

ええ、ファインチューニングは死にました。ファインチューニング万歳。
このトークのアイデアは、主に面白いツイートから生まれました。私はファインチューニングが以前ほど重要ではなくなったと考える傾向があり、ハメルは私にその考えを実際に擁護するよう挑戦してきました。そこで、ここでそれを試みようと思います。
さて、私は誰でしょうか? 私の名前はエマニュエルです。もう10年近くMLに携わっています。元々はデータサイエンスをしていましたが、その後実はML教育の分野で働きました。
需要予測のためのデータサイエンスモデルをトレーニングし、ML教育でモデルのトレーニングを人々に教えました。MLモデルのトレーニング方法に関する実践ガイドも書きました。その後、Stripeでスタッフエンジニアとして働き、さらに多くのモデルをトレーニングしました。現在はAnthropicで働いており、いくつかのモデルをファインチューニングしたほか、現在はこれらのモデルがどのように機能するかを実際に理解する取り組みを支援しています。
非常に重要です。少し控えめな紹介をしましたが、もう少し宣伝させてください。mlpower.comというウェブサイトがあります。そこでエマニュエルの本を見ることができます。機械学習の古典と言えるでしょう。応用機械学習の分野では特にそうです。ぜひチェックしてみてください。
宣伝ありがとうございます。はい、ぜひチェックしてください。いつかLLM特有のヒントを追加して更新したいと思っています。今のところ一般的な機械学習の知識だけですが。そのウェブサイトで最初の章を無料で読むことができます。気に入らなければ何の約束もありません。
これはこのトークで最も重要なスライドです。このトークは私の個人的な意見であり、Anthropicの見解ではありません。主にこう言うのは、Anthropicが他のことと並んでファインチューニングを提供しているからです。ファインチューニングが死んだと彼らが考えているなら意味がありませんよね。これは主に、私のキャリアを通じて分野の進化を見てきた経験に基づく、ある意味ホットな意見や信念であり、Anthropicが本当に信じていることではありません。
10年間モデルをトレーニングしてきましたが、お勧めはしません。
これは、分かりませんが、本当にこのトークを2枚のスライドにまとめたものです。様々な理由で面倒くさいと思います。十分な経験を持つ人々と話せば、きっと多くの恐ろしい話を聞くことができるでしょう。しかし、3つのことについて話したいと思います。実際、恐ろしい話と困難さについては3番目のパートで話します。まず、過去10年間で観察したトレンドについて見てみたいと思います。
次に、共有されたファインチューニング作業や様々な論文で見られるパフォーマンスの観察結果について話します。そして最後に、その難しさについて話します。
まず、トレンドについてです。機械学習で大きな影響を与える最良の方法は、クールに聞こえるものを恐れることだと思います。私のキャリアを通じて、クールなことをするべきだと思われるものがあったとき、実際にそれをやると、それは実体のないものだったり、本当は退屈なことをするべきだったということがよくありました。
つまり、例えば2009年頃、人々は「ああ、機械学習が応用分野として大きくなってきた。モデルをトレーニングしたい」と言っていました。しかし、実際に価値を提供するには、データアナリストやデータサイエンティストが優れたSQLクエリを書くことが必要でした。当時の人々にはそれほどクールには聞こえなかったかもしれませんが、そこに時間を費やすべきだったのです。
多くの場所で、これは今でも当てはまります。2012年に話を進めると、ディープラーニング革命があり、2012年はまだ早かったかもしれませんが、2014年くらいには、みんなディープラーニングを使いたがっていました。例えば、ランダムフォレストを使って不正検出をしていたスタートアップが「さあ、今こそディープラーニングを使う時だ」と言っていました。実際にはそれは早すぎました。その当時、ディープラーニングモデルを機能させるのは非常に難しかったのです。XGBoostを使うべきでした。退屈なことをするべきだったのです。
2015年になると、ディープラーニングが本格的に始まり、多くの論文が出てきました。指数関数的な成長が始まりました。きっと新しい損失関数を発明したり、オプティマイザーの理論を改善したりしたいと思うでしょう。しかし実際に、モデルを改善したいなら、データセットをクリーニングし、明らかなエラーに気づいて修正するだけで、10分の1の労力で10倍大きな改善が得られるでしょう。
そして2023年の現在、同様のことが独自の基盤モデルのトレーニングや、場合によってはファインチューニングにも言えると思います。非常に魅力的に聞こえます。とてもクールに聞こえますが、私が見る限り、実際にはそれが最初に手を伸ばすべきものであったり、最も有用なものであることはまれです。
