いに入りたくなかったので…」
誰かがO7を買って、他の誰かの前に商標登録すべきです。
皆さん、4.1の実際の立ち上げについて簡単に説明したいと思います。なぜなら、O3についても話さなければならないからです。彼らは3つの主要なものを立ち上げました。GPT 4.1はAPIで基本的にGPT 4.0に取って代わるフラッグシップモデルです。彼らは現在テストしています。ある時点で、おそらく4.0を非推奨にして、このことに向かうでしょう。4.1ミニはコストの80%で、レイテンシが低いです。これらのモデルは高速です。Windsurfでテストしましたが、飛ぶように速いです。そして4.1ナノは超高速ですが、正直に言って愚かです。ナノを試しましたが、基本的に何とも比較になりません。
しかし、より大きなモデルをテストしている非常に真剣なタスクでは、ナノは翻訳において絶対に素晴らしいです。翻訳のユースケースがある場合、ナノはおそらくあなたのためのモデルです。100万トークンあたり1セントのコストがかかり、これは何もありません。すべての翻訳を行うことができます。おそらく文字起こしも良いでしょう。
「それは素晴らしい例です。ユースケースとどのモデルを使用するかについて見ることができるチャートはありません。自分で実験して見つける必要があります。JPTにどのモデルを使用するか尋ねることさえできません。モデル自体について告げるのは悪いことで知られています。現在は検索を使って見つけることができます。」
「4.1に100万のコンテキストがあると説得するのに本当に苦労しました。それは本当に持っていないと主張しました。perplexity MCPを使って、どれだけのコンテキストがあるか調査するよう言いました。そして初めて諦めました。それは知っていました。それは4.1であることを知っていました。それはクールでした。モデルの名前を知っていましたが、自身の機能を知りませんでした。」
「長いコンテキストで問題は非常に長くなっています。もはやそれは重要ではありません。」
「あなたはOpenAIのシニアモデルです。長いコンテキストが戻ってきます。」
これらの3つのモデルすべてについて話さなければならない絶対的に素晴らしいことは、OpenAIの100万コンテキストウィンドウ長へのステップです。OpenAIは伝統的に100kを提供していましたが、現在、すべての3つのモデルは200kです。これは低レイテンシで100万コンテキストモデルです。ナノのユースケースについては絶対に、例えば低レイテンシで100万コンテキストなど、多くのことができます。
「4.1ナノでさえ、100万コンテキストが1セントというのは絶対に注目すべきです。インには10セント、アウトには40セントで、これは本当にクレイジーな価格です。ちなみに、4.1ではバッチ処理も可能になりました。データセットで100万トークンあたり4ドルで処理できます。いくつかの医療データを生成し、2人の異なる医師に見てもらいました。これは医療のSOAP形式をやるのに最適なモデルです。スタイリングと説明の仕方が本当に素晴らしいです。4.1は現在最高のスタイルの応答を持っています。なぜなら十分に長いからです。Sonnetはより多くのデータを提供し、特に会話が必要な場合は実際により詳細ですが、レポートを提供する点では、これは断然最高です。36の言語で行い、いくつかをチェックしましたが、ランダムなものでも、すべての言語で完璧でした。」
「それは良いです。コードにはそれほど優れているとは思いませんが、他のものにはほぼ最高のスタイリングを持っています。4.1のデータは最高だと思います。」
このモデルのコーディングフォーカスについて話しましょう。彼らは絶対にこれらのモデルにフォーカスし、「これらはコーディング用です」と言いました。彼らはSweetbenchを見せてくれました。4.0から33%が55%にジャンプし、ほぼO3ミニに近づいています。O3は推論モデルですが、これは推論モデルではありません。これも推論モデルより速いです。Either Polyglotで開発生成の精度を2倍にしました。コーディングのベンチマークとして見ていたEither Polyglotで、非常に大きな向上が見られます。それでも、それほど良いとは思っていないのですね?
正直に言って、ライブストリームでかなり興奮しました。彼らがこれらのモデルでより多くのフロントエンド、UIなどをトレーニングしたと言及していたのを覚えているでしょう。おそらく過剰に興奮してしまい、それ以来、Windsurfで試してみました。それは無料で試すことができます。彼らが私に与えたウェブサイト、私はそのウェブサイトについてアイデアを持っていました。間もなくそのウェブサイトを皆さんと共有しますが、4.1が私に与えたUIはあまり良くありませんでした。また、ライブストリーム後にX上で投票を行いました。私がCloud 3.7にウェブサイトへの2つの追加を依頼し、その後4.1にも依頼しました。4.1は実際にそこで良い仕事をしました。私たちは全員それを見ました。まともな仕事でした。人々はCloud 3.7を好みましたが、私はCloud 3.7が非常に熱心な人だと思います。
命令に従う向上については、彼らはまた、命令内部のハードモード命令進化を持っていました。OpenAIはまだリリースしていません。彼らは4に対して30ポイントの命令従いの向上を見ました。また、マルチターンの一貫性もAnthropicのクラウドと同程度です。より良く命令に従います。
ここで、私が絶対に馬鹿げていると思ったサンドイッチについて話すべきです。実際にこれをテストしました。実際に見せたいと思います。これは今週のBuzzスポンサーセグメントではありません。これは文字通り私だけです。メールを引き出す間に、サンドイッチについて説明できますか?
「プロンプトサンドイッチのことですね。上に何かがあり、次にコンテキストがあり、次に下にクエリがあります。OpenAIの場合、上に何かがあり、次にコンテキスト、次に下にクエリを持つべきだということでした。一方、Anthropicの場合は、最初にコンテキストを持ち、次に下に指示を持つべきだと言っていました。OpenAIの場合、クエリの入力をサンドイッチします。指示を上と下の両方に繰り返すこともでき、それが性能を向上させます。アレックスが評価し、それがスコアを大幅に向上させることがわかりました。多くの人にとって、それがクレイジーな部分でした。」
「4.1のための「プロンプトサンドイッチ」テクニックは、指示を持ち、次に長いコンテキストを持ち、次に同じ指示を再び持つというものです。それはパフォーマンスを向上させました。OpenAIはプロンプトガイドをリリースし、OpenAIの誰かも4.1のテクニックを共有しました。これが全く機能するとは思っていませんでしたが、これほど機能するとは思っていませんでした。」
見ている皆さん、見ていない皆さん、これは20の難しく推論する質問に対する標準的な評価です。推論モデルはこのようなベンチマークを絶対に引き裂きますが、それでも20のすべてを得ることはありません。これは氷のキューブの質問のような質問です。また、ここにもたくさんあります。これらは20の質問で、通常3回実行します。推論モデルではないモデルはこのベンチマークでは非常に悪いです。右側にある3つのモデルは、4.1、4.1ミニ、4.1ナノです。ナノは質問の1.8%を取得し、ミニは31%を取得し、4.1は48%を取得しています。これを聞くだけでは混乱するかもしれませんが、ニュースレターでも共有します。
左側のモデルは、プロンプトサンドイッチングだけで同じモデルです。この新しい評価で行ったことは、この小さなサンドイッチ絵文字で示されているように、最後にプロンプトを追加しただけです。4.1の場合、これは何も変わらず、質問の48%と全く同じでした。しかし、4.1ミニ、半分のコストで実行が速いモデルの場合、38%から49%の質問に跳ね上がりました。これはクレイジーです。このジャンプはクレイジーです。これは推論モデルではないので、これらの質問でこれほど良いはずがありません。ナノの場合でも、いくつかの質問で少し改善しました。最大のジャンプは断然ミニでした。ミニはこのプロンプトテクニックで通常のモデルとほぼ同等か、それを上回ります。これはクレイジーです。他の試みにも一般化するかどうかはわかりませんが、これは絶対にクレイジーです。
また、出力するトークンの合計も少し増えているのがわかります。同じことを尋ねると、実際により多くのトークンを出力します。これもクレイジーです。今見ているのはW&B weaveです。モデルを評価しないなら、本番環境でどのように動作するかをどのように知るのでしょうか?これが私のやり方です。
このモデルについて他に話したいことは何ですか?確かに確認する価値がある100万コンテキストウィンドウはクレイジーです。彼らが投稿した「針と干し草の山」について話したいと思います。そして、すぐにO3に移るべきです。
「針と干し草の山」は、Greg Comradが考案した非常に素晴らしいが煩わしいテストです。Greg Comradは現在RKGI財団の社長です。このテストは、非常に長いコンテキストの中で、モデルにランダムな情報の一部を与え、モデルにそれをコンテキストから取り出すよう依頼し、長いコンテキストでこれが機能するかどうかをテストします。ほとんどのモデルは現在これに優れていますが、長いコンテキストの周りの推論は必ずしも「針と干し草の山」と相関していないことを私たちは知っています。グリーンフィールドはしかし、彼らは「針と干し草の山」でこれらのすべてのモデルが絶対に100%に近いことを示しました。彼らはまた例を示しました。彼らはログの束を持ち、ログではない行を挿入し、モデルはこれを引き出すことができました。
「非課金アカウントで開いてみました。ChatGPTを開き、モデルを切り替えるをクリックすると、「GPT40: ほとんどのタスクに最適」、「O4ミニ: 最も速く、高度な推論」、「GPT40ミニ: 日常のタスクのためにより速い」、「再試行 GPT40」と表示されます。どうやって誰かがここで見分けられるのでしょうか?」
公式木曜日ガイドはこちらです。まず、私たちは全員コンサルタントとして利用可能です。連絡したい場合は、私たち全員に連絡できます。木曜日を聞いている場合は、木曜日プロモを使用して私たちのコンサルティングで20%オフになります。これはまず第一です。二つ目は、人々は本当にこれでサポートが必要なので、部分的に冗談を言っているだけです。
コーディングとAPIの構築については、4.1シリーズのモデルは現在おそらく評価すべきものです。これらの速度で100万コンテキストウィンドウを試すのはクレイジーです。もし単にチャットしているなら、O3です。もし単にチャットしていて、待つことに問題がなければ、O3は断然最高です。もし知能で構築しているなら、O4ミニ、それらのAPIは素晴らしいです。しかし、まだO4ミニについては触れていません。
すべての目的と目的のために、UIにいるだけなら、以前のモデルを使用する理由はありません。トップのモデルを使用して待ちましょう。「日常のタスクのためにより速い」というのは、必ずしも必要ではないということです。もしエンジニアとして何かを構築しているなら、評価してください。エンジニアとして何かを構築していて、タスクで評価していないなら、何をしているのでしょうか?Weights and Biasesで話しましょう。私たちはあなたを助けます。なぜなら、WolfframのタイトルはAI評価者であり、Lamindでは、モデルを本番環境で評価していない場合、パフォーマンスを損なう可能性があります。あなたのタスクが完了していないことさえ知らない可能性があります。
