
7,649 文字
テスト時の計算能力は、2017年にトランスフォーマーが世界を変えて以来、最も重要なブレークスルーです。AIモデルが長期的に考えることを可能にすることで、モデルははるかに賢くなりますが、それだけでなく、このマーケットは事前学習よりも大きくなる可能性があります。テスト時のスケーリングが実際にどれほど大きくなるかを示す証拠をいくつか集めましたが、まずは最も単純な用語でそれが何なのかを説明させてください。
それは、モデルに長期的な思考を可能にすることです。推論時により多くのトークンを使用できるようにすること、つまり、モデルに最初に思いついた応答を返すのではなく、実際に物事について考えるよう促すことです。
数ヶ月前にGoogle DeepMindから発表された論文「モデルパラメータのスケーリングよりもLLMのテスト時計算の最適なスケーリングの方が効果的である可能性がある」では、モデルの思考能力をスケールアップすることで、より多くの成果を得られることを証明しています。LLMの出力を改善するためにより多くのテスト時の計算を使用できるようにすることは、オープンエンドな自然言語で動作できる、一般的に自己改善するエージェントを構築するための重要なステップです。
私たちはLLMにおける推論時計算のスケーリングを研究し、「LLMが固定された非自明な量の推論時計算を使用することを許可された場合、困難なプロンプトに対するパフォーマンスをどれだけ改善できるか」という質問に焦点を当てています。結果は驚くべきものでした。これはo1モデルで示されただけでなく、現在ではo3モデルが、ARK AGIベンチマークを含む多くのフロンティアベンチマークで信じられないほど良いスコアを記録しています。
このセグメントはsynf flow AIがスポンサーです。synf flowは、音声AIエージェントを構築するためのノーコードプラットフォームです。リードの資格審査、予約の設定、フォローアップ、カスタマーサポート、よくある質問など、すべてに対応します。
会社をスケールアップし、あなたと顧客との間の個人的なやり取りをスケールアップしたい場合、synf flowは素晴らしい選択肢です。本当にパーソナルなタッチで、しかもあなたの時間を使うことなく、ビジネスへのインバウンドコールを処理できるAIレセプショニストを想像してみてください。24時間365日稼働しながら、発信者に挨拶し、適切な担当者に案内することができます。
また、自動予約機能もサポートしているので、カレンダーと連携させることで、synf flowのAIエージェントがあなたに代わって予約を行うことができます。こちらがデモをご覧ください:
「サウスウエスト・モーゲージ・コーポレーションのエマです。住宅ローンについてお話させていただきたいのですが、少々お時間よろしいでしょうか?」
「はい、今は無理ですが、金曜日の午後5時に予約を入れたいです。」
「承知いたしました。金曜日午後5時にご予約を設定させていただきます。お名前と連絡先をお教えいただけますでしょうか?」
「マシュー・バーマンです。メールアドレスはmatt@forwardfuture.です。」
「ありがとうございます、マシュー様。matt@forwardfuture.に確認メールをお送りいたします。」
「ありがとうございます。」
「はい、このように簡単です。」
ぜひsynf flowをチェックしてください。下のリンクを使用していただければ、私からの紹介だとわかります。あなたのビジネスに何ができるか確認してみてください。では、動画に戻りましょう。