だから、先入観に基づいて、ファインチューニングを疑うべきだと思います。なぜならそれが最もクールに聞こえるからです。そしてすぐに、それが最もクールなことだと気づいたら、おそらく私の時間の最悪の使い方になるでしょう。
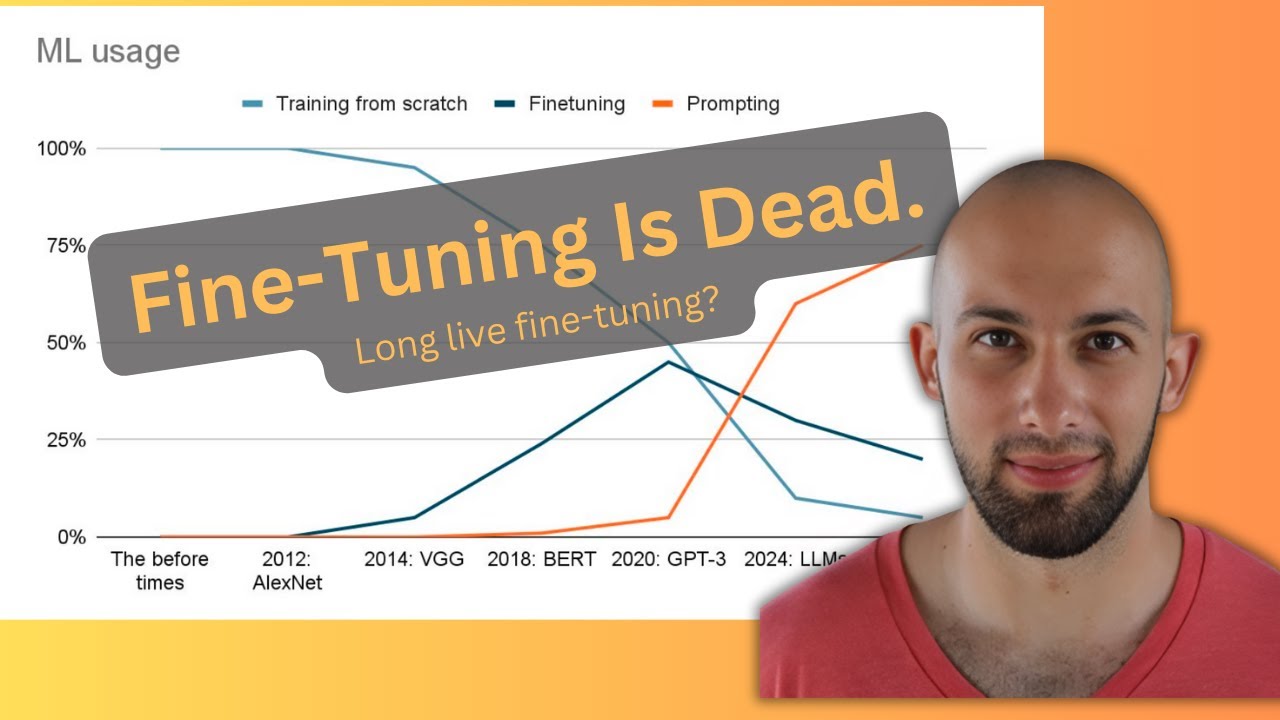
小さなグラフを作りました。これが同じことを示していると思います。これについてはすでに話しました。小さなグラフを作りました。この美しく描かれたグラフは、実用的な方法で機械学習を行う場合の、時間を最も有効に活用する方法に関する私の見解です。
始めのころは、希望的に私のマウスが見えていると思いますが、人々はただモデルをトレーニングしていました。ファインチューニングはありませんでした。なぜなら、取り上げてファインチューニングするようなモデルがなかったからです。あるいは、少なくとも非常にまれでした。
そこで、ランダムフォレストや、SVMや、何でも良いのですが、MLPなどを自分でトレーニングしていました。それだけでした。そしてImageNetが登場したときではなく、その数年後にVGGが、そしてその後ResNetが登場したときに、ファインチューニングが出てきました。多くの人々がより注目し始めたのはその頃だと思います。
事前学習されたモデルを取り、これらの場合は画像モデルでしたが、事前学習されたモデルを取り、より小さなデータセットでより安価にファインチューニングし、ゼロから学習するよりも優れたものを得ることができました。そして時間が経つにつれ、それはより有用になっていきました。
BERTもまた大きな瞬間だったと思います。テキストに対してもファインチューニングが有用になり始めた時期です。BERTモデルや他のモデルをファインチューニングできるようになりました。
そこで、一般的なトレンドとして、モデルをトレーニングする人が少なくなり、ファインチューニングする人が増えていきました。そしてGPT-3の頃、少し後かもしれません。人々が本当に理解するのに時間がかかったからですが、データに対して逆伝播を全く行う必要がないという概念が生まれました。
つまり、モデルを取り上げて、おそらくそのまま機能するということです。これが、いわばLLMの元々の約束だと言えるでしょう。実際にトレーニングする必要はなく、文脈内で学習し、プロンプトを与えるだけで良いのです。
私はこのグラフが好きです。なぜなら、ファインチューニングが死んだかどうかはわかりません。それが一時的なものだったのか、このグラフが再び上昇するのかはわかりませんが、少なくともこのようなトレンドがあります。以前はトレーニングしか選択肢がなく、ある時点でトレーニングをファインチューニングに置き換えることができるようになり、そして今では全くトレーニングが必要ないアプリケーションの全く新しいカテゴリーがあります。
そこで疑問は、このトレンドをどう外挿するかということです。現実的で面白くない、ホットな意見ではない答えは、誰にもわからないということです。しかし、私のホットな意見は、線が上昇し続けるということです。
将来的に、オレンジの線が上昇し続けると思います。質問があれば、ここで少し一時停止しましょう。
半ば明らかなことを述べると、はい。スライドに戻って、やるべきでないことについて見てみましょう。はい。あなたがやるべきでないと言ったことの多くは、数年後にはやるべきことになっていました。例えば、MLモデルをトレーニングするなと言っていましたが、数年後には「はい、XGBoostを使うべきです」と言っています。
そして、ディープラーニングをするなと言っていましたが、その後のある時点で、それをすべきだと言っています。つまり、今ファインチューニングをするべきではないと言っているということは、数年後にはそれがホットな話題になり、価値があるものになるということではないでしょうか?
つまり、私は分かりません。そうかもしれません。これがすべてに当てはまるわけではないと思います。特に、新しい損失関数を発明することは、今でも10年近く経っても、やるべきことではありません。だから、それぞれ場合によると思います。
確かに、ディープラーニングのような新しいものが登場したとき、人々はそれをやりたがります。時には実際に有用なこともあれば、そうでないこともあります。そして、最初に登場したときに、それが新しい損失関数を発明するカテゴリーに入るのか、ディープラーニングを使うべきカテゴリーに入るのかを知るのは難しいです。
チャットからいくつか質問をさせてください。はい。サイモン・ウィリソンという人からの質問があります。LMのファインチューニングをしない理由は理解できますが、埋め込みモデルはどうでしょうか? 例えば、数千のブログ記事で埋め込みモデルをファインチューニングして、より質の高い意味検索を得ることは、比較的簡単に価値を得られるのでしょうか?