「針と干し草の山」に戻りましょう。OpenAIはまた、100万トークンの長いコンテキストパフォーマンスを新しいMRCRベンチマークで評価したことを示しました。彼らはまたMRCRベンチマークをオープンソース化しました。それはAnthropicのものか、誰かのものかもしれません。そして彼らはそれを改良しました。現在HagenFaceにあり、同じ日にオープンソースになっています。彼らはすべての3つのモデル、ナノでさえも、100万ウィンドウ全体で素晴らしい検索を示しています。それはOpenAIからのベンチマークもリリースするのは非常に良いことです。なぜなら、長いコンテキストの評価は難しいからです。
マルチモーダルの進歩について、彼らはビデオMMEで最先端を主張しました。これはフレームごとに貼り付けることによるビデオの長いコンテキスト理解です。ビデオの長いコンテキストQ&Aで、彼らは4.1ミニで72%で最先端を主張しています。ミニは素晴らしいモデルです。ミニを見逃さないでください。私はミニが多くの場合、4.1より優れていると思います。
彼らはまた初日から微調整可能です。これは素晴らしいことです。なぜなら、いくつかのものをアップロードして、ユースケースに特化したモデルを取得できるからです。それは基本的に言及したいことです。Windsurfは次の1週間無料です。今はなぜかわかりますが、Cursorも追随し、次の1週間も無料です。これは非常に興味深いことです。ユーザーを取り込むための新しいモデルリリースです。「1週間無料で使ってください」と言います。彼らもこれを評価したいのでしょう。
「もしあなたが始めにWindsurfユーザーで、私のように使用を停止した場合、少なくとも昨日までは、早期採用者価格を月額15ドルではなく10ドルで得ることができました。今ロックすれば。」
絶対に、Noah Macallenからのプロンプトガイドをシャウトアウトします。彼はGPT4.1でエージェンティックワークフローと思考連鎖のために作業していました。これらのモデルに思考連鎖をプロンプトすることができます。新しいOシリーズモデルと思考モデルには思考連鎖が組み込まれていますが、以前のトリックはこれらのモデルでもまだ機能します。思考するよう依頼でき、思考するとより良くなります。プロンプトサンドイッチで依頼すると、さらに良くなります。モデルに、ユーザーの意図を理解するためにより多くの時間を費やすよう依頼することができます。これは助けになります。シンプルな指示から始め、プロンプトの終わりにモデルは問題について考えるのが得意だと言うことができます。長いコンテキストの提案なので、基本的にこのプロンプトガイドも追加します。これは彼のスレッドですが、彼らは実際にドキュメントにもプロンプトガイドを追加しました。
皆さん、今週のメインコースに移ります。おそらく今月、おそらく今四半期の最も重要なニュースです。OpenAIは昨日、ついに私たち全員に旗艦の推論モデル、おそらく現在世界で最高のモデルをリリースしました。LLMが行うほぼすべてにおいて、O3とO4ミニをリリースしました。行きましょう。私たちはここでライブストリームを見ていて、これらのモデルを試すのにとても興奮していました。皆さん、O3についてどう思いますか?ヤム、O3についてどう思いますか?24時間以内ですが。
「ワオ、本当に本当に良いです。真剣に、彼らが何をトレーニングしたのか分かりません。推測はありますが、本当に何をトレーニングしたのか分かりません。どこから始めればいいのか分かりません。多くの例があります。あなたが行うあらゆる小さなことを、それは知っています。オンラインに行って検索するという話をする前でさえ、それは多くの小さなことを知っています。これも狂っています。URLや特定のサイトに行くよう指示できます。これは本当にクレイジーなリリースです。本当にクレイジーなリリースで、O3 propを待ちきれません。これはクレイジーなモデルで、ほぼすべてにおいてクレイジーです。」
同意します。私はこれを専らつかっています。発表の中のいくつかのことをご紹介します。すべてをカバーするのは難しいですが、いくつかの点をご紹介します。このモデルは、ツール使用における推論という点でユニークだと思います。推論中にツールを使用して答えを導き出します。
昨日のショーで試したい例の一つは、帽子の上にGemini 2.5のMMUスコアの16進コードの最後の5桁が書かれたカウボーイの画像を生成するというカウボーイの例です。これが完全なプロンプトだったと思います。これは口頭で言うのは難しいですが、基本的にツール使用を含む4つのタスクがあります。Gemini 2.5のMMUスコアを調べる必要があります。次に、コーディングツールを使用してこれを変換し、あるモデルを把握する必要があります。どのモデルかさえ伝えませんでした。「Geminiシリーズの最新モデル」と書いただけです。
これを把握する必要があったので、実際に検索を行いました。「これを検索する必要がありますね」と言いました。そして実際のスコアを取得し、ツーリングコードを使用してスコアを16進数に変換し、画像生成機能ツールなどを使用してこの画像を生成しました。7つのステップと4つの検索を行い、それから検索について考え、「これについて推論しましょう」と言ったのはクレイジーでした。
これは、ヤムが興奮していると言っていることでさえありません。このモデルがすでに持っている知識は素晴らしいです。これが彼が言及していることです。これは知識に加えて、トレーニングに加えて、他のすべてのことに加えて、必要なときに検索を行い、推論する必要があるものを調べることもできるということです。
私はディープリサーチについて私たちの興奮について言いたいと思います。ディープリサーチはしばらくの間利用可能でしたが、これを使用していました。そして月額200ドル支払う必要がありました。それからユーザーに来ました。ディープリサーチはO3によって支えられていました。ディープリサーチは信じられないほどですが、私がすることすべてにディープリサーチを望んでいるわけではありません。モデルがより速く反応することを望んでいます。これがO3が私のためにアンロックしたことです。
O3は、ミニディープリサーチを行う能力を私にアンロックしました。非常に特定のトピックについてのシャローなディープリサーチではなく、これについて推論し、十分な理解があるかどうかを確認し、それを私に戻すことができます。それが私にとって最大のアンロックでした。ツール間で推論し、推論プロセス中にツールを使用して、以前のどれよりもはるかに優れた答えを得ることができます。これは絶対に信じられないことです。これは私の新しいデフォルトモデルです。私たちはまだこれを知り始めたばかりですが、これが議論を呼ぶかどうかはわかりませんが、皆さんの意見を聞きたいと思います。私たちが以前持っていたものからO3への飛躍は、GPT 3.5からGPT4への飛躍よりも大きいと思います。それがアンロックした能力は、より大きな一歩前進だと想像できます。私たちは今後数週間でそれに気づくでしょう。私はこれに同意します。それは議論を呼ぶとは思いません。
「3.5から4への飛躍は素晴らしかったと思います。これは間違いなく大きな飛躍です。しかし、GPT4 3.5を考えてみてください。賢くなりましたが、それほど多くのことをしなかったと思います。ここでの能力のアンロックは大きいと思います。」
このように考えてみましょう。私たちがここで持っている小さな議論は素晴らしいものですが、木曜日にはあまり議論が起きません。3.5から4への飛躍は能力の飛躍ではなく、知能の飛躍でした。4は私たちがすぐに遊べる新しいツールを提供しませんでした。4は画像理解をもたらしましたが、私たちは4ヶ月間それを待ちました。5ヶ月間、グレッグがそれを見せて、私たちは長い間それを手に入れなかったことを覚えています。これはツールのエコシステムとすでに慣れているものに接続され、次のレベルでそれらを行います。
ツールを横断する推論、すでに持っているツールは、次のレベルで起こっています。一般の人々、単にものを使っている人々にとって、これは3.5から4に比べて、能力の大幅なアンロックになると思います。なぜなら、その当時も普通に使える中で、断然良かったからです。
O3の発表の実際のことについて話しましょう。すべてにおいて最先端です。すべてにおいて。AIM、Cold Forces、ツール付きのSweebench。Sweebenchは何パーセントでしたか?64%…いや、69%でした。以前の最先端モデルは、ツールを使用し、複数のスパンを持っていました。その一つはWeights and Biasesからのもので、もう一つはBlakeからのもので、彼らは私たちを1ポイントほど上回りました。これは、O1ベースのすべてのツールよりも9ポイント上、または5ポイント上です。これはコーディングに非常に優れています。コーディングについて推論することにも非常に優れています。
SWAnserは、Upworkベースのタスクを使用し、モデルがどれだけのお金を稼ぐことができるかに基づいて測定するOpenAIからの評価です。高い推論努力のO3(O3 high)、これはO3で高い推論努力を提供できます。O4ミニとO3は、O1が28,000ドル稼いだのに対して、65,000ドル稼ぎます。これは実世界のUpworkタスクで2倍以上のパフォーマンスです。Either Polyotは基本的に繰り返す価値がないほど明らかです。彼らが試したすべての評価において最先端です。彼らが見たすべての評価において最先端です。
一つの興味深いこと、ヤム、これを持ち出したいのですが、あなたのXで最初に見ました。注目したいと思います。長いコンテキストパフォーマンスでは信じられないほどです。これをご覧になりましたか?ニストンとウォルフラム、これをチェックする機会がありましたか?これをここに引き出してみましょう。長いコンテキストで信じられないほどです。
長いコンテキストの深い理解のための「Fiction Lifebench」というものがあります。4.1モデルが内部ベンチマークMCRCベンチマークで優れていることを話しました。このFiction Lifebenchは、120Kまでの長いコンテキスト全体のパフォーマンスを示しています。ここにズームインしてから、最初にこれを見せます。
解析が難しいこの表で、120Kでの以前の最大の勝者はGemini 2.5 Pro experimentalでした。これはGoogleが先ほどリリースしたモデルです。最初は100%の理解から始まり、4Kで97%に下がり、そして120Kでは90%前後まで低下します。他のモデルでも、40 latestは65%に下がり、40 4.1ミニは62%に下がります。O3はこれらすべての長いコンテキストにわたって100%です。4K、8K、16Kで、16Kでは88%になりますが、理由はわかりません。しかし、120Kコンテキストでも100%です。このモデルは長いコンテキストで絶対に素晴らしいパフォーマンスを示します。これもO3の追加機能の一つです。
ヤム、質問があります。アプリでそれを実際に使用できますか?Geminiでできるように900,000トークンを入れることができますか?それに応答しますか?
