
6,336 文字

OpenAIからまた大きな発表がありました。これはGPT-4.1の発表よりもずっと重要な内容です。新たに2つのモデル、O3とO4 miniが登場しました。これは推論モデルがツールを効果的に使用できるようになった初めてのケースです。これまでの推論モデルの主な制限の一つは、ほとんどのモデルがツールや関数を使用できなかったことですが、この新シリーズではツールを使用できるようになり、エージェントとしての利用において非常に効果的になるでしょう。さらに、ネイティブなマルチモーダル推論機能も備えています。
ベンチマークの興味深い更新に加えて、ツールの使用は特に期待できる点です。また彼らは、CodexCLIと呼ばれる独自バージョンのCloud Codeを導入しました。これにより、これらの推論モデルをターミナルやCLI内で使用できるようになります。この点については後ほど詳しく説明します。
ブログ記事を見ていきながら、私の考えをシェアしていきます。彼らはO3とO4 miniという2つのモデルをリリースしており、これらは元のO1モデルを置き換えることになります。これらのモデルははるかに優れているため、O1モデルへのアクセスはまもなく失われるでしょう。
彼らはこれらのモデルがエージェントとしての使用に優れており、ChatGPT内のあらゆるツールを組み合わせていると述べています。これまでの推論モデルはウェブ検索ツールなどにアクセスできませんでしたが、今回のアップデートでウェブ検索、アップロードされたファイルや他のデータのPythonによる分析、視覚入力による深い推論が可能になります。リリースビデオでは強調されていませんでしたが、画像生成も可能になるようです。この機能がリリース時に利用可能かどうかはわかりませんが、生成される画像の品質がGPT-4と同等であれば素晴らしいことです。
最先端の推論能力と完全なツールアクセスを組み合わせたパワーにより、学術的ベンチマークと実世界のタスクにおいて著しく高いパフォーマンスを実現し、知性と有用性の両面で新たな基準を設定します。冒頭で述べたように、推論モデルによるエージェント的使用ケースは大きなパフォーマンス向上をもたらし、彼らが共有したベンチマークにもそれが表れています。コーディングや推論のベンチマークはすでに飽和状態に達しているため、より優れたベンチマークが必要でしょう。
彼らはO3を最も強力な推論モデルと呼び、コーディング、数学、科学、視覚的認識の領域で最先端の性能を持つと述べています。特にマルチモーダル理解と視覚的認識について強調しており、いくつかの例も示しています。モデルへのアクセスが得られたら独自のテストを実行する予定ですが、マルチモーダルベンチマークの結果全体からは大幅なパフォーマンス向上が見られます。
このモデルは画像、チャート、グラフを分析できるようになり、外部評価ではO3 miniが難しい実世界のタスクでOpenAI O1よりも20%少ないエラーを犯し、特にプログラミング、ビジネスコンサルティング、創造的アイデア創出の分野で優れていると述べています。どのリリースブログやビデオでも、OpenAIだけでなくすべての研究所が自社のモデルを誇張する傾向がありますので、実際の使用感を確認する必要がありますが、少なくとも示されている内容からは、これらのモデルは非常に有望に見えます。
また、O4 miniモデルもあり、これは高速で費用対効果の高い推論に最適化された小型モデルです。そのサイズとコストを考慮すると、特にコード、数学、視覚的タスクにおいて驚くべきパフォーマンスを達成しています。コスト最適化の具体例としては、ツール使用なしのAME 2025ベンチマークやGPQAデータセットでの結果があります。同じコストでO4 miniは現在のO3 miniよりもはるかに良いパフォーマンスを発揮します。