それは興味深いですね。私にとって、それはモデルをファインチューニングすることと似たような質問に感じます。これらのモデルがより良くなり続けていると信じるなら、そして我々が…
現在、LLMの改善に多くの焦点が当てられていて、埋め込みモデルにはそれほど注目が集まっていないと思います。比較的、埋め込みプロバイダーの分野にはそれほど活動がありません。しかし、それらが良くなると信じるなら、非常に一般的な埋め込みが上手く機能するようになると思います。
これが難しくなり、ファインチューニングが常に必要になるか、あるいは全く異なるパラダイムが必要になる可能性があるのは、あなたの会社がXS23という製品を持っていて、会社外の誰もそれについて知らないような場合です。そして、この製品に基づいて埋め込みだけで検索を構築したい場合です。
これには、ファインチューニングや埋め込み、あるいは組み合わせたものが必要かもしれません。実際、私が見てきた中で非常に上手く機能しているのは、RAGです。キーワード検索と埋め込み検索を組み合わせた方法です。
RAGと検索において、ドメイン固有の場合、多くの場合、人々が良いと考えるランキングや検索は非常に特殊になる可能性があります。埋め込みでそれをキャプチャするのは難しい場合があります。埋め込みがどれほど優れていても。だから、あなたはどう思いますか? はい、それが私が最も疑問に思う部分です。
はい、そうですね…ネタバレになるかもしれませんがトークの終わりに、ファインチューニングは死んだというのはホットな意見版だと思います。私が現実的に信じる可能性があるのは、ファインチューニングはAIの50%ではなく5%程度になるということです。
非常に特殊な検索で、これは後で話すことと関係しますが、これらのモデルが良くなるにつれて、文脈内で特定の検索を理解できるようになると想像できます。そのため、LLMに検索を駆動させ、文脈をよく理解しているので、一種のクエリ拡張を行うことができるでしょう。
純粋な埋め込みについては、まだわかりません。一部の検索では、常に埋め込みをファインチューニングする必要があるかもしれません。
プロンプトを改善することと、ファインチューニングの結果を比較するベンチマークやデータ比較はありますか? はい、いくつかあります。後ほどのトークで紹介します。実際、RAGとファインチューニングを比較したものがあります。これはプロンプトに少し似ています。プロンプトはRAGより少し悪いかもしれません。実際、それは場合によります。RAGと同程度かもしれません。次のセクションで共有する論文をいくつか調べてみました。
はい、わかりました。また、皆さんからの意見も歓迎します。この性能を比較する論文をお持ちの方がいれば教えてください。驚いたことに、そのような論文をあまり見つけられませんでした。正直に言うと、文献調査に多くの時間を費やしたわけではありません。15〜30分ほど、すでに知っていた論文に加えて、見つけられる論文を探しました。しかし、非常に有益だと感じるものはあまり見つかりませんでした。
これは、OpenAIフォーラムからの例だと思います。GPT-3のファインチューニングの例です。少なくとも私が見つけることができた中で、RAGとファインチューニングを比較した最初の例の一つです。そして、いくつかのケース、すべてではありませんが、多くのケースで起こることを示していると思います。
このケースでは、ベースモデルがあります。このファインチューニングは、最悪のシナリオだと思います。なぜなら、あまり改善が見られないからです。そして、コンテキスト注入があります。これは基本的にRAGだと思います。そして、様々な異なるモデルがあります。
時々、ファインチューニングがうまくいかないことがあります。
これについて質問があります。あなたが理解を助けてくれるかもしれません。ファインチューニング対RAGについて、このようなものをよく見かけます。そして、私は非常に混乱します。なぜなら、私のファインチューニングは常にRAGを含んでいるからです。RAGの例を含んでいます。ファインチューニング対RAGとは何を意味しているのでしょうか? それは対立するものではありません。両方を行うのです。
同意します。2枚のスライド後に答えてもよいでしょうか? はい。
はい、同意します。
わかりました。2枚のスライド後に、ファインチューニング、RAG、そして両方を含む比較があります。しかし、もう一つ言えることは、これも優先順位の問題だと思います。これが私のホットな意見である理由の一つです。
あなたの人生のこの時点で、ファインチューニングとRAGの選択肢があるとすれば、どちらがより難しく、どちらがより大きな効果をもたらすかを知ることが非常に重要だと思います。もちろん、常に両方を行うことができます。しかし、2つの選択肢がある場合、どちらがより効率的かを知りたいものです。
ああ、はい、それは理解できます。それにも同意します。RAGを先に行うべきですね。
はい、私はこれが…はい、とにかく、このトークの終わりには、我々は大部分の事柄について同意しているでしょう。しかし、いくつかの見解は持つ必要があります。これは…はい、ハメルが言っていたことです。
これは2枚のスライド後と言いましたが、基本的にあなたが尋ねていたことです。これは論文です…ここにリンクがあります。ファインチューニングとRAGを比較しています。比較的古いモデルについてのものです。次の論文にはより最近のモデルがあります。しかし、私が見る限り、そのトレンドは実際に維持されています。
これは読みにくいかもしれませんが、基本的にこれがベースラインです。何もしていません。これはRAGだけを行った場合です。これはファインチューニングだけを行った場合です。そしてこれはファインチューニングとRAGの両方を行った場合です。そしてここは無視してください。これはLoRAを使用するかどうか、完全なファインチューニングを行うかどうかです。そして、これは…覚えていません。これらは異なるプロンプト手法です。
あるいは、これはファインチューニングのデータセットです。質問と回答の形式でフォーマットされていますか? とにかく、これらのモデルすべてを見ると、増加のほとんどがRAGから来ていることがわかります。特に、これは大きなモデルでより顕著です。RAGで58を得て、ファインチューニングとRAGの組み合わせで61を得ています。そしてファインチューニングだけでは、はるかに少ない結果になります。
これは小さなモデルでは当てはまりません。ファインチューニングとRAGの組み合わせでかなり多くの改善が得られます。しかし、特にベースモデルと大きなモデルでこのトレンドを見ると、基本的にRAGからほぼすべての利益を得ています。技術的には、ファインチューニングを行えばより多くの利益が得られると言えますが、63.13から63.29への増加にすぎません。それに対して、6.7から63への10倍の増加があります。
ここで立ち止まる価値があると思います。なぜなら、これは実際に非常に混乱する…人々がこれにつまずくからです。私の考えでは、もしあなたのモデルがデータからのコンテキストを必要とするなら、常にRAGを行うべきです。すべての知識、すべての文書からの知識をファインチューニングしようとするべきではありません。モデルがそのすべてを記憶することを期待するべきではありません。そうですね、それは良いアイデアではありません。