「それは今すぐテストして教えてくれることです。」
「テストしましょう。見てみましょう。」
木曜日について素晴らしいのは、答えを持っているだけでなく、質問も持っていて、いくつかのことを試していることです。ただ、これを絶対にテストすべきです。
「O3は最大200Kコンテキストしかありません。」
O3は200Kコンテキストのみを持っています。100万はまだありません。
最も興奮したのは、このモデルがツールへのアクセスと推論を持っているため、画像をズームインして読むことができることです。これを見ましたか?それはクレイジーでした。非常に長い画像をアップロードして、「ズームインしてこれを読んでください」と言うことができます。これは私にとってSF映画のように感じます。モデルがズームインして読み、物事を理解することができるからです。
私たちは視覚言語モデル(VLM)が画像を受け取るのに慣れています。特定の比率を提供する必要がありました。現在、彼らはパッチングを持っています。彼らはすべて分解し、視覚ヘッダーを適用しますが、すべてが画像として画像を消費します。画像の一部が欲しい場合は、アップロードする前に切り取りました。このモデルはズームインして自分自身でクロップし、異なる部分を抽出することができます。これは絶対にクレイジーです。
「うまくやりましたね。GPUの時間ごとの価格を種類ごとに取得し、インターネットのどこかからデータを収集して、各GPUの時間ごとのプロットを作るように言いました。それを実行しました。UIでこの小さなPythonのものがあり、その場で何かを実行できるのは本当にクレイジーです。小さなツールがモデルにどれだけ加えることができるかを見るのは本当にクレイジーです。」
「注目すべきことの一つは、ローカルでかなり洗練されたエージェントを実行していて、GPT 40と4.1の間のジャンプ、O3については言うまでもなく、ツールを使用する意欲の点でクレイジーです。モデル間のエージェント能力のジャンプは狂気です。それはただの、すべてのモデルがツールの出力を理解できるということではありません。一部のモデルは正しいツールを選ぶこともできますが、ループの中で何度も何度も、ツールを選び、出力を見て、次に何をするかを推測する必要があります。ループの中で、エラーは本当に速く蓄積します。もしモデルがそれを行うようにトレーニングされていなければ。4.1以前は、時間をかけて繰り返しエージェントを維持できる唯一のモデルはCla 3.7だったと思います。しかし今、OpenAIからの新しいモデルはすべて絶対にそれを行うことができ、パフォーマンスの大幅な向上が見られます。」
「私が起こると思うのは、UIで今見ているのは始まりに過ぎないということです。MCPが内部に入り、UIに埋め込まれるクレイジーなことがあるでしょう。今日、パワーユーザーである私たちは、ローカルで自分たちのセットアップとCPSで行います。誰もが自分のものを持っています。現在の流れは、人々がローカルなセットアップを持ち、YouTubeで極端な長さに至るということです。人々はローカルで極端なことを構築しています。何千ものMCPを集めていますが、それを行う意欲のある人々のサブセットです。UIで自動的にこのようなことを見ることになるでしょう。サービスが自動的に、瞬間のコンテキストに基づいて、会話全体にMCPを自動的に注入します。あなたは考える必要がなくなります。私たちが今見ているのは始まりに過ぎません。オンラインをサーフィンしてインターネットを検索できるモデルがあり、すべてのモデルが本当に短い時間でこれを行えるようになることをあなたは知っています。」
O3について言いたいことは、現在UIで見ているツール使用はまだAPIでは利用できないということです。彼らはまだこれに取り組んでいて、おそらくMCPと一緒に来るでしょうが、ツール実行APIはまだ利用できません。しかし、O3と4.1モデルには非常に近い将来に来る予定です。絶対に、彼らは提供するツールを使用できます。
このモデルの注目点は、ツール使用を横断する推論とそれから応答で戻って来ることです。さらに、マルチモデルでも最先端です。マルチモデルで最先端である理由の一つは、画像を操作し、回転させ、ズームインするなどの多くのことができるからです。MathVistaとMMUなど、ツール使用なしでも他のものを打ち負かします。
「Pythonツールを使用する場合、AIMスタッフ、競争方法はこれらのモデルに対して100%解決します。ただ推論するだけでなく、これらすべてに対してPythonを使用すれば、完全に打ち負かします。」
「解像度の画像について言いたいのは、ローカルエージェントを実行していることです。私が行うことの一つは、コンピュータのスクリーンショットを取ることです。なぜなら、私が見ているものを彼らに見てもらいたいからです。そこにはコードがあります。最近まで、Claudeだけが私のモニターに表示されているものを見て実際に読むことができました。これは解像度のためです。これは最先端であるだけでなく、場合によっては4.1がこれを行う能力があるかどうかわかりませんが、人々に言いたいのは、解像度が十分であることを確認してくださいということです。私のように、かなり大きな解像度を投げ込んで、モデルがコードを絶対に読み、Sidewinderのように一日中私を助けることができるなら、トークンに支払う意思があります。解像度も考慮すべきことの一つです。これはすでに高解像度で最先端かもしれませんが、まだテストしていません。これは重要なポイントです。人々が考慮する必要があることの一つです。」
ウォルフラムさん、あなたはライブストリームでこれについても言及しましたが、推論のコスト効率も向上しています。これらのモデルはO1を置き換えるだけでなく、Greg Buckmanは非推奨になると言いましたが、推論においてもコスト効率が良いです。OpenAIでは実際に推定推論コストを示しました。これらのモデルはより安くても、より良いパフォーマンスを示します。知能の進歩を得ているだけでなく、より安価になっています。O3はO1よりも安いです。また、O3 Proが来ると言われました。
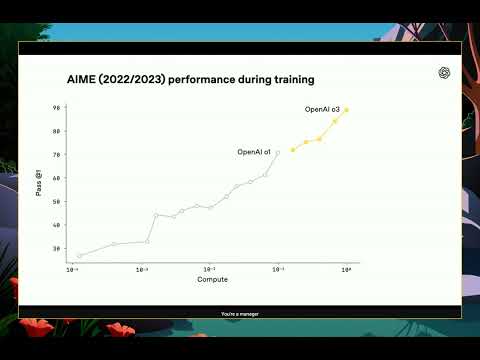
テスト時のコンピュート スケーリングの継続は見ていて美しいです。モデルのトレーニングにより多くのコンピュートが費やされるほど、AIM 2022と2023でより良くなります。これらは既に飽和しています。これらのAIMは、ツールなし、数学なし、Pythonなし、ただ推論するだけで90%の解決率に達しています。AIEを飽和させており、より難しいベンチマークが必要です。例えば、人類最後の試験は愚かに名付けられました。Scale AIリーダーボードが示しているように、O3は人類最後の試験で20%を絶対に打ち負かしました。人類最後の試験が立ち上げられたとき、「モデルが5%を超えれば驚く」と言われていましたが、O3 highは20%です。今年の終わりまでに、最後の試験も飽和すると思います。
O3についてまだ言っていないことで、他に何を言えるでしょうか?ニストンさん、O3についてのあなたの意見をまだ聞いていません。
「それをあまりテストしていません。シングルショットのデータ生成以外では。だから、それについてあまり話していません。その場合、時々作り話をすることがあるとわかりました。一般的に、一回限りのことであれば、4.1からの回答の方が好きです。しかし、もっと複雑で、マルチステップで、もっと技術的なことや計算がある場合、それは間違いなくより良いでしょう。4.1のスタイルの方がO3よりも好きですが、かなりのABテストを行いました。それらは大きく離れていませんでしたが、それだけです。」
それは理にかなっています。ほとんどをカバーしたと思います。ノートを確認して、詳細で何か漏れがないか確認し、それからオープンソースに移りましょう。昨日2時間かけてこれをしたので、ツールのコンテキストでCodexについても話しましょう。
OpenAIはCodexもリリースしました。CodexはOpenAIのCLIツールで、基本的にコマンドラインでこのモデルに作業を依頼できます。リポジトリへのアクセスがあり、フォルダへのサンドボックスアクセスもあります。実際にこれを自動受け入れで実行でき、インターネットに関連することを自動受け入れしないので心配する必要はありません。他のディレクトリにあるものを自動受け入れせず、サンドボックス化を非常によく行っているので、非常に安心できます。