では、なぜテスト時の計算がそれほどうまく機能するのでしょうか?人間がどのように働くかを考えてみましょう。人間は難しい問題に対して、より確実に判断を改善するために、より長く考える傾向があります。誰かが難しい数学の質問や論理の質問、あるいは何らかの思考を必要とする質問をしたとき、頭に最初に浮かんだことをそのまま言うのではありません。考えて、答えのさまざまな可能性について考え、そして最良の答えを見つけ出そうとしてから述べるのです。
言語モデルもこれができるのでしょうか?同じ戦術を採用できるのでしょうか?答えはイエスです。テスト時のこのような能力は、エージェント的な推論タスクにおいて新しい可能性を開く潜在力も持っています。
どのように機能するのでしょうか?現在、テスト時計算にはいくつかの技術があります。その1つは「best of n sampling」と呼ばれるもので、これは多くの候補となる応答を生成し、どれが最良かを判断しようとするもので、それぞれの候補応答は異なります。論文で説明されているように、ベースとなるLLMから並行して出力をサンプリングし、学習済みの検証器または報酬モデルによって最も高いスコアを獲得したものを選択します。
そして、それがプロセスベースの報酬モデルについて話すことへとつながります。アウトカム報酬モデルとプロセス報酬モデルの違いについて話しましょう。なぜなら、これらの思考モデルがどのように機能するか、そして一般的に思考がどのように機能するかを理解する上で重要だからです。
アウトカム報酬モデルでは、基本的に答えが正しいか間違っているかでモデルに報酬を与えますが、その答えにどのようにたどり着いたかは重要ではありません。答えが正しいか間違っているかだけが問題です。プロセス報酬モデルを説明すれば明らかになりますが、このアプローチには本質的な問題がいくつかあります。
プロセス報酬モデルでは、解決策に至る過程の各ステップについて、実際にモデルに報酬を与えています。モデルが6つのステップのうち最初の4つを正しく行った場合、全体が間違っているとただ考えるのではなく、最初の4つが正しかったことを知るべきです。そうすれば、全てを捨てるのではなく、最初の4つのステップを保持し、最後の2つのステップがどうなるかを考えようとすることができ、それに応じて報酬が与えられます。
ここで示されているように、左側ではOMM(アウトカム報酬モデル)は全体が間違っているためそれは間違いとされ、右側では最終的な答えは間違っていますが、最後のステップを間違える前にいくつかのステップを正しく行っており、これを理解することは非常に重要です。
これらのモデルに考えさせるには多くの方法があります。そのいくつかについて話しましょう。プロセス報酬モデルに対する検索方法について、まず、重み付けされたbest of nがあります。基本的に、多くの答えを生成し、モデルがどれが正しいと考えているかを判断し、それを選択するという非常にシンプルなものです。
次にビーム検索があります。これはステップごとの予測を検索することでPRMを最適化します。最初の予測をサンプリングし、生成されたステップをスコア化し、最高スコアのステップをフィルタリングし、各候補について次のステップを考え出し、同じプロセスを繰り返します。