同様に、O3モデルも大幅に最適化されており、既存のO1モデルと比較して、はるかに低い推定推論コストで大幅なパフォーマンス向上が見られます。O1モデルはなくなる予定で、これはO3とO4 miniモデルの推論を実行するためにそれらのGPUが必要だからだと思われます。
O4 miniはO3よりもはるかに高い使用制限を持ち、見たベンチマークによっては、ほとんどのタスクに合理的なモデルとなる可能性があります。ただし、この動画の録画時点では使用制限がどのようになるかについての情報はありません。
これらのモデルは今日からChatGPTおよびAPI内で利用可能になります。後ほど彼らが共有したコスト数値を示しますが、既存のO1モデルと比較してはるかに合理的なようです。
また、外部専門家の評価者は、両モデルが改善された指示追従能力と、より有用で検証可能な応答を示していると評価しており、これは改善された知性とウェブソースの組み込みによるものです。OpenAIがこれらの新リリースで特に指示追従能力を強調していることに注目してください。これはGPT-4.1でも同様でした。また、現在の焦点は特にコーディングとエージェント的ユースケースにあり、推論モデルはより多くのエージェント的使用に最も適していると思われます。なぜなら、使用するツールについて推論できるからです。
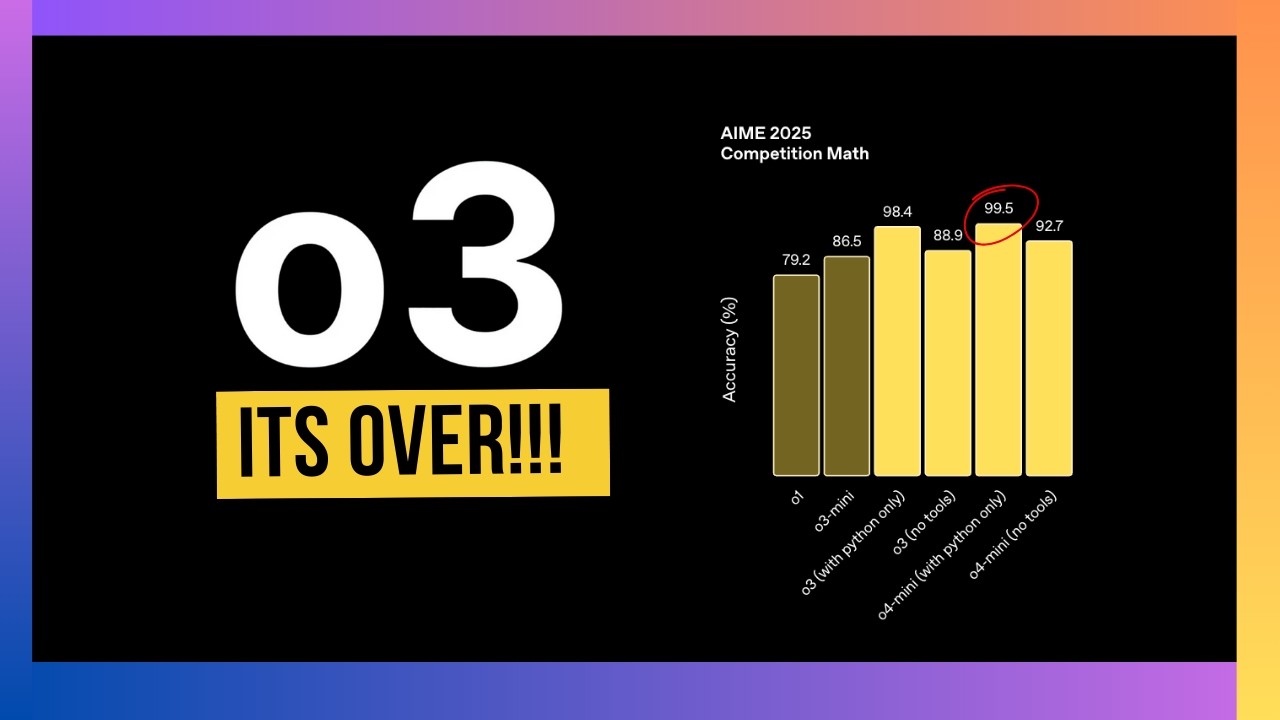
コーディングベンチマークのパフォーマンスは驚異的ですが、まずは数学のベンチマークを見てみましょう。たとえば、O4 miniのAIM 2025コンペティションでは、Pythonインタープリターを使用して99.5%のスコアを達成しています。これらのモデルの知性レベルでこれらのベンチマークはほぼ飽和状態に達しているため、より良いベンチマークが必要です。
Code Forceコード計算ベンチマークを見ると、パフォーマンスの面で以前のO1およびO3 miniモデルを大幅に上回っています。人文科学の試験では、Deep Researchはまだ03よりも優れたパフォーマンスを示していますが、エージェントシステムを使用するため、応答生成にはより多くの時間がかかるでしょう。一方、O3 miniはずっと高速になると思われ、リリースビデオでもそれが強調されていました。マルチモーダルモデルでも同様の傾向が見られます。
OpenAIについて現在気に入らない点の一つは、これらのモデルを自社の製品とのみ比較していることです。透明性を高めるためには、同じグラフに他のフロンティアモデルも表示すべきです。それによって、改善がどのように見えるかを人々が比較しやすくなるでしょう。正直なところ、これらは非常に顕著な数字であり、他のモデルはこれらの数字に近づいていないと思われるため、競合他社もここに表示すべきです。
いくつかの例を見てみましょう。例えば、Sweep Bench Verifiedでは、O3が約69%、O4 miniが68%となっています。これは最先端のスコアであり、以前の最高スコアは65%でした。これは大幅なパフォーマンス向上であり、競合他社を含めることで実際の利得がどれほどかを確認することが重要です。
同様に、ADポリグロットコード編集では、高設定のO3 miniが全体で81%、コード編集のみの場合は約80%を達成しています。これは驚異的です。なぜなら、現在の最高スコアはGemini 2.5 Proの72.9%だからです。コストを確認する必要がありますが、コーディングにおいては、Gemini 2.5 Proを上回る新しい最先端モデルが登場したようです。来月のGoogle IOでGoogleが何を発表するのか楽しみです。彼らは間違いなくこの新しい最高スコアを超えたいでしょう。