私たちの中には、WindsurfやCursorなどで「ヨロよろしく」モードで、モデルに何でもさせている人もいると思いますが、これをDeepSeekで行わないでください。OpenAIモデルでこれを行ってから、DeepSeekの「ヨロよろしく」モードに行ってください。OpenAIはフォルダにこれをサンドボックス化することで、「ヨロよろしく」モードで何が起こるかを信頼する方法を私たちに提供しました。これは素晴らしいことです。Mac OSでもMac OS APIを使用していると思います。Codexもオープンソースであり、OpenAIからオープンソースが出るたびに拍手が起こります。オープンソースモデルを待っていますが、その間に実際のオープンソースをたくさん得ました。彼らは評価、MRCAや他の評価も提供し、Codexを完全にオープンソース化しました。
質問が来ています。CLIがどのように機能するか説明できますか?例を示すのが最良の方法だと思います。
「これについて何時間も話せます。本当に話したいなら、たくさん話すことがあります。基本的にはこのようになります。知らない人のために、1ヶ月前にCloud Codeがリリースされましたが、それは本当にクレイジーです。真剣に、Cloud Codeは素晴らしいです。しかし、すぐにCloud Codeについて話します。基本的には、コマンドラインで何かを尋ねるだけです。UIを通して話すかのように、何でも尋ねることができます。それは許可を持っており、あなたのコンピュータで物事を実行できます。基本的にあなたのコンピュータを持っており、ツールを実行し、ファイルを編集し、望むことを何でもできます。ループで実行され、あなたが言ったことを行おうとします。」
「Cloud Codeについては、本当に素晴らしいです。本当に素晴らしいリリースでした。本当にありがとうございます。もちろん、Cloud CodeはO3を使用していませんが、これにはO3のネイティブ使用が組み込まれています。まだツール使用はありませんが、物事について考えます。」
39秒間、このリポジトリについて考えていました。私はインストールしたことを覚えていませんでした。ユーザーがリポジトリの目的について尋ねました。ここで思考も見ることができます。簡単に言うと、このリポジトリは完全な機能を持つAIエージェントであるWinstonです。大規模言語モデルアシスタントとチャットできます。リポジトリとコード、READMEからこれをすべて理解しました。基本的に、npmを介してインストールでき、オープンソースであるCLIであなたと一緒にAIコーディングエージェントであることを示しました。コミュニティも貢献できます。
すでにMCPサポートを追加し始めている人々を見ました。ちなみに、CodexでCodexサポートを追加しています。CodexはMCPサポートを追加します。ショーに出演したJasonに感謝します。これも実現すると思われます。非常にクールです。
「人々がこのようなコマンドラインツールを実行する場合、新しいアカウントを作成してください。Macに新しいアカウントを作成してください。自分のものに置かないでください。あなたのSignalチャットにアクセスでき、添付ファイルも見ることができます。新しいアカウントを作成し、非管理者ユーザーを使用してください。Codexは聞くことができません。ファイルに入ることはできますが、これは別の会話です。」
OpenAIが約束したところによると、少なくとも自動受け入れモードは非常に優れています。しかし、そのベクトルを開いたままにしているので、非管理者アカウントを作成し、その非管理者アカウントは、LinuxまたはMac上のメインアカウントにアクセスできないようにしてください。
責任あるニュース媒体として、これらのモデルがあなたのものを実行する可能性があることについて警告する必要があります。特にMCPを使用している場合、MCPはいくつかのプロンプトで注入される可能性があります。何が起こり得るかを認識すべきです。また、「ヨロよろしく」モードを聞いている人々のほとんどがこれを行わないことも言わなければなりません。彼らはそうしないでしょう。
私たちは大企業とAPIの時間切れになったと思います。すべてを非常によくカバーしたと思います。聞いている皆さん、O3についてまだカバーしていないことや、ユースケース、プロンプト技術、その他のことがあれば、コメントでお知らせください。EQBenchの評価を持っているSam Peachが今Twitterスペースにいるのを見ています。O3もクリエイティブライティングにおいて最高の一つであることを示しています。それもクレイジーです。EQBenchについても知っておくべきです。クリエイティブライティングについて話し、O3もクリエイティブライティングにおいて素晴らしいです。
O3が他のモデルより優れていないことを見ることはありません。おそらく速度とO4ミニ、これについてはほとんど触れませんでしたが、実際にはこのリリースの隠れた宝石かもしれません。O4ミニも多くのことで素晴らしく、はるかに速く、安価です。
「オンラインでは、モデルが急いでリリースされたという意見があります。他のモデルでは起こらなかったような狂気のような幻覚があるため、その意見があります。いくつかの答えは疑問視されるものがあると言えますが、それは巨大なリリースです。もう少しバランスを取るために、他の意見にもステージを与えたいと思います。気になる場合は、チェックしてみてください。おそらく、トレーニングにこれほど多くのトークンを詰め込むことには代償があります。それを調査している人々もいます。」
「コマンドラインツールについてもう一つ言いたいことは、これはコーディングだけのものではないということです。私は少し極端に行きましたが、過去1ヶ月間、ほぼすべてのモデルをコマンドラインツールを通じて使用しました。なぜなら、考えてみてください。彼らは今Perplexityにアクセスし、オンラインに行き、私のコンピュータをチェックできます。他のエージェントやクライアントができない、特にあなたのコンピュータで実行されているものでは、はるかに一般的なことを尋ねることができます。「カレンダーをチェックしたか」「今日はどんな会議があるか」「デスクトップをどうやって整理できるか」「ファイルが多すぎる」などの日常的なことでも、開発者でなくても、これらのことは本当に強力です。」
オープンソースに移りましょう。大企業とAPIについてはすべてカバーしたと思います。これはAI世界の大企業とAPIにとって大きな一週間でした。オープンソースについて少し話し、その後Toddと非常に近い将来チャットする予定です。Nはより早く退出する必要があることを知っています。ではオープンソースに移りましょう。
オープンソースAIを始めましょう。オープンソースの更新はそれほど多くないので、通常オープンソースに費やす時間ほどは費やしませんが、木曜日ではオープンソースも大好きです。他の画面を共有しましょう。オープンソースで持っているものについて話しましょう。
まず、これについて少し話しましたが、OpenAIは何かをオープンソース化しました。複数のものをオープンソース化しました。Codexはオープンソースであり、Seanから聞いたところによると、24時間以内に多くのPRを受け取りました。オープンソースは素晴らしいです。24時間以内に60のPRがマージされました。それは絶対にクレイジーです。
また、OpenAIからはMRCR長いコンテキストベンチマークのオープンソースも見ました。これがどのように見えるか見てみましょう。かなり素晴らしいです。このデータセットは長いコンテキストベンチマークをテストし、望ましいインデックス、合計メッセージなどがあります。MRCRから選択した2,400行があります。以前は間違えていました。EnthropicのものではなくGeminiによって最初に導入されたものだと思いました。それからOpenAIがタスクの難易度を拡大し、結果を生成するためのオープンソースデータを提供しています。
このタスクは、以前は単なる論文でしたが、今はOpenAIからのオープンデータセットとして登場しています。こんな感じです。ユーザー、アシスタント、ユーザー、アシスタント、ユーザー、アシスタント、そして二つの干し草の中の針などの会話があり、非常に難しい質問をします。例えば「ユーザーが話した2番目の話は何でしたか?」例えば岩についてなど、またはバクについてなど。彼らは何らかの理由で動物、特にバクが大好きで、ライブストリームでも言及していました。
基本的に、ベンチマークは、モデルに難しい質問を尋ねることによって機能します。それらは干し草の中の針の質問だけではなく、複数の会話内のコンテキスト質問でもあります。これは非常に素晴らしいことです。もしMRCRのリーダーボードを構築したい場合は、ぜひそうしてください。このイーバルは現在組み込まれています。もしWeights and Biasesのweaveを使用したい場合も、それも可能です。
オープンソースでは、マイクロソフトが静かにBitNet v1.5をリリースしました。ヤム、Bitnetについて簡単に一文で説明できますか?Nか誰かこれを引き受けてくれますか?