最後に先読み検索があります。これはビーム検索が個々のステップを評価する方法を修正したもので、検索プロセスの各ステップでPRMの価値推定の精度を向上させるために先読みロールアウトを使用します。
それぞれをここで見ることができます。best of nは答えを生成して最良のものを選び、ビーム検索は各ステップで最良のステップを選びながらステップを生成し、先読み検索はビーム検索を少し修正したもので、ステップを生成し、先を読み、戻ってくるというより反復的なアプローチです。
では、少し視点を広げてみましょう。o1のローンチが重要だったことを覚えています。それは、推論時のスケーリングが実際に存在し、本当に強力になり得ることを世界に示しました。そしてo3が登場し、その真の力と、どれほどスケールできるかということで、みんなの心を本当に驚かせました。
まず、このベンチマークを見てください。ARK AGIベンチマークは、人間には理解しやすいけれども、少なくともこれまでのAIには理解が非常に難しい質問のセットです。注目すべき重要な点は、これらの思考モデル以前の最高のモデルでさえ、あまり良い成績を上げていなかったということです。一桁のパーセンテージ、あるいは10%台、20%台程度で、それ以上はあまり良くありませんでした。
そしてo1が登場し、はるかに良い成績を収めました。ここで見られるのは20%後半から30%前半で、そしてo3が登場しました。ここで覚えておくべきことがあります。これはo3 Lowで、多くの思考を使用しませんでしたが、それでも考えました。そしてこれはo3 Highで、基本的に無制限の思考を使用することができました。
私たちが見ているのは、より多くの思考をすればするほど、より良い結果を出せるということですが、それは依然として非常に高価です。それは覚えておくべき重要なことです。76%から88%に到達するには、88%のスコアを出すのに数十万ドルかかったと思います。なぜなら、非常に長い期間にわたって非常に多くのトークンを使用したからです。
こちらはLisa Su、AMDのCEOです。ちなみに、NvidiaのCEOであるJensen Wangのいとこでもあります。これはちょっと考えられないことですが、彼女は推論時のスケーリングが事前学習よりも大幅に大きな市場になるだろうと述べています。
「Mi30で私たちが行ったことは、推論、特に大規模言語モデルの推論のための素晴らしい製品を構築したことです。将来を見据えると、現在多くの企業が行っているのは、トレーニングとどのようなモデルを使用するかを決定することですが、今後、推論はより大きな市場になると考えています。そして、それは私たちがMi300のために設計したものとうまく合致します。」
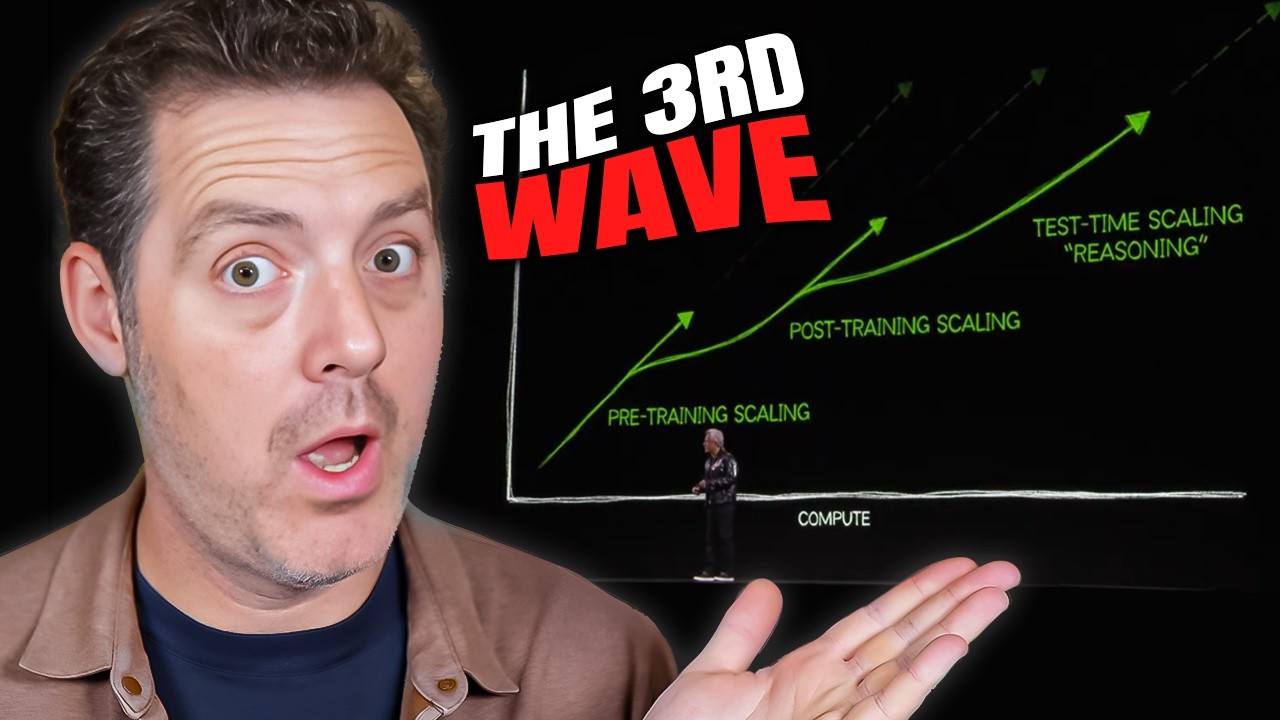
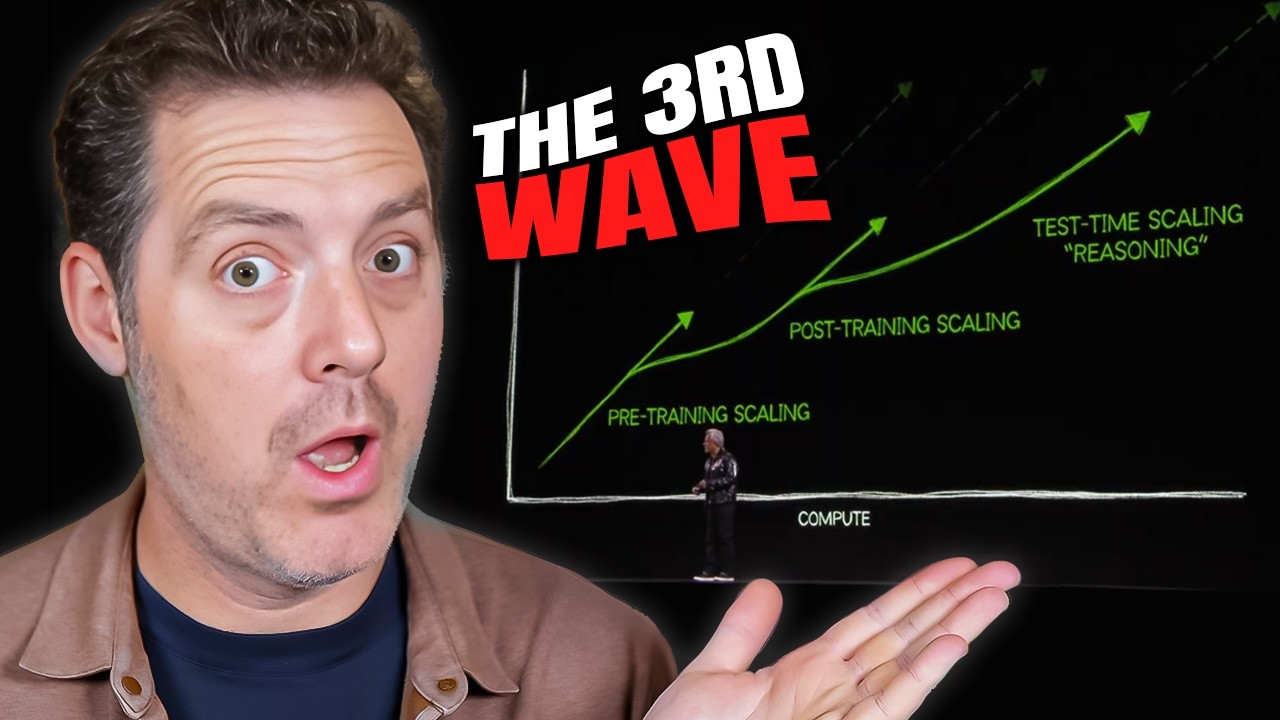
そして彼女だけではありません。彼女のいとこのJensenは、CES 2025で基調講演を行い、私もそれを見ることができましたが、素晴らしいものでした。その中で、彼はこの新しいスケーリング則について話し、また推論時の計算がどれほど大きな市場になるかについても話しています。
この最初のクリップでは、3つのスケーリング則について話します。3番目がテスト時の計算です:
「業界は人工知能のスケーリングを追い求め、競争しています。スケーリング則は、より多くのトレーニングデータ、より大きなモデル、そしてより多くの計算を適用すればするほど、モデルはより効果的に、より能力が高くなることを示しています。しかし、実際には他に2つのスケーリング則が登場しています。2番目のスケーリング則は、事後トレーニングのスケーリング則です。事後トレーニングのスケーリング則は、人間のフィードバックによる強化学習などのテクノロジーや技術を使用します。
基本的に、AIは人間のクエリに基づいて答えを生成し、それは実際にはもっと複雑なものですが、強化学習システムは、非常に質の高いプロンプトを相当数使用することで、AIにスキルを洗練させます。そしてこの3番目のスケーリング則は、テスト時のスケーリングと呼ばれるものに関係しています。テスト時のスケーリングは、基本的にAIを使用する際に、AIがパラメータを改善する代わりに、生成したい答えに対してどれだけの計算を使用するかを決定することに焦点を当てることができるようになります。
直接的な推論やワンショット解答の代わりに、推論を行ったり、問題を複数のステップに分解したり、複数のアイデアを生成し、生成したアイデアのどれが最良かをAIシステムが評価したりすることができます。」
そして、このクリップでは、推論が彼らの会社戦略の重要な部分であり、なぜそれが巨大な市場になると考えているのかについて話します:
「もちろん、私たちが必要とする計算量は信じられないほど大きく、実際、社会が計算量をスケールアップして、より多くの、よりよい知性を生み出す能力を持つことを望んでいます。知性はもちろん、私たちが持つ最も価値のある資産であり、多くの困難な問題を解決するために応用することができます。そして、スケーリング則はNVIDIAのコンピューティングに対する膨大な需要を生み出しています。」
しかし、彼だけではありません。3人目はGrockのCEOであるJonathan Rossです。私は投資家ですが、彼は当初、推論の市場は事前学習の10〜20倍の規模になると考えていましたが、今では実際にはそれよりもはるかに大きくなると考えており、私もそれに同意します。
Grockチップについて、Grockは推論に焦点を当てた会社です。彼らはこの新しいスケーリング則を活用するのに良い位置にいます。しかし、重要なのは、現在、このすべてのテスト時の計算を行うのは非常に高価だということです。トークンは比較的安価ですが、それらを積み重ね、モデルに数分、数時間、数日、数週間、場合によっては数ヶ月も考えさせ続けると、それは非常に高価になります。
しかし、他のすべてのテクノロジーと同様に、AI市場への継続的な投資が流入し、チップの新技術や新しいイノベーションが起こることで、推論はより安価になっていくでしょう。では、それが安くなったらどうなるのでしょうか?それは市場が縮小することを意味するのでしょうか?なぜなら、もし誰もが同じ量の計算を購入しているが、それがはるかに安価であれば、総支出額ははるかに少なくなるからです。
いいえ、そしてJonathan Rossの話に戻りますが、彼は実際にこの正確なポイントについて触れており、私は非常に興味深いと思いました:
「計算をより安価にすると、人々はより多く購入するのでしょうか?はい、それはジェヴォンズのパラドックスと呼ばれ、私たちのビジネスの重要な部分です。例を見てみましょう。1860年代、あるイギリス人が石炭に関する論文を書きました。その中で、蒸気機関がより効率的になるたびに、人々はより多くの石炭を購入するようになったと指摘しています。これはパラドックスです。なぜなら、より効率的なのに、なぜより多く購入するのでしょうか?