私たちは非常に興味深い時期にあり、ここ数ヶ月で見られた進歩は驚異的です。OpenAIだけでなく、他のモデルプロバイダーからも、ClaudeやAnthropicを除けば(彼らはかなり遅れています)、より多くのモデルリリースがありました。全体として、これらのベンチマークはそれほど長く持ちこたえないでしょう。ポリグロットのような非常に難しいベンチマークでさえ、ここで見られるパフォーマンスは非常に驚異的です。
ただし、これらは単一のファイルと単一の編集に対するものであることに注意してください。実世界のコーディングパフォーマンスはまだテストされておらず、人々が持つ内部ベンチマークでどのようなパフォーマンスを示すか見る必要がありますが、これらの数字に基づけば、コーディングにおいて新しい最先端の性能を持つことになります。
彼らが強調した他の点は、指示追従とツールの使用です。これは特にエージェントシステムを構築する場合に重要で、システムが指示に従い、それから逸脱しないことが望まれます。ここでも、Pythonやブラウジングなどのツール使用において最先端のパフォーマンスを示しています。指示追従の具体的なベンチマーク、特にTopbench関数呼び出しやツール使用ベンチマークでは、このベンチマークで最先端の結果を示しています。このモデルを自分のテストで試して、どれだけ良いのか確認する予定ですが、ツール使用能力を持つ推論モデルを探しているなら、これが最初の本当に良いオプションのようです。
では、彼らはどのようにしてこれを実現したのでしょうか。彼らは強化学習を拡張することができました。優れた事前トレーニング戦略を見つけただけでなく、トレーニング後の処理でもさらに進歩しているようです。ブログ記事のこのセクションを見ていきましょう。
O3の開発過程で、大規模な強化学習が「より多くの計算=より良いパフォーマンス」という同じ法則を示すことを観察しました。トレーニング中や継続的トレーニング中により多くの計算リソースを使用すると、モデルはAMベンチマークでより良いパフォーマンスを示しました。これは、テスト時の計算とトレーニング計算の両方をスケールアップする大きな機会がまだあることを示しています。スケーリングの壁にはまだ到達していないようです。
彼らは「スケーリングパスを再トレースすることで、今回は強化学習において、トレーニング計算と推論時間の推論の両方で追加の桁を押し上げましたが、まだ明確なパフォーマンスの向上が見られます。これは、モデルが考えることを許されるほど、パフォーマンスが向上し続けることを検証しています」と述べています。
スケーリングの壁はなさそうで、トレーニングと推論時の両方でより多くの計算リソースを投入するほど、モデルはより良くなる傾向があるようです。ARC AGIベンチマークでのパフォーマンスがどうなるか見てみたいです。特にO1シリーズでは単一のタスク実行に数千ドルかかっていたので、O3とO4 miniがどのように見えるか興味深いところです。
彼らが行った別のことは、強化学習を通じて両方のモデルにツールの使用を教えたことです。ツールの使用方法だけでなく、いつツールを使用するかについて推論する方法も教えました。これは良いエージェントシステムの重要な部分です。モデルに特定のツールをいつ使用するかを知ってもらいたいのです。彼らは強化学習を通じてそれを実現できたようです。実世界での使用を確認する必要がありますが、示されている例からは、モデルが画像や視覚情報を推論し、それに基づいて使用するツールを決定できることがわかります。