「あと3分で行かなければならないので、手短に説明します。Bitnetが人々を興奮させる理由は、チップ上で1.5ビットがある場合、三値演算子があるので、ゼロと1だけでなく3つの値を持つ場合、行列乗算を行うために乗算の代わりに加算を使用できるということです。理論的には、チップが作られたときに大きな改善があるはずです。このリリースについて言いたいのは、ついにトレーニングする努力をしたことに感謝していますが、人々がBitnetについて持っている誤解に対処したいと思います。
マイクロソフトがハギング・フェイスにリリースしたGGUFファイルを見ると、それは24億または27億パラメータのモデルですが、GGUFファイルは1.8ギガになっています。これがBitnetsの主な問題で、最後の重み、大きな出力の重みはF-16に保持されています。さもないとモデルは劣化します。トークン埋め込みの重みもF-16に保持されています。モデルの残りの部分が三値である一方で、最後の重みはフロート16にあり、最後の重みはモデル全体よりも大きくなります。そのため、重みあたりの実際のビット数を計算すると、それはより7ビットに近く、ベンチマークにとってはそれほど印象的ではありません。もし彼らが出力重みを4ビットに移行するか、またはそれを2ビットか3ビットにして、モデルの残りの部分を三値にすれば、それはより真のビットに近くなるでしょう。しかし、完全に三値の本当のビットはまだ存在しません。これは人々がBitnet一般について持っている大きな誤解です。」
ニストンさん、ありがとうございます。そして、知識を共有してくれてありがとうございます。ジャンプする必要があることを知っています。ありがとうございます。
オープンソースの更新をもう一つ簡単に。Prime Intellectは、強化学習で32億パラメータのモデルをトレーニングしました。完全にグローバルに分散されています。これは非常に素晴らしいことです。Prime Intellectについて話しましたし、同様のことを試みているニュース研究者についても話しました。Intellect 2は、強化学習と推論のある最初のグローバルに分散された30億パラメータモデルを立ち上げています。Intellect 2と呼ばれています。これを実際に使えるかどうかはわかりませんが、彼らはシステム全体を分解しました。私たちは今、家の人々も参加できる分散トレーニングの端にいると思います。これはとても素晴らしいことです。
最後の一つはZ.AI、Z.AI、Z.AIです。以前のChat GLMがGLM4をリリースし、非常に良いものです。最先端のような更新を見ていませんが、彼らの32億パラメータの性能はQuen 2.572Bに非常に近いと主張しています。数学とコード、長文解析のための特別なRLSを持っています。これをMITライセンスでリリースしました。Z.AIにこのリリースに感謝します。9億から32億パラメータまでのチェックポイントをたくさんリリースしました。コード生成、関数呼び出しなどに優れています。リブランドと、MMLU、GSM、Human evalなどにおける72億パラメータモデルとの同等性に感謝します。
他にもカバーすべきことがたくさんあります。特にショーの最後にはビデオモデルについて非常に簡単に触れる予定ですが、今は今週の話題に移り、トッド・シーゲルとのインタビューもあります。
トッド、ショーへようこそ。初めてですね。こんにちは、いかがですか?
「ありがとうございます。」
お越しいただきありがとうございます。今週の話題というセグメントに移ります。A2Aプロトコルの立ち上げパートナーとしてWeights and Biasesの視点からもニュースをもたらし、あなたもそのショーに参加しています。あなたとのA2Aプロトコルについてチャットするのを非常に楽しみにしています。今週の話題に切り替え、何かを非常に簡単にカバーし、その後GoogleのA2Aプロトコルに取り組んでいるトッド・シーゲルとの会話をします。
みなさん、こんにちは。木曜日のカテゴリで、このショーのスポンサーであるWeights and Biasesに関する新しく非常にクールなすべてについて話すセグメントです。ご存知のように、私はAIエバンジェリストです。これは、モデルについて話し、ショーをホストしますが、素晴らしい機能についても話すことを意味します。木曜日の頻繁なリスナーであれば、weaveというLLM観測性と評価のための製品があることをご存知でしょう。これは、今週のような週や今日のような日に、すべてのモデルがリリースされ、「どのモデルを使えるのか」と思うときに非常に重要です。
現在、プレイグラウンドで新しいモデルをサポートしています。プレイグラウンドは、本番環境で発生したトレースに基づいて比較できる場所です。そこに行って「同じ呼び出し、同じエージェント呼び出しなどを、エージェントが来た全状態を含めて、別のモデルで試したい」と言うことができます。モデルを切り替えて比較し、「このエージェントがO3やGeminiなどで実行された場合、何が起こっただろうか」と言うことができます。Weights and Biasesプレイグラウンドは、それらすべてをサポートしています。後でこれをお見せします。
Weights and Biasesでは、A2Aプロトコルのランチタイムサポートもあります。A2AはGoogleから多くのサポートパートナーと共にリリースされたプロトコルです。私たちはGoogleのA2Aプロトコルのために50以上のサポートパートナーの一つです。このプロトコルはエージェント間通信に関するものです。先週プロトコルが出てきたときにこれに触れ、サポートをローンチしました。深く掘り下げたいと思います。私はプロトコルを読み始め、私たちに来るエージェントのインターネットと、これがどのように影響するかについて考え始めました。
明らかに私たちもMCPに熱心です。そのため、A2Aプロトコルについて深く理解するために、そして違いについて話すために、ここにGoogleのトッド・シーゲルがいます。トッド、ショーへようこそ。これがあなたの初めてのショーなので、知らない人のために、簡単に自己紹介をお願いします。そして、取り組んでいることについて話すことができます。
「ショーに招待してくれてありがとうございます。ビデオになっていることを今まで知りませんでした。これは素敵な驚きです。私の名前はトッド・シーゲルです。Googleで働いています。AIプロトコルに取り組んでいます。MCPとA2A、エンタープライズ情報と個人情報などとエージェントを接続する作業をしています。エージェントの周りのシステムにも。」
部屋の中の前述の象について言及しましたね。MCPについて多くの人が戸惑いを見せています。まず、Googleは公にMCPプロトコルをサポートしていると発表したことを言及すべきです。サヌンドとディスハビスの両方がMCPをサポートすると言ったと思います。例、クックブックなどがあり、さらにサポートがある予定です。あなたは両方に取り組んでいると言いました。A2Aが出てきて、仕様ウェブサイトに行かなかった人々が、「A2AがMCPを補完する方法」というセクションを読まなかった人々が、「なぜ別のプロトコルが必要なのか、MCPですべてが解決する」という即時反応をしました。
そこから始めてみましょう。A2Aプロトコルとは何か、そして人々が非常に興奮しているMCPプロトコルとはどう違うのでしょうか?
「簡単にまとめると、MCPとA2Aは補完的なものだと考えています。MCPはエージェントとツールを接続するためのもので、A2Aはエージェントとエージェントを接続するためのものです。ツールは構造化されており、非常に特定の目的のためのものです。正確な制御が可能で、非常に特定のことを行い、それを非常にうまく行います。そして多くの場合、それは決定論的に行います。エージェントははるかに予測不可能で、知らなかったことを行うことができ、また時間の経過とともにエージェントとの対話は変化する可能性があります。」
「対話が時間とともに変化する可能性があるというのは非常に興味深い攻撃ベクトルです。過去1週間で人々が非常に心配していたのは、MCPツールの発表で、MCPツールをインストールした後、ツールの定義を変更できるスタッフィング攻撃がありますが、あなたはすでにMCPをインストールしています。」
ここでのフォローアップ質問は、エージェンティックツールがMCPを通して自分自身を公開するとは予見していないのでしょうか?それとも違う形で予見しているのでしょうか?技術的にはこれを行うことができるだけでなく、あまりこの点を強く押したくはありませんが、MCPにはA2Aがあります。MCPはこのサマリーサーベイプロトコルも持っています。LLMチャットボットなどにあなたのために何かを完了するよう依頼できます。MCPも技術的にはエージェント能力の一部を公開していますが、まだそれらが実装されるのを見ていません。サンプリングと呼ばれていると思います。
MCPがエージェンティックツールも受け入れると予見していないのですか?そして、これは線引きをして「ツールにはMCPを使うべきだが、エージェントは別のカテゴリであり、異なる扱いをすべきだ」と言うための試みですか?