答えは、蒸気機関をより効率的にすると、運用費用(OPEX)が削減され、運用費用が削減されると、収益性のある活動の数が増加するため、人々は蒸気機関と石炭を使用してより多くのことを行うようになり、需要が増加するのです。同じパラドックスが計算にも当てはまります。」
簡単に説明させてください。この技術があり、それは非常に高価ですが、顧客に多額の料金を請求できるため、この1つのユースケースには有用だとします。もし突然その技術が桁違いに安価になった場合、適用できるユースケースの数は劇的に増加します。つまり、その技術の各単位ははるかに安価になっているにもかかわらず、顧客に再販売できるユースケースが多くなるため、実際にはより多くの支出をすることになります。
彼は続けます:「過去60年間、ほぼ時計仕掛けのように、10年ごとに計算は約1000倍安くなり、人々は10万倍多く購入し、全体的な支出は100倍になっています。Grockの使命は、計算のコストをゼロに近づけることです。計算をより安価にすればするほど、人々はより多くの支出をします。次の10年間で、私たちは生成AIのコストを1000倍削減し、より多くの活動を収益性のあるものにしたいと考えており、それによって100倍の支出増加が起こると考えています。」
このように、この市場は巨大になります。これらのモデルはより良くなり、より長期的に考えることができるようになります。この時点で、「マット、推論時間の話は多すぎる」と思うかもしれませんが、もう1つお見せしたいものがあります。
これは、Google DeepMindが文字通り1日前、2025年1月6日に発表したばかりの論文「拡散モデルの推論時スケーリング」です。これで、AIの別の領域全体が推論時スケーリングを行う能力を解放したことになります。拡散モデルは、画像を生成するモデル、テキストから画像へ、画像から画像へなどを行うモデルであり、今や同じ技術を適用しています。基本的に、推論時にモデルに考えさせますが、今回は生成する画像について考えさせるのです。
この論文を見てみましょう:「最近の研究は、大規模言語モデルにおける推論時スケーリングの振る舞いを探り始め、推論時の追加の計算によってパフォーマンスがさらに向上する可能性を明らかにしています。LLMとは異なり、拡散モデルは本質的に、デノイジングステップの数を通じて推論時の計算を調整する柔軟性を持っています。」
これは、拡散モデルがどのように機能するかについての、最も高レベルで最も単純な説明です。非常に粗い画像から始まり、その後、継続的にデノイジングを行います。基本的に、曖昧さや未知の部分のぼやけを取り除いていきます。しかし、通常、パフォーマンスの向上は数十ステップ後にフラット化します。
そして、この研究では、デノイジングステップを増やす以外の拡散モデルの推論時スケーリングの振る舞いを探究し、より多くの計算で生成パフォーマンスをさらに向上させる方法を調査しています。つまり、より多くのテスト時計算、より多くの思考です。
bcloudがこの論文の優れた分析を行っていたので、簡単に読ませていただきます:拡散モデルは通常、デノイジングステップの数を増やすことでサンプルの品質を向上させますが、その向上は頭打ちになります。これについては先ほど話しました。そこで、この論文では、この拡散プロセス中にモデルにより多くの計算能力を使用する能力を与えることを提案しています。
フレームワークには2つの主要なコンポーネントがあります。生成されたサンプルの品質を評価する検証器モデル(従来のLLMで話したことと非常によく似ています)と、検証器のフィードバックに基づいてより良いノイズ候補を探索するアルゴリズムです。全て同じプロセスで、多くのサンプルを生成し、最良のものを選びます。そして私たちが見ているのは、結果が自ら物語っているということです。追加の計算を行う時間を与えられると、実際にはるかに高品質な結果を生成します。
これら全ては何を意味するのでしょうか?AIについて学ぶためにどこに時間を費やすべきか、AIの次のイノベーションがどこから来るのかを考えているなら、推論時こそ注目すべき場所です。
この動画が気に入っていただけたなら、「いいね」と登録をお願いします。また次の動画でお会いしましょう。

コメント