だから、私の感覚では、はい、もしあなたのアプリケーションがRAGを使用できるなら、RAGを使用するべきです。はい、人々は混乱すると思います。このような論文を見ると、「ああ、RAGの2つの異なる方法を見つけた」とか、「ああ、多分…」と思うかもしれません。いいえ、選択肢はありません。RAGを使用しなければなりません。
そうですね、ほとんどの応用的な状況では…それを機能させるためには。これが、あなたがこのコースを行っている理由が良いと思う理由です。なぜなら、これは一般的な知識ではないと思うからです。特に、私が話した他の実践者たちの中には、知っている人もいれば、正しいと思う直感を持っている人もいます。ファインチューニングは本当に正しい解決策ではありません。もしあなたが何かを認識したいなら…それはほとんどの場合、そのためのものではありません。
そのため、ああ、このユースケースでは少し意味があるかもしれない、あのユースケースではもう少し意味があるかもしれないと言うことはできます。しかし、実際にはそれはあまり知られていないと思います。そのため、私がこの趣味の馬に乗っている理由の一つは、ほとんどの場合、ああ、私の問題は、このモデルが私たちのビジネスモデルについて知らないということですと言うためです。そして、はい、その解決策は通常、それをファインチューニングすることではありません。ただ、あなたのビジネスモデルがどこにあるかを教えるだけです。
なるほど、はい。私は…はい、これは似ています。RAGとファインチューニングを組み合わせた論文を見つけました。あまり詳しく説明しませんが、私が興味を持ったのは、モデルのサイズに関係があると思うからです。逸話的に、いくつかの論文や私が行っている様々な実験から、ファインチューニングは大きなモデルよりも小さなモデルでより有益である可能性があるようです。
そのため、この論文が小さなモデル、比較的小さなモデルでこれを行っていることが興味深いと思いました。そして、これは我々が話していることの別の例だと思います。このユースケースが何だったか覚えていません。ああ、知識のためだと思います。そのため、はい、知識のために、小さなモデルでさえ、RAGを使用しないでしょう。
このテーブルをどのように解釈しますか? 右端のFT RAG+RAGは、ファインチューニングとRAGを組み合わせると悪化するという意味ですか?
そのように解釈します。それは少し驚きですね。私の解釈では、これはノイズの範囲内です。ベース+ファインチューニングがかなり近い、あるいはここでは少し悪化していることから、これは単に…ベースモデルとファインチューニングがこの例ではあまり効果がなく、私はこれが少し低いことを過度に重視しないでしょう。基本的に、ファインチューニング+RAGはおそらくRAGと同程度の性能を示すでしょう。
論文を読まずにこれを見るのは興味深いです。なぜなら、どのタスクがスコアリングされているのかわからないからです。少なくとも私にはわかりません。そして、もし文章スタイルブックへの準拠を測定したいのであれば、RAGはそれほど効果がないかもしれません。文章スタイルとファインチューニングだけなら…そうですね。我々は任意のタスクを選んで、望む結果を得ることができます。しかし、問題は我々が何のタスクを最適化しているかということです。
その通りです。はい、これは素晴らしい指摘です。なぜなら、私がこれを行い、スライドを書いて悪魔のような笑いをしながら、ハハハ、RAGがファインチューニングに勝っている、などと言っていたときに、ファインチューニングがRAGに勝っている論文を探すべきだと思ったからです。そして、多くの例を見つけることはできませんでした。
多くの例は、Twitterのスレッドなどでしか見ていません。とにかく、これは主に、このワークショップの主催者や参加者の皆さんへの呼びかけです。あなたが話していたような、スタイルの例や、ファインチューニングがより適している例を示す良い論文をお持ちでしたら、ぜひ教えてください。
説明するのが難しいと思います。なぜなら、知識を追加することについて説明しようとしても、「ねえ、ファインチューニングは知識を追加するのに適していません」と言うと、その言葉は十分に細かくありません。知識を追加するとはどういう意味ですか? ある種の知識には意味があります。そして彼らは「どんな種類の知識ですか?」と聞きます。そして私は「ああ、わかりました」と言います。それは直感になります。しかし、その直感を完全に明確に表現したわけではありません。
そうですね、多分私の…スケーリングに影響されたホットな意見かもしれませんが、この直感や境界線は、モデルの世代ごとに変化すると思います。そのため、おそらく良い例は、話し方のスタイルを学ぶことはファインチューニングを必要とすると言えたかもしれません。知識ではなく、物事を言う方法がファインチューニングを必要とします。
しかし、より良いモデル、より最近のモデルは、2行のプロンプトからスタイルを学ぶことができます。古いモデルにはできません。それほど当てはまらなくなりましたが、まだ他のことでは意味がある場合もあります。知識とは何かという概念は、基本的にモデルの世代ごとに変化すると思います。
はい、それは理解できます。はい、私も同じ経験をしています。スタイルやコンテンツとして数えるかどうかさえ確信が持てないケースがたくさんあると思います。もし我々が…
製造業者のコピーから、XS32ウィジェットのメーカーについてファインチューニングを行った場合、「最高のウィジェットは」と書かれているところを常にXS32で埋めるようになるかもしれません。これは一種の知識です。XS32が素晴らしいウィジェットだという知識ですが、実際には肯定的な感情を表現するときに常にそのウィジェットについて言及するというスタイルでもあります。そのため、トーンと知識の区別が明確ではない場合があり、知識は実際にはあまり明確な抽象概念ではないかもしれません。
はい、そうですね。特に…これはこのプレゼンテーションの範囲をはるかに超えていますが、これらのモデルを解釈する初期の研究からでさえ、我々が議論しているような知識の概念が、モデルの実際の方法の中でスタイルの概念と別のものであるかどうかは明確ではありません。
多くの場合、そうではないと私は賭けます。そのため、ああ、このような…この注意ヘッドにあるものが知識で、他のものはそうではないというような、クリーンな分離がモデル自体にもないと思います。
最初の聴衆からの質問がありました。イアン、どうぞ。
はい、もちろん。こんにちは、このトークをありがとうございます。私の会社では、精密腫瘍学のために非常に複雑な知識ベースを構築しています。おそらく10万時間以上の時間をかけて、ゲノミクスとがんに関するものです。私の直感では、これらのキュレートされたルールを使用して、キュレーションの最初のドラフトを作成するのに適したファインチューニングされたモデルを作成できると思います。我々はガイドラインと臨床試験文書と呼ばれるものをキュレートしています。これはあなたのモデルに適合しますか? その説明に基づいて、どのようなアドバイスをいただけますか?