ビデオで強調されたもう一つの点は、ツールの出力を通じて推論できることです。あるツールを使用することを決定し、エージェントシステムでその出力を見た場合、その出力について推論し、特定のタスクにより適したツールを使用するために計画や思考の連鎖を修正できます。これにより非常に強力になるでしょう。
彼らは「これらのモデルは初めて画像を直接思考の連鎖に統合できます。彼らは単に画像を見るだけでなく、画像で考えます。これにより、視覚的およびテキスト的推論を融合させる新しいクラスの問題解決が可能になり、マルチモーダルベンチマーク全体で最先端のパフォーマンスが反映されています」と述べています。
これは産業応用、特に製造業において大きなブレイクスルーになるでしょう。モデルは異なる製品を見るだけでなく、それらを視覚的に推論することもできるようになります。画像がぼやけていたり、反転していたり、低品質であっても機能するようです。これをテストする必要がありますが、ベンチマークは確かに非常に良く見えます。
彼らはAPIを通じた関数呼び出し機能を可能にするエージェント的ユースケースについても言及しています。O1やO3 miniでは、プロンプトでの思考の連鎖(Chain of Thought)の使用を推奨していませんでした。同じ原則がここでも適用されるのか、それとも異なる戦略が必要なのか確認する必要があります。彼らは最近、GPT-4.1モデル向けのプロンプティングガイドをリリースしましたが、これらの原則がこれらの推論モデルにも適用されるのか、それとも全く新しいパラダイムが必要なのか興味深いところです。
いくつかの例では、O3とO1を比較しており、全体的にO3はさまざまな領域でO1よりもはるかに優れているようです。これらのリンクをビデオの説明に載せておきますので、確認してみてください。ここではあまり時間をかけません。
価格設定について話しましょう。O4 miniとO3 miniの価格設定は次のようになります。O4 miniは実際にはGPT-4.1よりも安いかもしれません。GPT-4.1は入力100万トークンあたり約2ドルですが、これはさらに低いです。ベンチマークではO4 miniはGPT-4.1よりもはるかに優れているにもかかわらずです。O3に関しては、なくなる既存のO1と比較してコストがはるかに低くなっています。これはGPT-4やGPT-4.1の代替として使い始めるのに良いモデルかもしれません。実世界でどのように機能するか確認する必要がありますが、ここには勝者がいると思います。
最後に発表されたのはCodex CLI、ターミナル内のフロンティア推論です。これはGitHubで利用可能なオープンソースプロジェクトで、Cloud Codeの競合製品のように見えます。これはローカルマシンで実行でき、マルチモーダルな性質を持つため画像を通じて推論することができます。CodexCLIを試して、おそらくより詳細なビデオを作成する予定です。実世界のアプリケーションでどれだけ良いのか確認していきます。チャンネル登録をお忘れなく。
これはとても素晴らしいリリースです。モデルを試して、より詳しい意見を後ほどお伝えしますので、チャンネル登録をお願いします。しかし、Googleに対してかなり高いハードルを設定したと思います。Gemini 2.5 Proは最高のコーディングモデル、最高の競争モデルでしたが、O3とO4 miniでOpenAIはハードルを非常に高く設定しており、GoogleがGoogle IOで何をリリースするのか興味深いところです。Claudeも何か開発中と思われますが、彼らはかなり遅れていました。
これらの新しい推論モデルでの体験がどのようなものか教えてください。非常に興味深いですね。このビデオが役立つことを願っています。視聴ありがとうございます。また次回お会いしましょう。


コメント