「いくつかの異なる懸念があり、異なるアクターがそれらと対話していると思います。エージェント対エージェント側では、サービスのように構造化されています。エージェントAがエージェントBに話しかけ、「旅行の予約を手伝ってほしい」と言います。それは多くの異なる方向に行くことができます。エージェントからの質問が行き来したり、より多くの情報を求められたり、「行きたい場所の写真を見せてください。時間の制約を教えてください。予算を教えてください。」などと言われることがあります。そして、ツールで特定的にモデル化することが非常に難しい非構造化情報が行き来します。
MCPと比較すると、モデルには非常に特定の能力に対する正確な知識があり、モデルが推論し、非常に特定のパラメータでツールを呼び出すことができるようにします。そのため、MCPはモデルレベルのプロトコルであり、A2A側はアプリケーションレベルのプロトコルだと考えています。」
「アプリケーションレベルのプロトコル、それが好きです。私がエキサイトすることの一つは、MCPでツールをチャットボットに提供するとき、開発者として私は発見を行います。それが必要とするものを知っている、または知っていると思っています。最近、MCPのためのMCPなどの試みがいくつか見られましたが、それは私を怖がらせます。なぜなら、MCPがこのために構築されたとは思わないからです。
デビッド・ソラやMCPに取り組む他の人々とLatent Spaceでのチャットを覚えています。彼らもツールを非常に特定のものとして考えています。すべてを行うツールを推奨せず、スコープを絞り込むことを推奨しています。そうすればコンテキストは限られた追加のみを持つことになります。A2Aで非常に興奮したことの一つはレジストリのコンセプトです。これについて少し話していただけますか?」
「私たちがA2Aを構築した理由の一つは、人々が専門化されたエージェントを多く構築し、これらの専門化されたエージェントの構築を非常に深く行っていることを見ているからです。ドメイン固有のエージェントは、すべてのカスタム専門知識、カスタムragソース、カスタムツール、プライベートAPI、ドメインスペシャリスト外で公に公開されていないプライベートデータを持っています。
そのため、すべてのエージェントを登録できる一種の中央リポジトリを持つこと、またはウェブクローラーがすべてのエージェントにアクセスできること、そしてこのタスクを解決するための最高の専門家、自分と対話するための専門家を見つけることができるサービスを持つことは、特定の仕事をするために人間を雇おうとするのと非常に似ています。特定の契約者を雇おうとしたり、特定のカテゴリの専門家を雇おうとしたりするようなものです。それに対して、私は手で物を作ったり、インストールしたりすることが得意ではないので、そのために人を雇います。専門家が使用するツールを私に与えることは、私にとって役に立ちません。」
少し技術的になりましょう。その通信はどのように行われるのでしょうか?私のエージェントがこのレジストリと話すとき、スキーマはどのように見えるのでしょうか?フードの下ではどのようになっていますか?何を使用しますか?実際、効果的に、このようなエージェントのマーケットプレイスがあり、私のエージェントがアイデアなどを求める世界をどのように想定しているのでしょうか?
「エージェントレジストリはロードマップ上のものです。現在プロトコルによって可能になっていますが、まだリリースしていません。現在、A2Aではエージェントがカードを公開します。それはビジネスカードや履歴書、能力カードのようなもので、エージェントが行える種類のことを説明し、対話する方法の例を示し、話せるモダリティの種類を示します。例えば、「画像を送れる」「ドキュメントを送れる」「iframeで返信する必要がある」「ビデオフレームで返信する必要がある」などです。
私たちのロードマップに来る考えは、多くのレジストリがあるだろうということです。公開レジストリは興味深いもので、robust.extのようなレジストリはテキストで、ウェブクローラーがエージェントを見つけることができるか、ブラウザがウェブサイト上で利用可能なエージェントを見つけることができます。また、アプリストアやエージェントストア、エージェントガーデンのようなもので、プライベートエージェント、自分やあなたの組織、チームによってキュレートされたエージェントなどもあるでしょう。これらも企業内に登場するでしょう。
レジストリサービスを積極的に検討しています。複数のエージェントがあり、エージェントカードでは各エージェントに「誰がこの特定のタスクを処理するのに最も適しているか」と尋ねることができます。特に、エージェントが重複するタスクを実行できる場合や、異なるコンテキストを扱っている場合でも、似たようなタスクを実行できる場合などです。
一例としては、GitHubとGitLabを交互に使用する企業があり、両方のエージェントがありますが、GitHubとGitLabはツールの例でもあります。エージェントはより多くのことを行って戻ってくることができるものです。タスクプロトコルについても話したいです。また、非同期と同期の例もあります。エージェントは長い脇道に行くことができますが、プロトコルはどのようにタスクと非同期を処理し、答えを持って戻ってくるのでしょうか?特に、Geminiは推論モデル、2.5/3は推論モデルであるという時代において、これらの推論モデルは時間がかかり、エージェンティックなことも行います。エージェントがこれらの上に構築されると、単にタスクを実行するのに時間がかかります。A2Aプロトコルはどのように非同期性とタスク処理、オフロードを処理するのでしょうか?」
「A2Aは元々、これらの非常に複雑で長時間実行されるタスク用に設計されました。例えば、店に注文を出したいとします。店は質問をしたいかもしれませんし、質問をして「割引が受けられますか?」と尋ねるかもしれません。店はマネージャーに確認する必要があるかもしれないと言い、それには1日かかるかもしれないし、部品サプライヤーに連絡する必要があるかもしれないし、何をすべきかを考えるために他の誰かに連絡する必要があるかもしれません。これは数秒だけでなく、分、時間、日、週かかる可能性があります。車の修理や、多くのベンダーが関わる非常に複雑な旅行の予約などです。
そのため、はい、タスクと呼ばれる中心的な抽象化があります。それは安定したエンティティです。両側のエージェント、つまりクライアントエージェントとサーバーエージェントが協力している目標を表します。クライアントはコンテキスト情報と何が起こるべきかの説明をサーバーエージェントに送信します。サーバーエージェントは、作業中のものと、もし何かもっと情報が必要な場合に応答します。また、レスポンスを生成しながら、それらをストリームバックすることもできます。リモート側が情報をもっと必要としてブロックされている場合、クライアントに「この構造化情報を提供してほしい」または「もっとドキュメントを提供してほしい」または「もっと情報を提供してほしい」と信号を送ることができます。
私たちが見ている新たな使用法は、実際には予測されていなかったことですが、人々はA2Aをアプリ対エージェントプロトコルとしても使用しています。エージェントではないアプリがあり、それをエージェントと話せるようにしたいのです。エージェントと容易に通信できるようにしたいのです。そのため、より素早い会話アクセスのためのサポートを追加することを検討しています。」
「アプリ対エージェントはエージェント対エージェントとは異なるのですね。」
「能力発見についても話しましたが、これは非常に重要だと思います。会話はもはやテキストだけではありません。エージェントはテキストタスクだけを実行しているわけではありません。木曜日に私たちが話すようなビデオAI生成などもあり、それらは時間がかかる場合があります。7つのビデオを作成してレビューするなどの作業をしたいかもしれませんし、リップシンクのエージェントなどと接続したいかもしれません。しかし、これを見たいのです。能力発見がありますが、また「どの言語を話しているか」の発見もあります。これについて簡単に言及しましたが、モダリティの種類について話していただけますか?テキストだけではないことは非常に興味深いと思います。iframeに言及しましたし、ビデオフレームにも言及しました。」
「はい、テキストは今日最も優勢なモダリティですが、異なるモダリティで動作するモデルだけでなく、エージェントも多く見ています。そして、それらはカスタムブランド体験も持っています。エージェントが自然なモダリティで通信できるようにしたいと確かに考えています。オーディオのみやビデオのみのエージェントがある可能性があり、それらはプロトコルを通じてそれを交渉できるはずです。テキストから始めて、オーディオやビデオに移行したい場合もあるでしょう。「パスワードをリセットするのを手伝ってほしい」と作業ヘルパーエージェントに尋ねるシナリオを考えることができます。そして「アイデンティティ検証を行う必要があります。あなたとアイデンティティプロバイダーとのビデオストリームを開始する必要があります」と言われるでしょう。
また、ビジネス上の理由や信頼の理由、関係の理由で、エージェントが自分のブランド体験をユーザーの前に持っていたい場合もあります。そのエージェントは「すべてのコンテンツをレンダリングする必要があります。HTMLのiframeを提供する必要があります。そこでレンダリングします」または「フレームを提供します。それを埋め込むことができます」と言うかもしれません。本当に両方のエージェントが与えられたタスクに対して正しいモダリティが何かを決定することになります。」
これが組み込まれていることが大好きです。特にiframeの領域ですが、ビデオやモダリティの領域でも多くのイノベーションが見られると思います。これは非常に刺激的です。しかし、パスワード変更エージェントに言及しましたが、これは一般的なプロトコルとセキュリティと認証についての次の会話に移ります。これは非常に重要な部分だと思います。なぜなら、レジストリについて言及し、エンタープライズのユースケースについても言及しました。エンタープライズ内部で、私がエンタープライズのITプロバイダーとして、組織全体に使用させるために複数のエージェントを公開するようなケースです。これらは組織のauth scopeに閉じ込められるでしょう。
プロトコルでセキュリティと認証をどのようにアプローチしているか話していただけますか?扱われるものは何ですか?プリミティブはありますか?そして、アイデンティティとスコープなど、これらすべてのことはどのように機能するのでしょうか?
「それは素晴らしい質問です。コアデザイン原則の一つは、特にエンタープライズの準備状況に関して、認証、トレースなどに関して、私たちは新しいものを発明したくないということです。世界に存在するすべてのものと連携することを確実にしたいのです。そのため、基本的に二つのサービス間の点対点プロトコルとして設計しました。複数のアイデンティティを持つ代わりに、多くのプロキシを通じてファンアウトしたり通過したりする代わりに、クライアントとサーバーをエンタープライズ内の通常のアプリケーションまたはサービスとして扱いたいと考えています。
そのため、アプリケーションアイデンティティとユーザーアイデンティティを持ち、標準のOAuth、標準のIDP、標準の内部エンタープライズ認証が意図的に動作するようにしています。アイデンティティ情報はプロトコルのペイロードには含まれておらず、HTTPに含まれています。HTTPヘッダーに含まれています。」
つまり、ユーザーとして、開発者ではなく、特定のスコープとGoogleグループでアクセスできるJiraとGmailの特定のエージェントがあるとします。プロトコルを介して他のエージェントにこれを委任できるでしょうか?そうすれば、サーバーエージェントが私の名前で、私のスコープでタスクを実行できるようになりますか?