ああ、難しいですね。先ほど話していたことに戻りますが、このドメインの専門家ではない私には、これが知識対スタイルのスペクトルのどこに位置するかについて、あなたよりも悪い直感しか持ち合わせていません。
ここで一つの比較を挙げるとすれば、おそらく…実は次のスライドで話しますが、金融や農業などに特化したLLMをトレーニングしようとする試みがあります。そして、それらは短期的には現在のオープンモデルや利用可能なモデルを上回ることがよくあります。しかし、その後の例では、それらはしばしば次のより大きく、よりスマートなモデルに負けてしまいます。
だから、それは考慮すべき一つのことだと思います。例えば、Claude 3モデルやGPTモデルを取り、最も賢いものと最も愚かなものを比較し、ファインチューニングなしでどのように比較されるかを見ることで、次の世代が実際に十分に良くなる可能性があるかもしれません。
そして、ファインチューニングが役立つかどうか、そもそも必要かどうかを判断するために私がよく使う方法は、基本的にファインチューニングしたいものの形に近い例をプロンプトにたくさん追加することです。おそらく他の人もこの会議で言っていると思いますが、それによってモデルのパフォーマンスがどれだけ向上するかを見ることで、大規模なデータセットでファインチューニングした場合にどれだけ向上するかの手がかりを得ることができます。
特に、しばらくすると頭打ちになるのが見えた場合、私の意見では、ファインチューニングする必要はありません。
関連する質問があります。サイモン・ウィリソンからの質問です。ファインチューニングは知識を追加するのに効果がありますか? この質問はよく聞きます。この質問に答えるのが難しいのは、ある種の知識が世界モデルのようなものに内在しているからです。
例えば、これは間違っているかもしれませんが、地球の重力の物理定数のようなものを考えてみましょう。私の直感では、言語モデルはそれを記憶することに問題ありません。それを何度も見たことがあります。RAGでそれを取得したくありません。しかし、ハメルについての、私の人生についての、変化する事実のような、より具体的なことについては…
はい、それは理解できます。明らかにトレーニングされていないものについては、確かにRAGですが、私には強い直感がありますが、人々にどのように説明すればいいかわかりません…知識を追加することについて、何が…はい、直感的に理解しています。言語モデルに内部的に理解してほしい知識があります。世界の基本的なことや、そういったものですが、他のものは決して内部化することを期待しません。
そう、この側面をどのように説明すればいいのかわかりません。
はい、それも複雑です。なぜなら、私が知識を追加したいほとんどの場合、例えば、私がイチゴが好きだということをモデルに追加したいとします。そうすれば、私の名前を見たときに、ああ、そういえばエマニュエルはイチゴが好きだと知っているでしょう。
まず第一に、それはほとんど常にプロンプトで行うことができます。あるいは、RAGなどで行えます。私についての質問があるときに、何かを取得し、エマニュエルについての説明があり、彼はイチゴが好きだと書いてあります。そして、良い指示に従うモデルであれば、同じことを行うでしょう。
そこで問題は、もし私がこれを行うためにモデルの重みを変更するとしたら、どのようにそれを行うかということです。これは実際にはそれほど単純ではありません。なぜなら、単に「エマニュエルは何が好きですか?」「彼はイチゴが好きです」というようなプロンプトをたくさんファインチューニングしただけでは、愚かなモデルは、エマニュエルが何を好きかと尋ねられたときにしかイチゴが好きだと言わないでしょう。
しかし、多くの場合、ファインチューニングで望むのは、この情報を知り、他の文脈で関連する場合にそれを使用することです。そこで、ああ、私がファインチューニングしたいのは、例えば、我々はショッピングの推薦をするビジネスをしていて、エマニュエルがログインしたときに、彼がランダムな質問をしても、ああ、そういえば今週イチゴを買いましたか?というようなことを言うようにしたいのです。
そして、これらの特定のプロンプト、この特定の文脈でファインチューニングします。そこで私の疑問は、これを知識と呼び、モデルに知識を追加していると言えるのでしょうか? それとも、基本的に、与えたこれらの少数のプロンプトの狭い分布において、イチゴに言及する傾向が強くなるようにフィットさせているだけなのでしょうか?
これは根本的に、これらのモデルがどのように学習するかに関わっています。少なくとも私が知る限り、我々はまだ満足のいく答えを持っていません。しかし、多くのファインチューニングが、この特定の文脈、この特定の質問の形に対して、このことを言うという表面的なレベルに留まっていると私は確信しています。モデルにとって「学ぶ」ということが何を意味するのかわかりませんが、エマニュエルがイチゴが好きだということを学んだわけではありません。うまく説明できたでしょうか。
はい、理解できました。正解はないと思います。多くの場合、この問題に対する答えは、そしてこれが取り組むのが楽しい理由は、我々にはわからないということです。近いうちにわかることを願っています。はい。
いくつかの例があります…ああ、はい、どうぞ。
はい、どうぞ。他の質問をチェックしてください。
はい。
素晴らしい。知識に関して、はい、私が聞いた例の一つで、おそらくうまくいったと思われるのは…多言語モデルを取り上げて、英語以外の言語でそれほど高度にトレーニングされていないが、他の種類の非英語をある程度持っている場合、その言語を少し理解していますが、一般的に非英語言語の品質はかなり悪いです。
そこで、より高品質を得たい他の言語でさらに多くのファインチューニングを行うと、それがうまくいく傾向があります。それは新しい知識を与えているように見えますが、そうではありません…その言語をすでに少し知っていましたが、単に例が少なかったため、あまり上手ではありませんでした。これは意味があるケースかもしれませんか?
はい、それは興味深いですね。最初に思い浮かぶのは…我々が共有しているいくつかの解釈作業で、少なくとも大規模で有能なモデルが様々なものをどのように表現しているかを見ると、テーブルの概念や、例えばゴールデンゲートブリッジのような概念を、異なる言語で同じように表現します。これはモデルがよりスマートになるにつれて、ますます当てはまります。
そのため、それをより良くするためにファインチューニングすることは、他のタイプのファインチューニングよりも少し簡単かもしれません。なぜなら、すでにこれを見ており、すでに異なる言語を概念にマッピングすることを学んでいるからです。そのため、新しい言語のために完全には学習していない新しい概念を、英語で反射を行う同じモデルの部分にマッピングするために、非常に小さな変更が必要なだけかもしれません。
特定のことについては、そのように機能する可能性があると思います。ああ、すみません、どうぞ。
いいえ、いいえ、同様に、人々がソフトウェアプログラミングを行うのに適したファインチューニングされたコードモデルを作成する場合、本質的に同じようなことが起こっていると思いますか? それとも、それは異なることが起こっていると思いますか?
はい、ファインチューニングされたモデルには他の懸念もあります。何を望むかによって異なります。コード補完を望むなら…これは我々が話していたスタイルです。モデルに「こんにちは、私はClaudeです。コードについて教えましょう」と言ってほしくありません。現在書いている行を自動補完してほしいだけです。これは我々が話していたスタイルの議論です。
そして、コード言語には速度の懸念もあります。コードベースの知識については…それもRAGがとてもよく機能し、ファインチューニングが必要ないと思います。現在作業している内容の良いコンテキストを持つだけでもいいのです。
私は確信が持てません。これは私のホットな意見かもしれませんが、良いデータはないと思います。コードベース全体でファインチューニングすることが、コードベースの多くをコンテキストに入れることと比べて大きな利益をもたらすとは確信していません。
関連して付け加えると、GoogleのあるローンチとClaude 3のローンチの両方で、モデルが珍しい言語を知らない例が共有されました。そして、その言語の100ページをコンテキストに入れると、突然それができるようになります。ファインチューニングなしで。これを言及する理由は、これがファインチューニングに匹敵するという事実が非常に興味深いからです。
後でもう少し詳しく話しますが、なぜこれが非常に興味深いと思うかについて説明します。
はい、先に進みましょう。質問に適切に答えていない場合や他の質問がある場合は、遠慮なく中断してください。では、先に進みます。
はい、これは基本的にハメルが言っていたことです。ファインチューニングはドメイン知識の解決策ではありません。これは先ほど言及した別の論文です。これは農業に関する論文だと思います。GPT-4をファインチューニングすると61%のパフォーマンスが得られます。申し訳ありません、それを行ってRAGを行うと61%になります。RAGだけを行うと60%になります。
つまり、厳密に言えば、本当にその1%を気にするなら有用ですが、実際にはほとんどの改善はRAGから得られています。ここのエラーバーがどれくらい大きいかわかりません。しかし、これは私たちが言っていることを確認するものです。これは一種のドメイン知識の問題です。そのため、あまり有用ではないように感じます。
ファインチューニングにとって困難なもう一つのことは、特に最先端の場合、動く標的を狙っているということです。多くの研究所、Anthropicもその中の一つですが、継続的にモデルを改善する作業を行っています。この例はBloomberg GPTの例です。
ここで申し訳ありませんが、悪い図を使ってしまったことに気づきました。基本的に、Bloomberg GPTモデルは、当時のChatGPTやGPT-3よりも金融分析タスクで優れていると主張していました。彼らは独自のモデルを事前トレーニングしたので、これはファインチューニングではなく事前トレーニングです。このテーブルにはあまり示されていませんが、その後、おそらく6ヶ月後にGPT-4とChatGPTが登場し、基本的にすべての面で彼らのファインチューニングされたモデルよりもはるかに優れていました。
これについて質問があります。非常に興味深いですね。これを取り上げてくれてよかったです。まず、Bloombergの例では、彼らはこのモデルの事前トレーニングを大々的に宣伝しました。何百万ドルもかかったと言っていました。私の最初の反応は、なぜモデルを事前トレーニングしたのか、なぜモデルをファインチューニングしなかったのかということでした。それは別の質問です。
二つ目は、はい、これらのフロンティアモデル、あるいは何と呼ぶにしても、それらはより良くなっています。あなたが言うように、動く標的です。例えばClaudeのような、大規模モデルのファインチューニングパイプラインがあるとします。OpenAIに注目を集めたくないので、そのままにしておきます。良いファインチューニングパイプラインがあり、これらの大規模モデルをファインチューニングしている場合、最先端の技術と一緒に進化し続けることはできないのでしょうか?