「起こることは、あるエージェントを使用していて、そのエージェントがJiraエージェントと協力したいとき、Jiraエージェントはプロトコル内で「ここにはあなたのユーザーから必要なアイデンティティ情報があります」と返答します。あなたのアプリケーションは「Jiraにログインしてトークンを取得する必要があります」と言うでしょう。OAuthを使用していると仮定すると、それは標準的なOAuthプロセスで、私はユーザーとしてよく知っています。そして、標準的なOAuthフローでJiraに進み、あなたのエージェントがあなたの代わりにJiraと話すことを承認します。そして、それらはHTTPヘッダーで渡されます。「これはあなたのユーザーID、これはあなたのベアラートークンです」などが、A2Aリクエストを実際に変更するためのHTTPヘッダーにあります。
OAuthのハンドシェイクをバンドの外で行い、サービスプロバイダーが要求する任意のアイデンティティ管理作業、IDPとの作業など、プロトコルの外で行います。そして、HTTP ヘッダーで認証情報を持ち運びます。」
「バンドの外」とはどういう意味ですか?それを説明していただけますか?
「A2Aで認証情報を取得するために、OAuthのハンドシェイクは行いません。その代わり、A2Aサーバーが「ここに認証情報を取得する必要がある場所があります」と言います。任意の認証スキームやプロトコルをサポートします。それがOIDCか、OAuthか、SSOか、独自のものかもしれません。そのアイデンティティプロバイダーと直接連携して素材を取得し、その後の A2A リクエストに含めることができます。」
それを聞いて良かったです。少し前進して、ガバナンス、中立性、これらすべてのことについて話したいと思います。プロトコルを採用することを考えている多くの人々にとって、ベンダーの中立性は非常に重要です。しかし、標準団体などもあります。ガバナンスと標準団体についてどのように考えていますか?異なる企業からのプロトコルへの提案や提言についてどのように考えていますか?あなたの現在のアプローチと考え方をお聞かせください。
「現在、A2AはGoogleのGitHubリポジトリにあります。物事が安定したら、コミュニティ所有のリポジトリに移行する予定です。おそらくLinux Foundationのようなところかもしれませんが、まだ確定していません。完全にオープンなガバナンスモデルを持つ予定です。これはゲートキープしたいものではありません。これは業界と消費者の両方の最善の利益のためのものです。すべてのエージェントが実際に協力できるようにし、プロトコル戦争や会社Aが特別な機能によって会社Bに対して競争優位を持つようなことがないようにしたいのです。これが標準となり、迅速に標準となることを本当に望んでいます。そしてオープンガバナンスを持つことを望んでいます。Googleにはそのようなことが起こる長い歴史があると思います。」
プロトコル提出について言及しましたが、話すことができる範囲内で、これがすでにGoogle内でどのように使用されているか、またはこれがすでにGoogle内で使用されているかどうかについて話していただけますか?また、すでにこのプロトコルを使用している、または構築している他の企業についても話していただけますか?見てきた実際のユースケースや例について話していただけますか?
「先週のGoogle Nextで、エージェントスペースという製品を発表したと思います。これは一般的に利用可能になり、会社内部の検索エンジンです。そしてエージェントも持っています。また、コードが不要なエージェントビルダーと、そこにサードパーティのエージェントをホストする能力も持っています。エージェントスペースはA2Aを採用し始めています。ある時点で、エージェントスペースのすべてのエージェント対話はA2Aになるでしょう。
エージェントスペースは多くのパートナーとも協力しています。異なるプラットフォームでエージェントを構築でき、好きなフレームワークで構築できます。LangChainで構築することも、Crew AIで構築することも、Salesforceのようなローコードやノーコードベンダーから構築することもでき、それらすべてがエージェントスペースで機能します。その仕組みは、すべてがA2Aを話すことです。エージェントスペースが実際に行う必要がある重い作業はあまりありません。Googleの他の製品もA2Aを採用し始めています。今はその名前を言いたくありません。なぜなら、彼らがいつ発表するか、何を発表するかわからないからですが、Google内部にも多くの勢いがあります。」
素晴らしいですね。私たちはこれを見るのを楽しみにしています。また、明らかに私たちもこのサポートパートナーの一つです。クライアントエージェントの開発者、たとえばですが、への透明性について、プロトコルレベルでどのように考えているかについてお聞きしたいと思います。少なくとも私たちの懸念の一部は、私が開発者として構築したクライアント、私が開発者として構築したエージェントの外部で起こる物事が多くなるほど、何が起こっているかを観察する能力、デバッグする能力、評価する能力、ユーザーがどのように対話しているかを見る能力が少なくなるということです。
私たちはホテルを開設し、MCPもサポートしました。開発者のためのこのカテゴリの問題について考えたことはありますか?もしあれば、A2Aでの開発と開発者体験がどのようになるかについての現在の考えを教えてください。
「絶対にその通りです。それはエンタープライズの懸念の一つであり、運用可能性の懸念でもあります。サービスのメッシュがあっても、それらを観察できなければなりません。キーワードはサービスです。私たちはエージェントを、マイクロサービスや組織間のサービスなど、標準的なサービスとして扱っています。そのため、OTELはただ機能します。HTTPクライアントを計測し、SDKを計測してください。SDKを構築する際に、最初からOTELサポートを絶対に入れる予定です。それぞれのインストールでカスタマイズでき、必要な場所に記録できるようにします。
私たちが設計に入れたいと思っている単純さの重要な機能は、普通のクライアントサーバーアプリケーションのようにモデル化し、すでに存在するものをすべて使用することです。新しいものを発明しないでください。」
OTELは、聞いている人々のためには、Open Telemetryと呼ばれる別のオープンプロトコルで、Weights and Biasesのweaveや他のサービスが複数のサーバーからテレメトリを収集し、開発者が見ることができるものにコンパイルする方法を特に規定しています。
パネルのヤムからの質問があります。エージェントの失敗ケースをどのように定義しますか?LLMの世界では、幻覚が起こったり、失敗が起こったり、エラーが起こったりすることがあります。クライアントまたはサーバーエージェントはどのように「これができなかった」と通信し戻すのでしょうか?また、時間の経過とともにどのように通信しますか?「これをしようとしています」そして「失敗しました」などの進捗更新はありますか?エージェントが希望通りに正確に動作したという定義はありますか?そして進捗状況についてはどのように更新されますか?
「それはタスク抽象化の中核にあり、それは2つのエージェント間の通信中の主要なオブジェクトです。タスクは状態を持ち、状態はサーバーエージェントによって設定されます。サーバーエージェントはさまざまな更新で応答でき、それらは一般的に2つのカテゴリに分類されます。メッセージとアーティファクトと呼ばれるものです。アーティファクトは、発生しているタスクの正式に生成された結果です。1つのリクエストに関連するアーティファクトが複数あるかもしれません。例えば、7つの画像が欲しい場合、各画像は独自のアーティファクトになります。
メッセージはそれ以外のすべてのためのものです。思考かもしれないし、ステータスかもしれないし、より多くの情報のリクエストかもしれません。公式なステータスには「失敗しました」や「完了しました」や「もっと情報が必要です」などがあります。「こんにちは」とは言いませんが、今気づきましたが、ステータスは失敗です、ステータスは完了です。ステータスが完了していても、クライアントはアーティファクトの結果、エージェントが生成したものの結果を評価し、それが十分に良くないと判断し、例えば、「ウサギの画像を作成してください」とエージェントに言うクライアントの例があります。エージェントはウサギを生成し、それをストリームバックして、クライアントに送信し、「タスク内で完了しました」と言います。そしてクライアントは「いいえ、赤にしてほしい」と言うことができます。これによって他の側でタスクが再活性化されるはずです。タスクは完了から作業中に移行し、物事がストリームバックされ、再び完了し、赤いウサギの画像という新しいアーティファクトが得られます。状態はタスクに含まれ、両側がメッセージを互いに送ることができます。」
プリミティブのほとんどをカバーしたと思います。認証部分があり、プロトコル内で再発明したくないものや標準的なサポートされたエンタープライズのものを持つというセキュアなコラボレーションについてもお話しました。プロトコルの上に乗せて、クライアントエージェントを通して、サーバー・クライアント、クライアントエージェント、そしてサーバーエージェントを通して私の証明書を公開することになります。タスクと状態管理についても話しました。継続的な非同期タスクが発生し、通知はまた後方にも発生するということです。もし私のエージェントやクライアントアプリケーションがiOSアプリや通知を通じて私に通知する能力を持っているとすれば、サーバーエージェントの動作について知らせてもらえるということです。これが通知です。
「プッシュ通知機能、通知が別の機能です。クライアントはタスクを作成でき、サーバーは結果をストリームバックしてステータス更新を提供できますが、特に数時間や数日かかる可能性がある非常に長時間実行されるタスクの場合、クライアントとサーバーが常に接続されていることは想定していません。代わりに、クライアントはサーバーが更新を送信できるプッシュ通知サービスを提供することができます。これには別の認証許可セットが必要です。なぜなら、サーバーがクライアントになるからです。私たちの仕様には詳細がありますが、アイデアは、サーバーエージェントが状態を変更したり、アーティファクトを生成したりする際に、クライアントから切断されていても、クライアントが何らかの通知コールバックを提供していれば、サーバーはそこに結果を投稿できます。」
それはプロトコルに組み込まれていますか?それとも、例えばiOSやAndroidのもの、またはウェブワーカーのものを記述していますか?