ああ、新しいモデルが登場しました。それをファインチューニングしましょう。ファインチューニングを続けましょう。それらのAPIが公開されていると仮定して。はい、最も強力なモデルの場合、まだ公開されていないかもしれません。ただ、はい、気になります。
そうですね、質問は、常に最新のモデルを取り上げてファインチューニングできるかということだと思います。答えはイエスだと思います。ただし、明らかに、Bloomberg GPTの例を取ると、彼らは事前トレーニングを行いました。しかし、おそらく彼らの試みの全ポイントは、彼らが持っている大規模なデータセットだったのでしょう。そのため、ファインチューニングのコストはそれほど安くありません。なぜなら、おそらく主に彼らのデータセットでトレーニングしているからです。
そこで、新しいモデルが登場するたびにそれだけのお金を払いたいですか? それはしばしば、ああ、任意のモデルを取り、RAGといくつかのプロンプトを行うパイプラインがあれば、簡単にモデルを交換できます。しかし、再度ファインチューニングしなければならない場合、それはかなり重荷になります。
つまり、可能ですが、それはコストの問題です。そして、その点についてもう一つ言えば、より大きなモデルのファインチューニングは…そして私は興味があります。おそらくあなたはこの点についてより多くの経験があるでしょう。いくつかの論文を見つけようとしましたが、それはほとんど逸話的なものです。これらのモデルがただ良くなるにつれて、すべてのことでより良くなっているように見えます。
はい。そうですね。最も一般的な戦術は、最も強力なモデルによって生成されたデータを使用して、一段階下のより速いモデルをトレーニングすることです。そのラダーを上っていきます。新しいモデルが登場しました。はい、それを使いましょう。より良いデータを取得し、何でも。そしてもちろん、ギャップを分析しますが、通常はより速いモデルを得て、希望的に同様またはより良いパフォーマンスを得ます。
そうですね、コストを見る必要があります。おそらく何か…分析する必要があります。この演習に意味があるかどうか。
その通りです。多くのチーム、企業が、少なくとも私が見る限り、このようなことのコストを過小評価し、価値を過大評価していると思います。しかし、はい、確かにできます。
繰り返しますが、もっと多くの例があればいいのですが…私たちは言葉で話していますが、これを行って本当に小さなモデルをトレーニングし、それが実際により良く機能するという論文をあまり見たことがありません。
いくつかの評価では、明らかにそれに適合しているように見えるものがあります。一部の例では、モデルが一般化しません。そのため、論文には良いですが、実際に何か有用なことに使えるかどうかは私にはわかりません。しかし、はい、できます。この時点では、コストの問題だと思います。そして価値の問題です。完全に意味がある使用例もあります。
私の意見では、優先順位リストの下位にあるべき使用例もあります。私には…ああ、いいえ。はい、これは私たちが話していたことです。質問がなければ、これは基本的に私たちが話していたことで、難しさに飛び込みます。
はい、どうぞ。
これは、ハメル、あなたが同じグラフを作ったか、少なくともこれについて正確に話したことがあるように感じます。MLを行う場合、最適な時間の使い方は、ファインチューニングを行っている場合でも、ゼロからモデルをトレーニングしている場合でも、通常80%がデータ作業です。収集、ラベル付け、強化、クリーニング、より多くのデータの取得、どこが壊れているかを確認するなどです。
18%は一般的なエンジニアリングです。モデルをどのように提供するか、モデルをどのようにモニタリングするか、ドリフトがないことをどのように確認するか、そういったことすべてです。そして、おそらく2%がモデルのトレーニングが上手くいかない、GPUの問題などのデバッグです。そして、通常はクールなアーキテクチャ研究に0%の時間しかかけられません。
少なくとも、これが私の経験です。これを言及する理由は…機械学習は難しいと思います。モデルをトレーニングしない場合でも。実際にこれを信じて、ああ、ファインチューニングはしない、RAGとプロンプトの要素だけを使うとしても、基本的にこのすべてを行う必要があります。
おそらくこれをフィルタリングしますが、モデルコードは必要ありません。しかし、入力検証のセットアップ、フィルタリングロジックのセットアップ、出力検証のセットアップ、入力のモニタリング、レイテンシーのモニタリング、出力のモニタリング、プロンプトとRAGシステムのバックテスト、評価を行う必要があります。
トレーニングテストの分割を行い、実験、潜在的にはA/Bテストを行うなど、やるべきことがたくさんあります。おそらく、このホットな意見の合理的なバージョンは、ファインチューニングが死んだということではなく、私と話をすれば、これらすべてを先に行った場合にのみファインチューニングを許可するということです。
なぜなら、これらすべてがファインチューニングよりも必要性の階層で上位にあると思うからです。ちなみに、あなたは最近O’Reillyで素晴らしい記事を書いていましたね。基本的に同じことを述べていました。そのため、それほど物議を醸す意見ではないと思いますが、ファインチューニングで私の歯車を噛み合わせるのは、人々がこれらのことを何もせずに、評価さえ持っていない段階でモデルをファインチューニングすることです。それは問題だと思います。
はい、それは私も気に入りません。もし良ければ、1秒間前のスライドに戻っていただけますか? はい。これが意味をなすことを願っています。一つの質問は…
これらの数字はあまり敏感ではありません。いいえ、いいえ。しかし、それで大丈夫です。データセットの収集部分は…ファインチューニングをしない場合は必要ありません。しかし…
評価のためにいくらかできます。データの確認については? それはまだできます。データの確認…
私にとって、データの確認は80%まで占めます。クリーニングと確認は同じようなものです。ああ、その通りです。はい、これを私がフォーマットすべきだった方法ではないかもしれませんが、これは主に、ファインチューニングを行う際に非常に異なることを行うと考えた場合、そうではないということです。ただデータを見ることに大半の時間を費やすことになります。
両方の場合でそうだと思います。しかし、先ほど言及したように、失敗のモードは、人々がこれをしたくないと思い、代わりにファインチューニングのサイドクエストに行くことです。すべてのファインチューニングを行う人がそうではありません。わかりました。
つまり、何をしていても、この80%は変わらないということですね。その通りです。ファインチューニングに直接飛び込むのは、さらに危険です。
はい、はい、その通りです。最悪なのは、これをしたくないと思い、代わりに見もしないランダムなデータセットでファインチューニングを行うことです。私はそれを見てきましたし、それがうまくいかないのを見てきました。
理解できました。そうですね。基本的に、ほとんどの時間をこれらすべてに費やすべきだと思います。そして、これらすべてを持っている場合にのみ、意味があると思います。基本的に私の考え方は、これらはすべて実際に機能するMLシステムを持つために必要なものだということです。
そのため、最初のモデルをトレーニングする前に、ファインチューニングを行うためのインフラストラクチャを持つべきです。これらすべてを行った後に、ファインチューニングを検討できます。その前は、ある意味で…
基本的に同じことです。私が最初に行うことは、常に友人や話をする人々に勧めているのですが、まず評価セットを作ることです。代表的な評価セット、大規模な評価セットです。評価セットは実行が簡単です。
数日間プロンプトに取り組むことは、もはや数えきれないほどの回数、誰かに「プロンプトについてよく考えましたか?」と尋ねたことがあります。彼らは「ああ、はい、とても頑張りました」と言います。そして、私がそれを見ると、2時間で30%から98%の精度に上げることができます。
私は天才ではありません。ただ実際に時間をかけて、プロンプトを明確にし、良いプロンプトガイドに従うだけです。ここではあまり詳しく話しませんが、質問があれば話し合うことができます。
はい。ここで一つの観察が非常に興味深いのは、最初と最後の箇条書きは、古典的なMLでも時間を費やすべき同じことだということです。
はい。そのため、本当に興味深いのは、あまり変わっていないように感じるということです。
全くその通りです。これは何年も繰り返してきたのと同じメッセージです。しかし、はい、あまり変わっていませんが、ある種の語りがあります。「ヘイ、これは新しい職業のAIエンジニアリングだ。必ずしもMLをする必要はないし、MLについて考える必要もない」というようなものです。はい、あなたはそれについてどう思いますか?