「それはプロトコルに組み込まれています。」
基本的に、プロトコル内で、クライアントエージェントを構築し、3日かかるエージェントと話したい場合、例えば車を修理するために人間を待っている場合や、「あなたの車を修理してください、取りに来てください」という通知を送る場合、プロトコル上で発生するライブ接続はどうなりますか?実際のところ、3日間まっすぐ維持される必要はありません。これも企業にとっては非常に難しいことです。MCPの問題の一つも、ステートレスかステートフルか、この接続をどれくらい維持するかということでした。A2Aには通知サービスが組み込まれています。あなたが簡単に言及したことを確認したいのですが、クライアントがサーバーになり、サーバーがクライアントになるというのは、プッシュ通知通信のみを指しますね?なぜなら、この場合、クライアントとして「通知の送信先はここです」と開き、サーバーエージェントがそれを購読して通知を送り返すからです。そのレベルだけですね?
「はい、通知の場合のみです。認証許可の観点からより重要ですが、ポートを開いて「ここに更新を送ってください、ここにクッキーがあります」というのは本当に危険です。それは可能ですが、高度に推奨するのは、通知サービス(クライアント自体ではないかもしれません、内部的に何かをpubsubキューに投稿するものかもしれません)が、サーバーエージェントを完全に認証し承認することです。」
トッド、時間に気をつけることを約束しました。数分過ぎていますが、最後の質問です。プロトコルについて私たちがカバーしなかった重要なことはありますか?私が質問しなかったことはありますか?また、人々はどこで詳細を知り、どのように実際に使い始めることができますか?
「GitHub プロジェクトに行ってください。github.com/google/a^2aだと思います。多くのPRがあり、多くのオープンな問題があります。オープンな議論をたくさんしています。正式なSDKと正式な本番リリースに向けて、オープンに進化させ続ける予定です。そして、より多くのGoogleプロダクトが出てくるにつれ、より多くの業界パートナーと協力して、より多くの例を得て、より多くの製品を持つにつれて。試してみて、フィードバックを送ってください。PRを送ってください。私たちはコードが大好きです。」
トッド、ありがとうございます。あなたとGoogleでこれに取り組んでいるチームに感謝します。
皆さん、これが聴衆の方々にも役立つことを願っています。ヤムが言ったように、今はこれを使うことはできません。SDKはまだ開発中ですが、MCPプロトコルでも同じことが起こりました。去年の感謝祭にこれについて話したことを覚えています。昨年、これを発表しましたが、あまり言うことはありませんでした。実装はあまりなく、最近になってMCPが絶対に爆発しました。すべての大手プレーヤー、Google、Microsoft、GitHub、Anthropic、OpenAI、すべてがMCPをサポートするようになりました。
プロトコルの採用には時間がかかります。ユーザー、開発者、企業の臨界質量が必要です。Googleは正しいことをしているように見えます。そして、今後何が来るかについての洞察をこれが少し与えてくれることを願っています。今後6ヶ月から8ヶ月から12ヶ月の間に企業に来るものの専門家になりたいなら、今が始める時です。木曜日のリスナーとして、あなたはアルファを手に入れました。
非常に迅速に移りましょう。10分過ぎていることは知っていますが、ビデオの世界で起こったことを伝えずにスキップすることはできません。多くのことを実際に見せる時間はそれほどありませんが、いくつかのことを発表したいと思います。
GoogleのV2、ビデオ生成モデルが現在、Geminiアプリと開発者AIでも一般利用可能になりました。Geminiを使用している場合、Geminiはアクセスできると思います。私はアクセスを持っていませんが、AI.dev(AI studioへのショートカットURL)に行くと、新しいUIが見えます。ビデオ生成は右ここにあり、V2ビデオ生成があります。2つの結果を得ることができ、物事を依頼することができます。画像をアップロードすることさえできます。そして、V2でビデオをたくさん生成することができます。V2は依然として最高のビデオ生成モデルの一つと考えられています。非常に強いリアリズム、非常に良いです。また、速いです。
他の画像を生成するもの、それらは最大8秒を生成し、その後、他のもの、他のものとしてClingと呼ばれるものがあります。本当にClingをお見せしたいです。これまでClingは米国側では役に立ちませんでした。なぜならClingは中国の電話番号を必要としたからです。
ClingはCling 2.0をリリースしました。私は非常に遅くまで起きて、これらすべてをまとめようとしました。別のものでこれを開きます。Clingは、最先端と主張するビデオだけでなく、最先端と主張するビデオモデルもリリースしました。また、現在cling.comで西洋の人々、つまり中国以外の電話番号を持つ人々も利用できるツールの完全なスイートをリリースしました。これは非常に重要だと思います。Fal.aiを介してClingを使用することができます。Fal.aiはポッドの素晴らしい友人で、彼らはパートナーですが、Cling自体の体験でも2つのことがあります。モデルCling.2、画像モデルColors 2.0もあります。Soraイメージほど静かではありませんが、非常に近い画像生成も持っています。
ヤムが電話番号の要件は以前からなくなっていたと考えていると言っています。おそらく、どれだけ新しくリリースされたかについて過大評価しているかもしれません。
特に強調したかったことは、いくつかのことがあり、Cling 1.6、新しいものではないですが、これを更新して画像について推論し、テキストと画像を一緒にこの一つのインターフェースで持つことができるマルチ要素エディターがあります。これまでにこのようなものは見たことがありません。例えば、ビデオを貼り付けることができます。これは私のビデオで、このビデオについて推論し、ビデオにタグを付け、「このビデオのこの部分をこの画像のこの部分に置き換えてください」と言うことができます。このような多モダル会話は他では見たことがありません。
彼らはClink 1.6の新しいバージョンを構築し、それをMVLプロンプト言語コンセプトと呼んでいると思います。MVLはマルチモーダルビジュアル言語を表し、正確な制御のためにテキストプロンプト内部に画像を入れ込みます。これが最も強調したかったことだと思います。彼らには例があります。「@imageからのコンテンツを@videoからのコンテンツと交換する」という構造に従って、複数の画像をアップロードし、「このビデオで彼のパーカーをこのタイプのパーカーに変更してください」と言うことができ、パーカーの画像を追加できます。UIでは、これによりビデオ生成において、AIアーティストが求めていた極めて正確な制御が可能になります。
また、エフェクトもあります。エフェクトはかなり素晴らしいです。リップシンクもあります。そして最後ですが、非常に興味深いのは音声生成もあります。雷や車のクラクションなどを求めることができます。人々が歩いている音や車のクラクション生成などを聞くことができます。
新しいアップデートで最も好きなのは、それが今や総合的な編集体験になっていることです。その場で画像生成から始めることができます。それだけでなく、DeepSeekを統合しているので、プロンプトがわからない場合は、DeepSeekに組み込まれたヘルプを求めることができます。それは画像からビデオ生成へ、ビデオから拡張へ、そしてリップシンクと音声生成へと進みます。AIアートを楽しみでやっている人は、17,000の異なるサーバーに行く必要があることを知っています。ここにはプロンプト用があり、ここにはビデオ用があり、ここには画像用があり、それらを組み合わせる必要があります。彼らは本当にこの一つの総合的なプラットフォームを目指しています。それは本当に素晴らしいです。そして現在、ドルでの支払いも可能です。
ビデオ関連のオープンソース側にもいくつかのリリースがあります。ByteDanceはSeaweedをリリースし、1Xも新しいモデルをリリースしました。Dolphin Gemmaについては話す時間がありませんでしたが、非常に簡単に言うと、Googleの人々は研究者と協力して、イルカとイルカの音を理解する言語モデルを構築しようとしました。これは非常に素晴らしいことです。私たち自身でイルカの音を出すことはできませんでしたが、やりたかったです。
それ以外は、2時間15分の木曜日のショーでほぼすべてをカバーしたと思います。皆さん、参加してくれてありがとうございます。ヤム、ありがとう、Nは以前ここにいました、Wolframもありがとう。プロトコルについての詳細なインタビューを含め、このクレイジーなニュースの週をカバーしようとしてくれてありがとう。これは簡単な2時間ではありませんでした。O3とO4ミニ、そして4.1、4.1ナノ、4.1ミニのローンチを祝いました。ボイスとオーディオについても話しました。V2とClingについても話しました。GoogleのA2Aプロトコルに取り組んでいるTodd Seagelとの詳細なインタビューを行い、MCPが行われている世界でA2Aがなぜ重要なのかについても話しました。BitnetとIntellect 2についても話し、アップデートのクレイジーな週について話しました。
ここにいてくれたすべての人、特に毎週聞いてくれている人々の時間に感謝します。ショーの一部を見逃した場合、木曜日を購読することができます。YouTube チャンネルも購読できます。木曜日は1000フォロワーを超え、ランキングでも急速に上昇しています。ショーが気に入り、役立った場合は、友人と共有してください。それがショーをサポートする最良の方法です。友人と共有してください。
来週も素晴らしい週になると思います。今日にでも何かのニュースが出る可能性がありますが、言うことはできません。WolfframはXでフォローするようにと言っていました。なぜなら、ショーの形式ではない場合でも、それに対応するからです。今週のライブストリームは終わりだと思いますが、明日何か別のことが起こるかもしれません。今週のライブストリームは終わりにしたいと思います。
皆さん、参加してくれてどうもありがとうございました。ショーの編集を始めます。参加してくれてありがとうございました。また来週ここでお会いしましょう。さようなら。


コメント