ああ、私の考えはこうです。常にそうだったのですが、時間をこれに費やすべきであって、いわゆる数学的な部分にではありません。そして今や、多くの場合、数学がAPIの形で抽象化されているため、さらに明確になっています。モデルのAPIプロバイダーを使用する場合などです。
そのため、興味深い問題に興味を持つ人々、私自身も理解し持っている誘惑ですが、「いいえ、楽しいML作業に戻りたい」という強い誘惑があります。そして、もしそれがファインチューニングの理由なら、それは悪いことです。
しかし、あなたが話していたように、機械学習の実際の作業をすべて行い、これらすべてを行った後、「ああ、この重要なことでさらなるパフォーマンスを得る唯一の方法はファインチューニングだ」、あるいは「より低価格や低レイテンシーを得るには」と気づいた場合、それは理にかなっています。しかし、基本的には、これは…
常にそうだったものと同じですが、楽しいことの重力の引力がさらに強くなっています。「何? Jupyterノートブックさえ見られないのか。APIコールだけ? それは楽しくない」というようなものです。
はい。最後に言いたいことは実際に非常に重要です。最後の行に残しておきました。トレンドを見て、基本的にそれらを外挿し、トレンドラインが続くか、それとも壊れるかを決定することです。繰り返しますが、本当の答えは誰にもわかりませんが、モデルの価格やコンテキストサイズのトレンドを見るだけでも…
これは、ほぼ同等のモデルの価格です。同等ではありません。なぜならモデルは良くなっていますが、これは2021年のClaude Haiku / GPT-3.5レベルのモデルの価格です。しかし、今日のClaude Haikuは2021年のものよりも確実に優れています。そのため、実際にはさらに安くなっています。
価格は2021年の1メガトークンあたり約60ドルから、現在は混合価格で0.5ドル程度になっています。そして、コンテキストサイズは、最初は2kだったと思います。たぶん4kでした。そして今では200k、100万、150万、1000万という話も聞きました。
これらのトレンドラインが両方とも止まる可能性はありますが、もし止まらなかったらどうなるかを考えることが重要だと思います。ここに描かれていないものの一つはレイテンシーで、これも同じように減少しています。モデルはどんどん速くなっています。
ああ、2025年か2026年に、1億のコンテキスト、クレイジーなレイテンシーを持つモデルがあり、仮に続けば、さらに10倍か100倍安くなるとしたら…ファインチューニングをせず、すべてをコンテキストに入れ、これらのモデルはコンテキストから学習するのが驚くほど上手く、もし速くなれば…すぐに応答を得られます。
そのため、非常に興味深い質問があります。明らかに、どの指数関数や直線でも永遠に外挿することはできません。常に停止するポイントがあります。そのため、基本的に知能あたりの価格プラスレイテンシー(これは私の意見では非常に重要です)のこの線が停止するタイミングによって、ファインチューニングのどのようなユースケースを考慮すべきかが決まります。
コンテキストウィンドウの制限をはるかに超えているもの、あるいは増加し続けるこれらの速度でそのコンテキストをチャンクすることがアプリケーションにとって時間がかかりすぎるものを考慮すべきです。そして、プレフィックスキャッシングが始まっています。
その通りです。あなたも知っているように、Anthropicがそれを提供するかもしれません。それは大丈夫です。はい、これはエマニュエルのトークであり、Anthropicのトークではありません。しかし、はい、プレフィックスキャッシングのようなものが、少なくとも数年後には一般的になると私は想定しています。
そしてもしそうなら、ファインチューニングしたデータセットをほとんどの場合プレフィックスとして簡単に定式化できると想像できるなら、はい、それはその方程式をさらに変えます。そのため、私は…
正直なところ、これが最後にこのチャートを持ってきた理由だと思います。なぜなら、これが議論を始めたものだと思うからです。私がファインチューニングがそれほど必要ではなくなるだろうと最も楽観的に考える理由は、このチャートです。それは我々が向かっている方向性です。
これと、先ほど示した美しいプロンプティングの成長チャートを組み合わせると、非常に興味深いトレンドになります。そしてもし1年か2年さらに続けば、多くのアプリケーションでファインチューニングの必要性がなくなると思います。
はい。Lorianneからの質問があります。トークンを節約する必要がある場合、特にfew-shotの例を置き換えるためにファインチューニングを行うことができます。その答えは知っていますが、関連する質問として、私はHarrisonとよく話をします。LangchainのHarrisonです。「ああ、人々は何か面白いことをしていますか?」と聞くと、彼は多くの人々が動的なfew-shot例を行っていると言います。
RAGについて考えてください。few-shot例のデータベースがあり、最も関連性の高いものを取り出しているのです。彼はそれがとてもうまくいくと言っています。あなたが話をする人々は、それを行っていますか? それは一般的ですか?
はい、これの多くの例を見てきました。これは一般的です。なぜなら、多くの場合、few-shot例が扱いにくくなるからです。均等に分布させたいからです。モデルが10のことを行える複雑なユースケースがある場合、10のそれぞれについて1つの例と、モデルがそれを1つの方法で行う例と別の方法で行う例が必要かもしれません。
そのため、可能ですが、コンテキストウィンドウをすぐに超えてしまう可能性があります。そのため、関連する例を取得することは非常にうまく機能し、かなり一般的です。私の必要性の階層では、我々が話したすべてのことがあり、その後にプロンプトに本当に取り組むことがあります。
昨日か何かにツイートしましたが、10人目の人に同じループで助けを与えたからです。プロンプトに取り組み、うまくいかない例を見つけ、それらをプロンプトの例として追加するか、条件付きで取得して追加できるものとして追加し、これを10回ほど行います。
そしてその後にのみ、他のことを考慮します。それはとてもうまく機能する傾向があります。
素晴らしい。はい、私を招いてくれてありがとうございます。皆さんにとって興味深いものだったことを願っています。
非常に興味深かったです。はい。
素晴らしい。ありがとうございました。皆さん、さようなら。


コメント